F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
1. Quick overview of the paper
Difficulty rating: ★★★★☆. Reading requires familiarity with VLA, predictive inverse dynamics, Mixture-of-Transformer, VAR/RQ-VAE next-scale image generation, flow matching action prediction, and LIBERO / SimplerEnv / real robot evaluation.
Keywords: Vision-Language-ActionVisual ForesightPredictive Inverse DynamicsMixture-of-TransformerFlow MatchingLong-horizon Robotics
| Reading targeting item | Short answer |
|---|---|
| What should the paper solve? | Most of the existing VLA is reactive state-to-action mapping, which is short-sighted and fragile in dynamic scenes and long-range tasks; visual prediction strategies often lack VLM semantic grounding. F1 should combine semantic understanding, future visual prediction and action execution into a reasoning chain. |
| The author's approach | Mixture-of-Transformer three experts: understanding expert processes language and current observation; generation expert uses next-scale prediction to generate goal-conditioned foresight image; action expert uses foresight as an explicit target and uses flow matching to generate action chunks. |
| most important results | The real Genie-1 nine-task average success rate is 82.2%, higher than $\pi_0$'s 65.2%; LIBERO pre-training version averages 95.7%, ranking first; the SimplerEnv Bridge pre-training version has an overall average of 72.9%; the dynamic conveyor belt task is 66.7%, $\pi_0$ is 33.3%. |
| Things to note when reading | The generation module of F1 is not just a training auxiliary item; the paper explicitly allows the model to first predict future observations during inference, and then rewrite the action generation into foresight-guided inverse dynamics. The image does not have to be pixel perfect, but it must provide task-progress cues. |
Core contribution list
- A new paradigm is proposed that explicitly puts visual foresight generation into the VLA decision pipeline, turning action prediction from reactive imitation to planning-based control.
- Design UGA progressive attention to make information flow in one direction from Understanding → Generation → Action to avoid reverse leakage of action to foresight.
- Three stages of training are proposed: Stage I aligns generation and understanding; Stage II pre-trains the full model on large-scale robot data; Stage III post-trains on the target embodiment/task.
- System evaluation on real robots, LIBERO, SimplerEnv Bridge, dynamic scenes, fast adaptation, long-range tasks and generation quality correlation.
