Unified Diffusion VLA: Vision-Language-Action Model via Joint Discrete Denoising Diffusion Process
1. Quick overview of the paper
| Reading targeting item | compact conclusion |
|---|---|
| What should the paper solve? | Existing unified VLA either relies on external vision/action experts, or although it tokenizes vision and action, it retains separate decoding between image generation and action prediction, resulting in insufficient guidance of action by future images and slow reasoning. |
| The author's approach | Use VQ visual tokenizer and FAST action tokenizer to convert images and actions into discrete tokens; use hybrid attention to maintain cross-modal directionality; use JD3P to synchronously denoise future image tokens and action tokens in the same discrete diffusion process. |
| most important results | The average length of CALVIN ABCD->D is 4.64; the average success rate of LIBERO is 92.7%; the SimplerEnv-WidowX table overall is 62.5%; the JD3P decoding speed is 219.3 tokens/s, which is about 4.3 times higher than AR's 50.2 tokens/s. |
| Things to note when reading | The core is not "adding future images" itself, but letting the action token repeatedly attend to the intermediate future image token in multiple rounds of denoising; also note that there are numerical inconsistencies between the SimplerEnv text and the table. |
Difficulty rating: ★★★★★. Need to be familiar with VLA, visual chain-of-thought, VQ tokenization, FAST action tokenization, discrete diffusion / mask-predict, attention mask design and robot imitation learning benchmark.
Keywords: Vision-Language-ActionDiscrete DiffusionJD3PHybrid AttentionFuture Image Generation
Core contribution list
- Unified Diffusion VLA. The paper proposes to unify understanding, generation, and acting in one transformer instead of splicing them through external image/action decoder or separation process.
- JD3P. The Joint Discrete Denoising Diffusion Process puts future images and actions into the same discrete mask-denoise trajectory, allowing actions to receive guidance from the intermediate results of future images in each round.
- Hybrid attention. Bidirectional attention is used inside image blocks and action blocks to maintain the causal direction across blocks to avoid action-to-vision information leakage while retaining the conditional dependence of action on future images.
- Training and inference supporting design.The two-stage training first injects future image generation capabilities into VLM, and then jointly trains on the robot action data; prefix KV cache, prefilled special tokens, confidence-guided decoding and decoding space mapping are used during inference.
2. Motivation
2.1 Problems to be solved
The VLA's task is to read in natural language instructions and visual observations and output actions that can be performed in the physical world. Recently, unified VLA has begun to incorporate future images into the understanding-acting loop: first predict the future visual state, and then convert the action prediction into the inverse kinematics problem of "how to achieve this future state."
The paper believes that true unification is not just to put the output modality in the same sequence, but to make visual generation and action generation gain each other. If the future image is only used as an auxiliary task in the training stage, or if image generation and action generation are performed separately during inference, the action token can only absorb future visual information to a limited extent.
2.2 Limitations of existing methods
| paradigm | Typical approach | Issues pointed out in the paper |
|---|---|---|
| External experts unify modalities | GR-1, SEER, DreamVLA, F1, UP-VLA, etc. use additional encoder/decoder or diffusion experts to generate vision/action. | Module separation may lead to misalignment, higher complexity, and weak coupling of vision generation and action prediction. |
| Unify input and output token space but separate decoding | CoT-VLA, WorldVLA, UniVLA, etc. unify images and actions at the token layer. | Images and actions are still not the same joint decoding process; some methods only decode actions during inference, and the predictive value of images in training is not explicitly retained. |
| AR generates images and actions | Autoregressively generate future images/actions in token order. | Each action token usually only undergoes context calculation once, and the image does not provide sufficient guidance for the action; the image token itself is not naturally suitable for strict next-token order. |
2.3 High-level ideas of this article
The core assumption of UD-VLA is that generating future images and generating actions should be co-optimized in the same simultaneous denoising process. As the future image is restored from coarse to fine, the action token is also gradually restored from the mask/noise state; each action can attend to the future image in the current denoising stage, thereby obtaining continuous and sufficient visual guidance.
