Vidar: Embodied Video Diffusion Model for Generalist Manipulation
1. Quick overview of the paper
| What should the paper solve? | On the new robot platform, dual-arm operation requires a large amount of demonstration data bound to the hardware; the differences in action spaces, perspectives, and shapes of different robots make cross-platform migration difficult. The paper wants to answer: Can the video dynamic knowledge on the Internet and robot data be turned into a transferable prior, so that an unseen two-arm platform can perform multi-task operations in only about 20 minutes of demonstration? |
|---|---|
| The author's approach | Break down the strategy into two steps: first use the video diffusion model to generate a multi-view video rollout of "what should happen next", and then use the Masked Inverse Dynamics Model, MIDM, to convert the video frames into target robot actions. The key points are the unified observation space, embodied pre-training of 750K multi-view dual-arm video, a small amount of full-parameter fine-tuning of the target platform, multi-sampling rearrangement during testing, and action-related area masks without pixel annotation. |
| most important results | In the RoboTwin 2.0 multi-tasking setting, Vidar achieved an average success rate of 60.0% in the low data clean scenario, compared to 25.0% for Pi0.5; 65.8% for standard clean and 44.8% for Pi0.5. On a real platform, with only about 20 minutes and 232 episodes of human demonstration, Vidar achieved 68.2%, 66.7%, and 55.6% on seen tasks/backgrounds, unseen tasks, and unseen backgrounds respectively, significantly higher than UniPi and VPP. |
| Things to note when reading | The focus of this paper is not just "making videos look good", but whether the videos are action-aware enough. We should pay special attention to three aspects: whether the unified observation space really alleviates the embodiment gap; whether MIDM's mask is only effective on real platform distribution; TTS relies on GPT-4o rearrangement and cloud video model, which brings delay, cost and lack of closed-loop control. Another boundary is that the author relies heavily on multiple perspectives to see the arms and contact areas. |
2. Motivation and problem definition
2.1 Why not directly train the VLA policy?
The author believes that the difficulty of dual-arm operation comes from three coupled factors: the expansion of the action space with the number of joints, the need for precise time coordination between the arms, and contact dynamics and long-term planning that are sensitive to data quality. Although the VLA model can connect vision, language and action end-to-end, the action space is highly dependent on the robot form, and it is difficult to directly migrate the action labels of one platform to another platform when cross-platform.
Therefore, Vidar chooses to bypass the heterogeneity of the action space: the video diffusion model only learns how the world evolves, and does not directly learn actions; actions are only decoded by a lightweight inverse dynamics model on the target platform. This is the basic position of the paper: video is an intermediate modality between Internet data, robot data, and target platform demonstrations.
2.2 Formalization issues
The original goal is to learn conditional action strategies:
Among them, $\mathcal{L}$ is the language instruction space, $\mathcal{O}$ is the observation space, and $\mathcal{A}$ is the action space. The author decomposes it into a video generation model $G$ and an inverse dynamics model $I$:
This means that most of the cross-task and cross-scenario knowledge is undertaken by $G$; the action mapping related to the target robot is undertaken by $I$. When reading this paper, keep asking: does the video space really retain enough motion information? If certain joints or contact points are out of view, the $I$ cannot reliably resume motion.
2.3 Contribution positioning
- It is proposed to use a large-scale video diffusion model as a transferable prior for dual-arm operation, and adapt the Internet video prior to the robot video domain through embodied pre-training.
- A unified observation space is proposed to splice robot type, camera layout, task language and multi-view frames into a unified input format to reduce the differences in perspective and form of multi-platform data.
- MIDM is proposed to use a mask without pixel-level supervision to allow the inverse dynamics model to focus on the arm, tool and contact area, thereby improving the generalization of action decoding under background changes.
- Low-sample adaptation is demonstrated on RoboTwin and a real Aloha dual-arm platform, with particular emphasis on the real platform, which only takes about 20 minutes to demonstrate.
4. Detailed explanation of method
4.1 Three-stage training pipeline
Vidar's training is divided into three layers of data from large to small:
- Internet-scale video pre-training: Directly adopt existing video model checkpoints, such as Wan2.2, Vidu 2.0, and HunyuanVideo, to obtain semantic, motion, and physical interaction priors.
- embodied domain pre-training: Continue pre-training with about 750K multi-view dual-arm robot episodes to adapt the video model to the robot, camera and operating dynamics.
- Target platform fine-tuning: Perform full-parameter SFT with a small number of demonstrations on the target robot, while training MIDM to map video frames to actions.