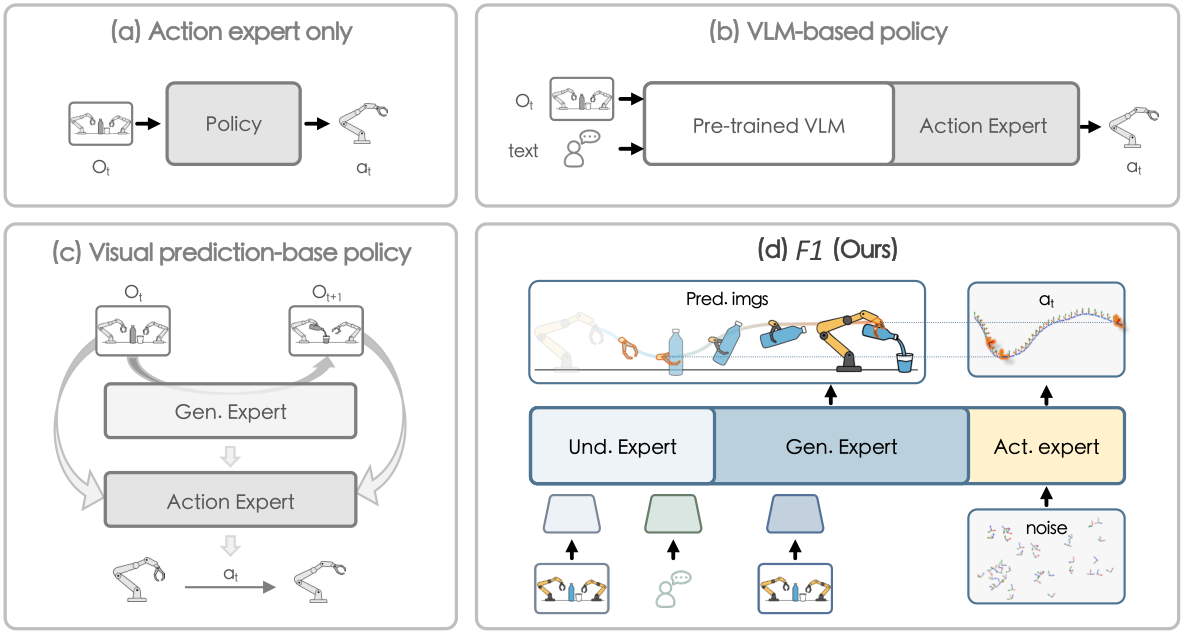
2. Motivation
2.1 What problem should be solved?
Real robotic environments are not a static picture classification problem: objects move, scenes change, and instructions often require multiple steps to unfold. Traditional VLA maps directly from the current image and language to actions, which is prone to short-sighted behavior when dynamic targets, long-term sequences, and distribution changes. F1 believes that the robot needs to explicitly predict "what the next visual state should be if the task continues to advance" before acting.
This problem is formulated as predictive inverse dynamics: first predict the future observation $\hat{o}_{t+1}$, and then infer the action chunk required to get from the current state to this future visual target. Action is not just a reaction to the current frame, but towards a generated visual target.
2.2 Limitations of existing methods
The paper divides manipulation policy into three categories. End-to-end action experts such as ACT and Diffusion Policy lack semantic grounding and cross-task generalization; VLM-integrated policies such as $\pi_0$ and gr00t-N1 have stronger understanding capabilities, but are still reactive and lack scene evolution modeling; visual prediction policies such as VPP and Genie Envisioner can predict future vision, but do not fully integrate VLM semantic understanding and have limited control robustness.
Therefore, the core issue of F1 is not "adding a video prediction loss", but to find an architecture and training principle to connect semantic understanding, future visual prediction, and action execution in a controllable information flow.
2.3 Solution ideas of this article
F1 uses three MoT experts: understanding expert inherits VLM capabilities; generation expert generates foresight through RQ-VAE / next-scale prediction; action expert uses current observation, language, proprioception and predicted future images as conditions to generate continuous action chunks through flow matching. For training, first let the generation learn to align with the understanding, then jointly pre-train on large-scale robot data, and finally post-train for the specific platform.
4. Detailed explanation of method
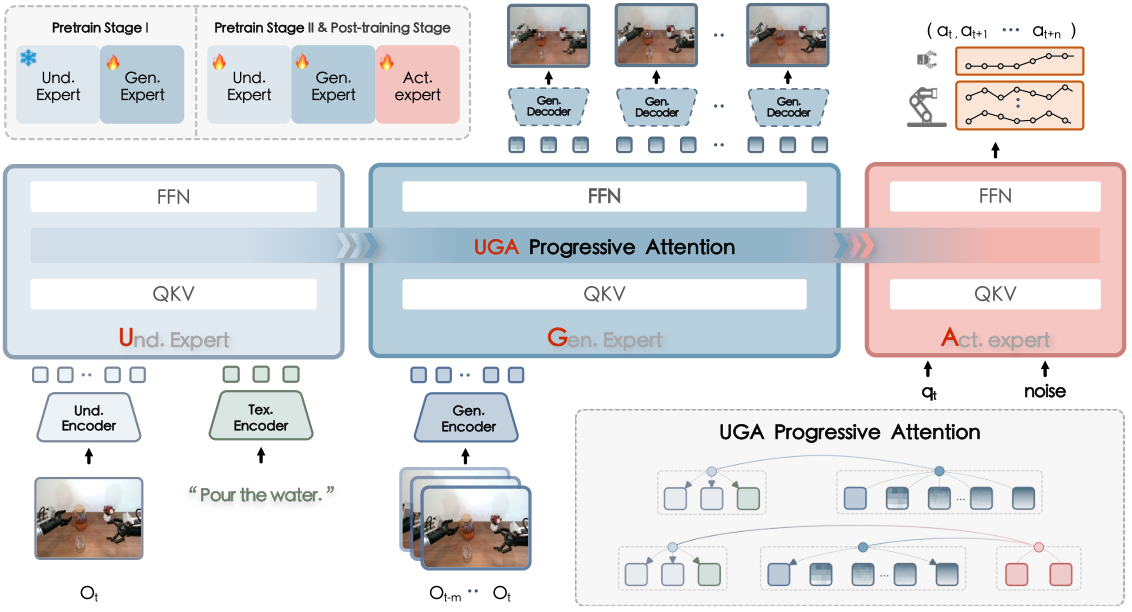
4.1 Overall pipeline
Given the language instruction $l$, the current observation $o_t$ and the historical observation $\{o_{t-m}, \ldots, o_{t-1}\}$, the calculation chain of F1 is as follows:
Input: instruction l, current observation o_t, history o_{t-m:t-1}, proprioception q_t
1. Understanding expert:
encode language + current visual observation into semantic multimodal representation
2. Generation expert:
use history + language + understanding representation
generate visual foresight image: o_hat_{t+1}
3. Action expert:
condition on l, o_t, q_t, o_hat_{t+1}