4.2 Video generation model: rectified flow
The authors adopt a video diffusion model in the form of rectified flow. The model learns the velocity field $v(x_t, t, c)$, flowing from Gaussian noise $x_0$ to the target video $x_1$:
During training, let the velocity field approximate the constant flow from $x_0$ to $x_1$:
The $c$ here is not just the task text, but the robot, camera, task and multi-view image context in the unified observation space. This choice is what sets Vidar apart from ordinary text-to-video control methods.
4.3 Unified observation space
The unified observation space is defined as:
Among them, $\mathbf{o}$ is a multi-view image aggregation, and $l_r, l_c, l_t$ describes the robot platform, camera configuration and task instructions respectively. For different data sets, the author gives text descriptions similar to "fixed high camera, movable left arm camera, movable right arm camera" as part of the conditions.
The advantage of this step is that the model does not need to unify the action space. It only needs to cast the videos of different robot platforms into the same "multi-view image plus description" format. But this also brings an implicit requirement: the camera description must be stable enough and the perspective must cover the action-related area.
4.4 embodied pre-training and target platform fine-tuning
The pre-training data comes from Agibot-World, RoboMind, and RDT. The data size corresponding to the real experiment is 746, 533 episodes; Egodex is additionally added to the simulation experiment. The authors filtered out episodes with less than three views or shorter than four seconds, and used Agibot's frame-level annotation to cut long episodes into short clips. Sampling is done in proportion to the size of the data set during pre-training.
Data from the target platform are used both for the fine-tune video diffusion model and for training MIDM. The real platform data is a 20-minute human demonstration, covering 81 tasks and 232 episodes; the simulation low data is set to 20 episodes per task for RoboTwin, and the standard is set to 50 episodes per task.
4.5 Test-Time Scaling
The sampling of the video diffusion model is random, and a single rollout may be physically inconsistent or task mismatched. Vidar generates $K$ candidate videos during inference:
Then use evaluator $q_\eta$ to select the highest scoring video:
In the real experiment, $K=3$, three videos were generated in parallel, and then rearranged by GPT-4o based on physical rationality and task text consistency; in the simulation experiment, TTS was turned off for reproducibility, that is, $K=1$. The appendix notes that each pairwise comparison costs about $0.003, and GPT-4o rearrangement accounts for about 25% of the total delay at $K=3$.
4.6 Masked Inverse Dynamics Model
MIDM contains two networks: mask prediction network $U$ and action regression network $R$. Given frame $x$, first predict the spatial mask:
The training loss is:
Among them, $l$ is Huber loss, $\lambda\|m\|_1$ encourages mask sparseness, and Round is trained by straight-through estimator. The intuition is: if the model must predict actions with as few pixels as possible, it will tend to retain arms, grippers, tools, and contact points, and filter out background and reflection interference.
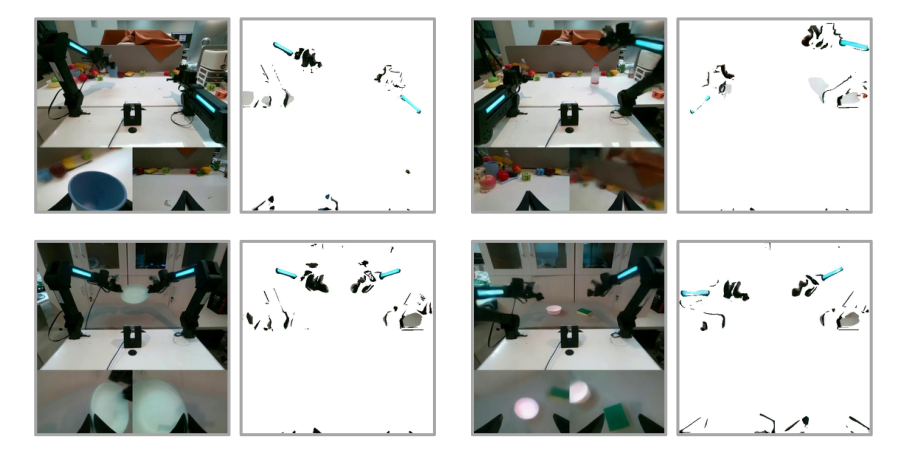
4.7 Why not use ready-made segmentation models
Appendix tests RoboEngine segmentation. The author points out that it often only recognizes one arm in dual-arm scenes, is unstable from the wrist perspective, and lacks temporal consistency. Vidar therefore does not rely on external segmentation labels, but instead lets action supervision shape the mask inversely.