generate action chunk a_hat_{t:t+k} using flow matching
The paper emphasizes that $\hat{o}_{t+1}$ is an explicit planning target. Action expert does not only rely on the current state, but moves closer to predicting the future visual state.
4.2 Understanding Expert
Understanding expert is initialized from the pretrained vision-language model. The current observation $o_t$ is first encoded into high-level perceptual features by the SigLIP vision encoder, and then input into the decoder-only Transformer together with the language prompt. The implementation details state that the understanding expert architecture is the same as PaliGemma and inherits weights from $\pi_0$.
4.3 Generation Expert: Next-Scale Visual Foresight
The Generation expert is responsible for generating $\hat{o}_{t+1}$. It does not directly do high-cost diffusion video generation, but uses VAR style next-scale prediction. The recent historical observation $\{o_{t-m}, \ldots, o_t\}$ is encoded by multi-scale residual vector quantization, and each frame is decomposed into the multi-scale token $\{z_i^0, \ldots, z_i^k\}$ on the $16\times16$ patch. In order to avoid the multi-frame token string being too long, the model uses temporal convolutional network to aggregate motion-relevant features.

4.4 Action Expert: Foresight-Guided Flow Matching
Action expert is conditioned on language, current observation, foresight image and proprioception, and outputs short-range action chunk $\hat{a}_{t: t+k}$. The paper uses ACT-style chunked action prediction and uses flow matching to learn the vector field from Gaussian noise to expert action in the continuous action space.
This loss is learned in the training policy: given the current context and the noisy action $a_t^\tau$, predict the direction in which the movement should be towards the true action.
$$a_t^\tau = (1-\tau)\epsilon + \tau a_t, \quad \tau\sim\mathcal{U}(0, 1), \quad \epsilon\sim\mathcal{N}(0, I)$$ $$\mathcal{L}_{\mathrm{action}} = \mathbb{E}\left[\left\|\pi_\theta(l, \{o_i\}_{i=t-m}^{t}, q_t, a_t^\tau)-(a_t-\epsilon)\right\|^2\right]$$| $q_t$ | proprioception information at time $t$. |
| $a_t^\tau$ | Interpolation points of real action $a_t$ and noise $\epsilon$. |
| $a_t-\epsilon$ | flow matching target vector, pointing in the direction from noise to real action. |
4.5 UGA Progressive Attention
UGA stands for Understanding-Generation-Action. Rich token interactions can be carried out within each expert, and the foresight tokens in the generation expert maintain causal/scale-conditioned patterns. The information flow across experts is a one-way hierarchy: generation attends to understanding, action attends to both, but action cannot affect generation in the reverse direction, and understanding does not receive information from subsequent modules.