5. Experiments and results
5.1 Experimental hypothesis
- Vidar also achieves a higher success rate with only 20 minutes of target domain demonstration.
- Vidar can generalize to unseen tasks and unseen contexts.
- Embodied pre-training on a unified observation space can improve video generation quality.
- MIDM generalizes better than the ordinary ResNet inverse dynamics model.
5.2 Data and training settings
| Project | settings |
|---|---|
| Pre-training data | Agibot-World, RoboMind, RDT; real experiments total 746, 533 episodes; simulation experiments additionally add Egodex. |
| Target real platform data | 20 minutes of human demonstration, 81 tasks, 232 episodes; target platform not seen in pre-training. |
| Simulation data | RoboTwin 2.0; low data is 20 episodes per task and the camera is adjusted to fully see the arm; standard is 50 episodes per task and official perspective. |
| video model | The simulation uses Wan2.2; the real main experiment uses Vidu 2.0; the appendix also reproduces Wan2.2 and HunyuanVideo. |
| Number of training steps | Wan2.2: 10K pre-training + 12K fine-tuning; Vidu 2.0: 10K pre-training + 13K fine-tuning; video downsampling to 8 fps. |
| MIDM | U-Net mask predictor + ResNet-50 action regressor; $\lambda=3\times10^{-3}$; trained with fine-tuning dataset only. |
5.3 RoboTwin 2.0 Main Results
The RoboTwin results use a more difficult multi-task setup: instead of training a policy individually for each task, it is evaluated evenly across 50 tasks, with 100 episodes each. Pi0* in the table is the official leaderboard result. Because each task is trained independently, the author's explanation is easier and not completely comparable.
| method | Low Clean | Low Randomized | Standard Clean | Standard Randomized |
|---|---|---|---|---|
| Pi0* | - | - | 46.42% | 16.34% |
| Pi0.5 | 25.0% | 9.2% | 44.8% | 14.2% |
| Vidar | 60.0% | 15.7% | 65.8% | 17.5% |
Key interpretation: Vidar improves the most in the clean scene, indicating that video priors and multi-view conditions are very helpful for task execution; the improvement in the randomized scene is smaller, indicating that background and object randomization are still bottlenecks, but Vidar still exceeds Pi0.5.
5.4 Real robot main results
Real experiments are divided into three categories: seen tasks/backgrounds, unseen tasks, and unseen backgrounds. UniPi and VPP were selected as baselines because the author believes that it is difficult for conventional VLA to effectively adapt when there are only 20 minutes of data.
| method | Seen Tasks & Backgrounds | Unseen Tasks | Unseen Backgrounds |
|---|---|---|---|
| VPP | 4.5% | 13.3% | 0.0% |
| UniPi | 36.4% | 6.7% | 22.2% |
| Vidar | 68.2% | 66.7% | 55.6% |
The strongest evidence here is that unseen tasks are still 66.7%, indicating that the video model not only remembers the demonstration tasks, but can also use language and video priors to process semantic tasks, such as grabbing the shortest piece of bread, wiping the table with a rag, etc. unseen backgrounds dropped to 55.6%, but still significantly higher than UniPi and VPP.

5.5 Video quality gains of embodied pre-training
| Configuration | Subject Consistency | Background Consistency | Imaging Quality |
|---|---|---|---|
| Vidu 2.0 | 0.565 | 0.800 | 0.345 |
| + Embodied Pre-training | 0.855 | 0.909 | 0.667 |
VBench indicators show that robot video pre-training significantly improves subject consistency, background consistency and imaging quality. For robot control, subject consistency is not a purely visual aesthetic indicator. It is related to whether the arm, object and contact relationships remain stable throughout the rollout.
5.6 MIDM generalization results
| inverse dynamics model | Training Accuracy | Testing Accuracy | Testing $l_1$ Error |
|---|---|---|---|
| ResNet | 99.9% | 24.3% | 0.0430 |
| MIDM | 99.9% | 49.0% | 0.0308 |
Both scores are almost full on the training set, but the success rate of MIDM on the test set is doubled, indicating that ResNet is more likely to take advantage of background or texture shortcuts, and MIDM's sparse mask regularization helps draw attention back to action-related areas.