This design has two functions: first, to prevent reverse leakage of action tokens during training, making foresight truly an intermediate representation; second, to make the model structure interpretable as "first understand, then imagine, then execute."
4.6 Three-stage training
| stage | target | Training method | Key hyperparameters Appendix Training Details |
|---|---|---|---|
| Pretrain Stage I | Inject the foresight capability into the generation expert and align it with the frozen understanding expert. | The understanding expert inherits $\pi_0$ and freezes it; the generation expert is randomly initialized and uses teacher forcing to predict ground-truth future visual tokens. | batch 1280, lr 3e-4, cosine, 512K steps, understanding resolution 224, generation resolution 256, 10 predicted scales. |
| Pretrain Stage II | Jointly optimize three experts on large-scale robot data to learn general visuomotor knowledge. | Joint training using autoregressive predicted foresight tokens + flow matching action prediction. | batch 2880, lr 5e-5 constant, 100K steps, Gen: Act loss weight 0.1: 1, action chunk size 30, 4 predicted scales. |
| Post-train Stage III | Adapt to downstream platforms and tasks. | Finetune on LIBERO, Simpler, Genie-1, Franka, Dynamic, Long-horizon and other mission data. | batch 128, lr 5e-5 cosine; Simpler 10 epochs, Genie/Franka/Dynamic 40 epochs, Long-horizon 60 epochs; action chunk size is 4/8/50, etc. respectively. |
The overall goal of Stage II/III is to combine predicting future images and generating actions.
$$\mathcal{L}_{\mathrm{total}}=\mathcal{L}_{\mathrm{gen}}^{\mathrm{pred}}+\lambda\cdot\mathcal{L}_{\mathrm{action}}$$Among them, $\mathcal{L}_{\mathrm{gen}}^{\mathrm{pred}}$ is the autoregressive next-scale visual token NLL, and $\lambda$ controls the action loss weight.
4.7 Data scale
Appendix Dataset Details Complete statistics are given: a total of 330.9K trajectories, 73.8M frames, covering Genie-G1, Franka, WidowX, Google Robot, ARX LIFT II, multi-view including third-person, wrist/head, frame rate 3-30 FPS.
| data source | Stage | Embodiment | # Trajs | # Frames |
|---|---|---|---|---|
| Agibot-World | I + II | Genie-G1 | 187K | 66.4M |
| LIBERO | I + II + III | Franka | 1.7K | 0.3M |
| OXE-Bridge-v2 | I + II + III | WidowX | 53.2K | 1.9M |
| OXE-Fractal | I + II | Google Robot | 87.2K | 3.8M |
| In-house tasks | III | Genie-G1 / Franka / ARX LIFT II | About 1.8K | About 1.4M |
5. Experiment

5.1 Real Genie-1 Nine Missions
15 tests per task, comparing $\pi_0$, gr00t-N1, gr00t-N1.5 and F1. The average success rate of F1 is 82.2%, which is higher than $\pi_0$'s 65.2%, gr00t-N1.5's 53.3%, and gr00t-N1's 30.4%.
| method | Pen | Flower | Chip | Tea Table | Tea Shelf | Bread | Handover | Handover R2H | Mixture | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| $\pi_0$ | 66.7 | 66.7 | 86.7 | 86.7 | 73.3 | 66.7 | 33.3 | 40.0 | 66.7 | 65.2 |
| gr00t-N1 | 46.7 | 33.3 | 33.3 | 40.0 | 13.3 | 33.3 | 26.7 | 13.3 | 33.3 | 30.4 |
| gr00t-N1.5 | 73.3 | 40.0 | 46.6 | 73.5 | 26.6 | 53.3 | 60.0 | 40.0 | 66.7 | 53.3 |
| F1 | 93.3 | 80.0 | 100.0 | 93.3 | 86.7 | 66.7 | 80.0 | 73.3 | 66.7 | 82.2 |
The paper emphasizes that Handover (R2H) requires dynamic adjustment and human-computer interaction, with F1 73.3%, significantly higher than $\pi_0$'s 40.0% and gr00t-N1's 13.3%.
5.2 LIBERO
| method | Pretrained | Spatial | Object | Goal | Long | Average | Avg Rank |
|---|---|---|---|---|---|---|---|
| $\pi_0$ | Yes | 98.0 | 96.8 | 94.4 | 88.4 | 94.4 | 2 |
| gr00t-N1 | Yes | 94.4 | 97.6 | 93.0 | 90.6 | 93.9 | 4 |
| CoT-VLA | Yes | 87.5 | 91.6 | 87.6 | 69.0 | 83.9 | 6 |
| F1 | No | 97.4 | 97.6 | 94.2 | 88.0 | 94.3 | 3 |
| F1 | Yes | 98.2 | 97.8 | 95.4 | 91.3 | 95.7 | 1 |
LIBERO-Long is the suite with the greatest long-range planning pressure. The F1 pre-training version reaches 91.3%, exceeding $\pi_0$'s 88.4% and gr00t-N1's 90.6%. This supports the authors' contention that foresight is effective for long-range missions.
5.3 SimplerEnv Bridge
| method | Pretrained | Carrot Success | Eggplant Success | Spoon Success | Stack Success | Overall Avg |
|---|---|---|---|---|---|---|
| SpatialVLA | Yes | 25.0 | 100.0 | 16.7 | 29.2 | 47.9 |
| $\pi_0$ | Yes | 0.0 | 16.6 | 62.5 | 29.1 | 40.1 |
| $\pi_0$-Fast | Yes | 21.9 | 10.8 | 66.6 | 29.1 | 48.3 |
| F1 | No | 33.3 | 75.0 | 45.8 | 62.5 | 66.1 |
| F1 | Yes | 70.8 | 66.7 | 50.0 | 50.0 | 72.9 |
SimplerEnv Bridge mission emphasizes fine-grained placement. The overall average of F1 is significantly higher than the next strongest baseline, which the paper attributes to foresight's ability to adapt to changes in source object configuration and target location.
5.4 Simulated ablation
| Variant | meaning | Avg | Main conclusions |
|---|---|---|---|
| F1 | complete model | 77.5 | baseline. |
| Frozen-Gen | Freeze generation expert after Stage I | 73.8 | Fixed generation is still useful, but subsequent end-to-end adaptation can improve task alignment. |
| Cotrain-Scratch | Remove Stage II large-scale robot pre-training | 74.2 | Stage II provides manipulation prior, stable optimization. |
| No-Gen | Remove generation expert | 60.3 | visual foresight is the most critical module. SimplerEnv will obviously collapse after being removed. |
| 2-Scales | Inference only predicts 2 planning scales | 73.4 | foresight is rough and lacks planning information. |
| 6-Scales | Inference prediction 6 planning scales | 75.8 | More scales are not necessarily better, are more computationally intensive and may introduce instability; the paper ultimately uses 4 scales. |
5.5 Real task ablation and dynamic generalization
Real task ablation shows that No-Gen achieves only 40.0% and 60.0% in Handover (R2H) and Mixture respectively, while F1 reaches 93.3% and 73.3%. Cotrain-Scratch is also significantly lower than the full model, indicating that Stage II's large-scale robot pre-training is helpful for real downstream generalization.