5.7 Ablation experiment
| Configuration | Seen Tasks & Backgrounds | Unseen Tasks | Unseen Backgrounds |
|---|---|---|---|
| Vidar w/o TTS | 45.5% | 33.3% | 44.4% |
| Vidar w/o MIDM | 59.1% | 26.7% | 22.2% |
| Vidar | 68.2% | 66.7% | 55.6% |
TTS improves unseen tasks significantly, from 33.3% to 66.7%; MIDM is especially critical for unseen background, from 22.2% to 55.6%. This is consistent with the narrative of the paper: TTS mainly filters out videos that do not match the task or are physically unreasonable, and MIDM mainly resists background interference.
5.8 Supplementary results in Appendix
$\lambda$ for MIDM
$\lambda=3\times10^{-3}$ best: testing accuracy 49.0%, testing $l_1$ error 0.0308. If $\lambda=10^{-1}$ is too large, the mask will be too sparse, and the test accuracy is only 7.1%; if $\lambda=10^{-4}$ is too small, the constraints will be insufficient, and the test accuracy will be 24.4%.
Wan2.2 additional real experiments
On 14 real tasks, Vidar-Wan2.2's seen cases average 69.3%, Pi0.5 is 34.3%; unseen cases average 67.1%, Pi0.5 is 12.9%. This support method is not fully bound to Vidu 2.0.
HunyuanVideo Additional Experiments
The average success rate of the six tasks was 58.3%, including 100% for grabbing apples and placing them in the steamer, 25% for grabbing cup handles, and 20% for stacking blocks. It shows that it is feasible to replace the backbone, but the differences between different tasks are still large.
Failure case
Additional visualizations in the appendix contain success and failure cases. Report readers should pay attention to whether the failure results from unreasonable video prediction, incorrect TTS selection, failed MIDM action decoding, or accumulation of open-loop execution errors.

6. reproducibility Key Points
6.1 Data processing
- Convert each data set episode into a unified multi-view image layout; the wrist or perspectives with less information will be resized and then spliced.
- Add robot, camera and task description to each piece of data to form $l_r, l_c, l_t$.
- Filter data with less than three views or shorter than four seconds; Agibot uses frame-level annotation to segment short clips.
- RoboTwin low data specially adjusts the camera to make both arms fully visible to facilitate MIDM learning movements.
6.2 Training resources
| module | Resources and training |
|---|---|
| Vidu 2.0 | 64 NVIDIA Ampere 80GB GPUs, 23, 000 iterations, about 64 hours; 10, 000 pre-training, the rest fine-tuning. |
| Wan2.2 | 5B parameters; pre-train lr $2\times10^{-5}$, fine-tune lr $2\times10^{-5}$, warm-up 200, pre-training 10K, fine-tuning 12K. |
| HunyuanVideo | 13B parameters; 64 NVIDIA Hopper 80GB GPU, about 54 hours; pre-training 10K, fine-tuning 2K. |
| MIDM | 92M parameters; 8 NVIDIA Hopper 80GB GPUs, 60, 000 iterations, about 5 hours. |
6.3 MIDM hyperparameters
| hyperparameters | value |
|---|---|
| Mask network | U-Net, 5 layers down/up sampling |
| Action network | ResNet-50 |
| Loss | Huber loss + $\lambda\|m\|_1$ |
| Learning rate | $5\times10^{-4}$ |
| Warm-up | 6000 steps |
| AdamW | $\beta=(0.9, 0.999)$, $\epsilon=10^{-8}$, weight decay $10^{-2}$ |
| Mask sparsity | $\lambda=3\times10^{-3}$ |
6.4 Reasoning process
- Enter the current multi-view and task text.
- The video model generates 60 frames, 8 fps, or 7.5 seconds of future video at one time.
- The real experiment generates $K=3$ candidates, and extracts 5 to 7 frames and gives them to GPT-4o for sorting according to the task and physical rationality.
- When a video is selected, MIDM runs locally and converts video frames into action sequences.
- The execution is open-loop, and no re-planning is performed based on observations during execution after generation.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable part is that it provides a very clear cross-embodiment transfer split: do not forcefully unify the action space, but first unify the video observation space, let the large video model learn the operating dynamics across robots and cross-views, and then use a small amount of action data from the target platform to train the inverse dynamics adapter. This idea compresses expensive robot action supervision to the last step, which is very consistent with the current paradigm of "learn universal priors first, and then align them at low cost" in the current era of large models.
The second value point is that the design of MIDM is very simple but it captures the pain points in the generalization of real robots: changes in background, reflection, and perspective will make overfitting shortcuts from ordinary images to action models, while action supervision plus sparse masks can force the model to focus on arms and contact areas without segmentation labels.
7.2 Why the results hold up
- The main result is not a single scene: RoboTwin simulation, real seen task, real unseen task and real unseen background are covered simultaneously.