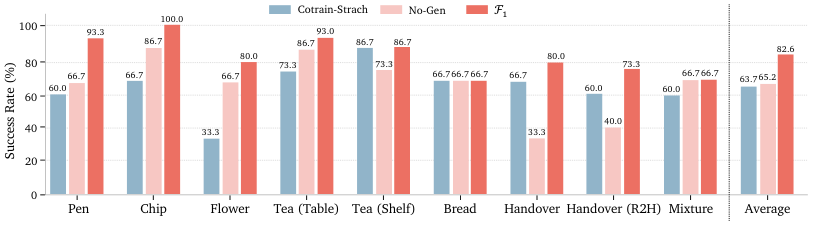
The dynamic conveyor belt experiment uses ARX LIFT II, a robot embodiment not found in the pre-training data. Using only 47 post-train demonstrations, the success rate of F1 in continuous double-arm dynamic grasping is 66.7%, and that of $\pi_0$ is 33.3%; in the Lettuce and Bread subtasks, the success rate of F1 is 80.0%, and that of $\pi_0$ is 53.3% and 46.7%.

5.6 Rapid adaptation and long-range tasks
| experiment | $\pi_0$ | F1 | Description |
|---|---|---|---|
| Franka sweep: number of successful objects | 4.9 / 8.0 | 7.1 / 8.0 | F1 sweeps more. |
| Franka sweep: maximum number of attempts | 4.8 / 5.0 | 3.5 / 5.0 | F1 has fewer attempts. |
| Franka sweep: number of empty sweeps | 2.4 / 5.0 | 0.8 / 5.0 | The paper explains that reduced air scans reflect more accurate spatial grounding. |
| Sort 1/2/3 consecutive grabs | 100 / 86.7 / 53.3 | 100 / 100 / 66.7 | F1 retains better across repeated interactions. |
The long-range ARX LIFT II mission consists of 10 steps and approximately 2 minutes. $\pi_0$ is 93.3% in the first two pickplace steps, and basically 0% after that; F1 is 100% in the first three steps, 93.3% in steps 4/5, and there are still 73.3%, 60.0%, 40.0%, 40.0%, and 40.0% in subsequent complex steps. The paper acknowledges that the decline in subsequent steps is consistent with long-range error accumulation expectations.
5.7 Generation quality and action reliability
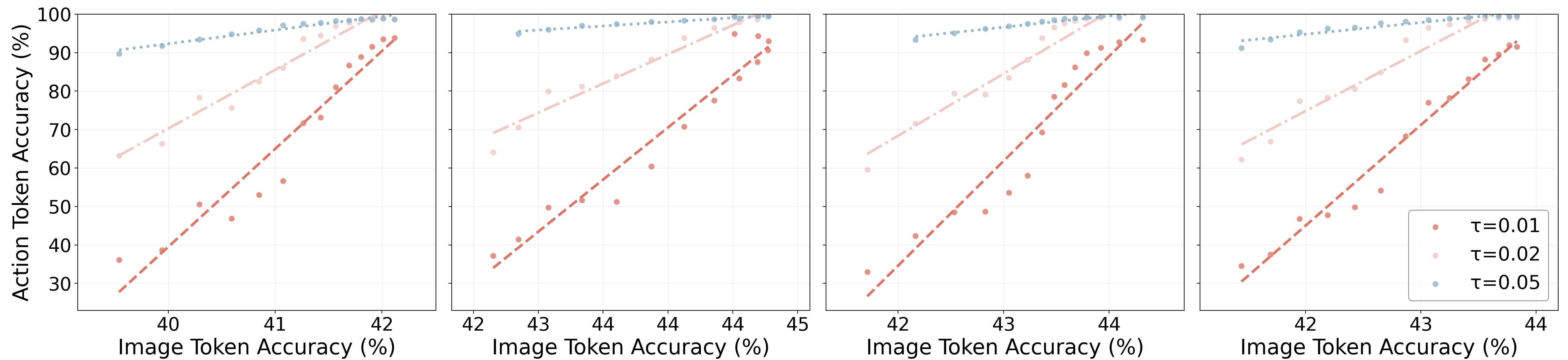
The paper does not use traditional FID/PSNR as the main generation indicator, but uses Qwen2.5-VL-32B-Instruct for task-relevant evaluation. The input includes task instruction, four frame history, predicting the next frame and ground-truth frame; the output includes three binary scores: scene consistency, object consistency, and task progress following. prompt template in Appendix Prompt Template given in.
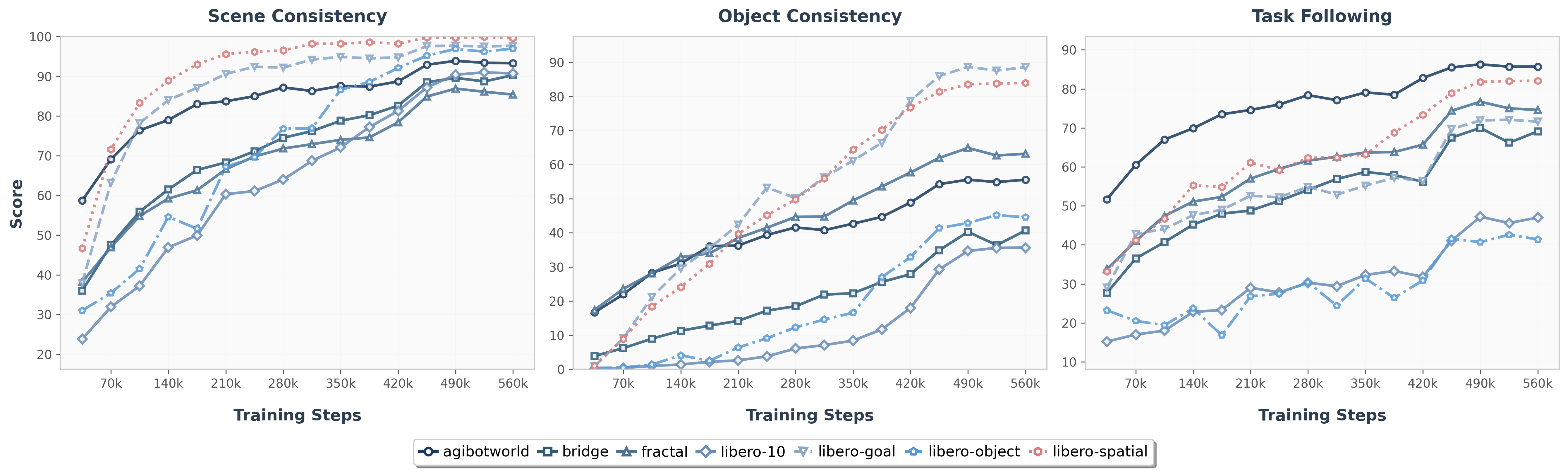
The authors observed that the object consistency curve is lower because F1 is not pre-trained on large-scale generative datasets; but task progress following often exceeds object consistency, indicating that foresight can provide action-related clues even if the pixels are not perfect.
6. Repeat audit
6.1 Code and resources
Already published: The official GitHub is InternRobotics/F1-VLA, including f1_vla/, train_hf.py and README training entrance. The project homepage is F1-VLA, HuggingFace organization provides model/data entry.
Dependencies given in README: Python ≥ 3.10, torch ≥ 2.6.0, CUDA ≥ 12.4; FFmpeg + TorchCodec is recommended to speed up video data loading.
Downloads: README points to LIBERO no-op filtered data, F1_pretrain checkpoint, lerobot/pi0_base, google/paligemma-3b-pt-224, VAR VAE weights.
6.2 reproducibility path
- Clone the repository and create an environment:
git clone https://github.com/InternRobotics/F1-VLA.git,conda create -n f1_vla python==3.10. - Install PyTorch CUDA 12.4 version and repository:
pip install torch==2.6.0 ..., enterF1-VLA/f1_vlaafterpip install -e .. - Download the README specifying checkpoint/tokenizer/VAE/LIBERO data and fill in the path in the configuration.