- There are strong baselines Pi0.5, UniPi, VPP, and the author explains the comparability issues of Pi0 leaderboard with multitasking setups.
- Ablation directly corresponds to the method components: w/o TTS and w/o MIDM verifying the contribution of inferred rearrangement and masked inverse dynamics respectively.
- The appendix provides a task-by-task table, not just averages; you can see the differences in many tasks, such as handover, hanging mugs, putting bottles, etc. are still difficult.
- VBench and MIDM training/test comparisons provide mechanism evidence: embedded pre-training improves video consistency, and MIDM improves test action prediction rather than just training fit.
7.3 Main limitations
- Strong reliance on observability: The Appendix Hardware section clearly states that the intermediate video must contain the information required for action prediction. In Aloha's original perspective, the arm joints were often out of view, so the author adjusted the center camera. Many commercial platforms may not be able to arrange cameras in this way.
- Open loop execution: In the real experiment, the video is generated once and the action is executed once, which is not a closed-loop visual feedback control. In long-term tasks or disturbance scenarios, errors may accumulate.
- High inference latency: A 60-frame video takes about 25 seconds to generate, and TTS requires additional GPT-4o sorting. The authors also acknowledge the need to distill or quantify cost reductions.
- TTS relies on external evaluator: GPT-4o sorting can improve results, but the bias, cost and reproducibility stability of the evaluator need to be additionally considered.
- The scale of real experiments is still limited: 81 tasks and 232 episodes are very convincing, but it is still not large enough compared to deployment-level generalization. In particular, the failure types of complex contact tasks with both arms need more systematic analysis.
- Video actionability is not fully guaranteed: Diffused video may look reasonable but is not dynamically executable. MIDM can only convert the selected video into an action, but there is no guarantee that the action will complete the task.
7. 4 Boundary conditions
| Applicable conditions | Conditions that do not apply or require caution |
|---|---|
| There are multi-view RGB videos, and most of the arms, grippers, and contact objects are visible. | The key states are outside the image, such as joint angles, forces, and occluded contact points, and the action cannot be reversed from the video. |
| Tasks allow inference latencies of seconds or more and can be executed in an open-loop for a period of time. | High-speed dynamics, real-time obstacle avoidance, and strong human-computer interaction safety constraints. |
| The target platform can take a small number of high-quality demonstrations and train MIDM with the same camera layout. | The camera layout changes frequently or the demonstration actions are noisy. |
| Semantically explicit, visually discriminable video tasks. | Fine assembly tasks requiring force control, haptics, or latent state reasoning. |
8. Preparation for group meeting Q&A
Q1: What is the biggest difference between Vidar and UniPi?
UniPi also uses video as an intermediate planning representation, but Vidar emphasizes large-scale embodied video pre-training, unified multi-view observation space, and MIDM action decoding on the target platform. In real experiments, UniPi directly fine-tune Vidu 2.0 and uses ResNet IDM, which lacks heterogeneous robot video pre-training and mask mechanisms.
Q2: Why doesn't the video model directly output actions?
The author wants to avoid the embodiment gap caused by action space heterogeneity. Different robots have different joints, grippers, and control frequencies, so it is difficult to directly unify the actions; the video space is more versatile and can carry semantic and physical interactions, and then a lightweight inverse dynamics model is trained on each target platform.
Q3: Why does MIDM mask not need to split labels?
Because supervision comes from action prediction errors. If certain pixels are useful for action prediction, retaining them will reduce Huber loss; at the same time, $\ell_1$ regularization requires the mask to be as small as possible, and the model tends to retain only action-related areas. Round is trained with a straight-through estimator.
Q4: What are the functions and costs of TTS?
The function is to reduce the variance of diffusion sampling and select videos with more reasonable physics and better matching tasks from multiple candidates. The cost is multiple video generation and GPT-4o sorting. In the real experiment $K=3$, sorting accounts for about 25% of the total delay and introduces external model dependencies.
Q5: What is the point that is most likely to be questioned?
The first is reproducibility: Vidu 2.0 and GPT-4o sorting are not completely open source and controllable. The second is open loop control and high latency. The third is to adjust the camera so that the target platform can fully see both arms. This is critical to the method, but it may not always be satisfied in actual deployment.
Q6: If you continue this line, what is the most natural next step?
Change Vidar from open-loop video execution to closed-loop receding horizon; replace GPT-4o TTS with a locally deployable physical consistency/task success evaluator; further integrate touch, force or proprioception into states other than video to solve the problem of invisible information in video.