- Edit configuration:
f1_vla/config/debug_test.yamlOr corresponding task configuration. - Run training:
python train_hf.py --config-file f1_vla/config/debug_test.yaml.
6.3 Deployment delays
Appendix Deploy Platform and Latency Analysis: All experiments were run on an Intel i9 CPU + NVIDIA RTX 4090 workstation, and the robot was connected via wired Ethernet. When three channels of synchronous camera input are used, the total inference time is about 235ms.
| module | delay |
|---|---|
| image process / resize | 18ms |
| temporal downsampling | 28ms |
| image encoder | 18ms |
| foresight generation | 76ms |
| x10 action forward pass (flow) | 95ms |
| Total | 235ms |
6.4 Recurrence risk
- Large-scale training costs are high: Stage I 512K steps, Stage II 100K steps, batch size 1280 / 2880 respectively. Real and complete pre-training is not a single-card lightweight replication experiment.
- Real robot tasks rely on in-house demonstrations and Genie-G1/Franka/ARX LIFT II platforms, and public code does not mean reproducible physical forms.
- The generation quality evaluation relies on Qwen2.5-VL-32B-Instruct as the evaluator, and the prompt is disclosed in the appendix, but the evaluation stability still depends on the model version and calling settings.
- The paper claims that F1 is a 4.2B parameter model, and the project also requires initialization resources such as PaliGemma / $\pi_0$ / VAR VAE and multi-view video processing links.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Based on the paper's own evidence, the most valuable thing is to upgrade "future image prediction" from an auxiliary training goal to an explicit planning intermediate variable during inference. F1 lets the generation expert first produce visual foresight, and then lets the action expert target it to do inverse dynamics. This is closer to the structure of "imagine first and then execute" than simply adding an action head to the backbone. No-Gen dropped from 77.5% to 60.3% in ablation, Real Handover (R2H) and Dynamic Conveyor tasks also showed that foresight is particularly important for complex dynamics.
7.2 Why the results hold up
The evidence chain of the paper is relatively complete: nine real tasks show that F1 improves the average success rate relative to $\pi_0$; LIBERO and SimplerEnv provide simulation benchmarks; Frozen-Gen, Cotrain-Scratch, No-Gen, and 2/6 scales ablation respectively verify generation trainability, Stage II pre-training, generation expert itself, and the number of inference scales; dynamic conveyor belt, Franka fast adaptation, and 10-step The long-range task shows scenarios beyond short-range static crawling; the generation quality chapter also shows that foresight quality is positively related to action accuracy.
7.3 Limitations and future directions described by the author
- The pixel-level details of Foresight images are still limited, especially for fine-grained or deformable objects such as grid shopping carts, plastic bags, and clothing. The author attributes the reason to the lack of pre-training generation experts on large-scale generative datasets.
- The success rate of long-range tasks dropped significantly in the second half, which the paper explained was due to the accumulation of long-range errors and the increased difficulty of complex reasoning.
- Future directions include expansion to more embodiments and task families, such as locomotion, dexterous manipulation, and multi-agent collaboration.
- The author also proposed that foresight can be enhanced with structured world models or physics-informed priors, and combined with reinforcement learning / online adaptation / human feedback for continuous improvement.
7.4 Applicable boundaries
F1 is suitable for manipulation tasks where the future visual state can provide clear planning goals for actions, especially dynamic goals, long-range steps, hand-eye coordination and cross-platform adaptation. It relies heavily on multi-view historical images, proprioception, generative visual tokenization and heavier reasoning chains. There is insufficient evidence in the paper for tasks such as invisible contact forces, pure tactile feedback, extremely high-speed closed-loop control, or tasks where the target state cannot be expressed through images.