4. Detailed explanation of method
4.1 Unified Tokenization
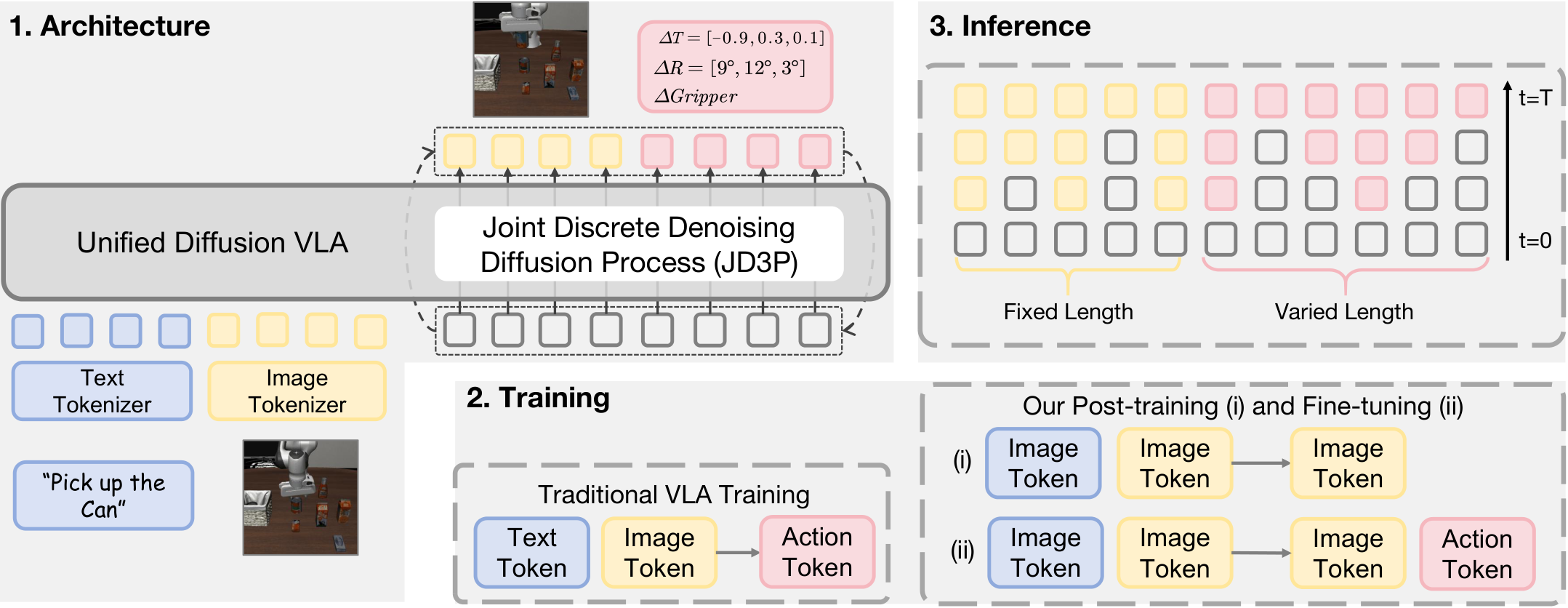
UD-VLA converts language, vision, and actions into discrete tokens and spells them into a single sequence. Language token design follows Emu3; current and future images are discretized by VQ tokenizer; actions are represented by FAST tokenizer. Author's use <BOI>/<EOI> To mark an image block, use <BOA>/<EOA> Mark action block.
This sequence puts the input and output in the same token space: the first half is the condition, and the second half is the future vision and action the model wants to generate.
$$[\; \text{text tokens}; \; \text{current image tokens}; \; \text{future image tokens}; \; \text{action tokens}\; ]$$| text tokens | Verbal instructions are the input for understanding the intent of the task. |
| current image tokens | The current observed image token is the visual condition. |
| future image tokens | The future visual state to be generated by the model, fixed length. |
| action tokens | The action sequence to be generated by the model, variable length, obtained by FAST action tokenizer. |
4.2 Hybrid Attention
The basic rules of Hybrid attention are: text/current image is used as understanding input; future image block and action block are output. Bidirectional attention is allowed within the block to allow full interaction between image tokens or action dimensions; causal direction is maintained between blocks, so that the future image can only see the input, and the action can see the input and the future image, but action information is not allowed to flow back to the vision.
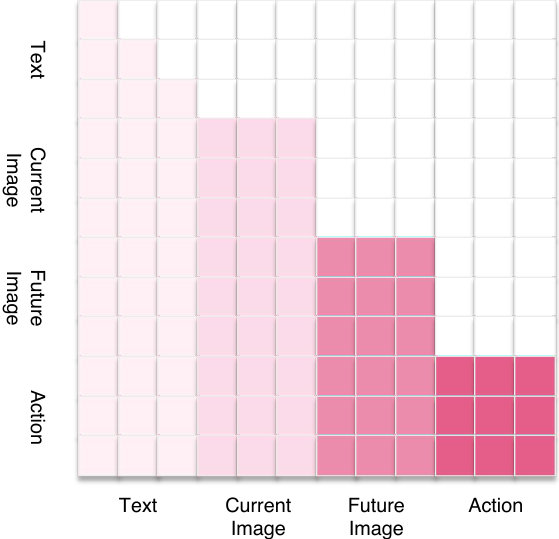
Intuitive understanding: The patches/tokens within an image do not have strict sequence of cause and effect, and the different spatial dimensions of actions do not have strict token order, so bidirectional within a block is more appropriate; but there is directionality between "current observation - future image - action", so causality is required across blocks.
4.3 Joint Discrete Denoising Diffusion Process
JD3P combines the future image tokens $\mathbf{v}_0$ and the action tokens $\mathbf{a}_0$ into a sequence. Forward noising does not add Gaussian noise, but replaces the token with a special mask token $\mathrm{M}$ with probability $\beta_t$; reverse denoising predicts the original token at the masked position.
"Noising" in discrete diffusion is to gradually cover the token; "denoising" is to restore the covered image/action token according to the context.
$$\mathbf{Q}_t\mathbf{e}_{t, r}=(1-\beta_t)\mathbf{e}_{t, r}+\beta_t\mathbf{e}_{\mathrm{M}}$$| $\mathbf{e}_{t, r}$ | The one-hot token at position $r$ may come from a future image or action. |
| $\beta_t$ | The probability that step $t$ is replaced by mask. |
| $\mathbf{e}_{\mathrm{M}}$ | One-hot basis of mask token. |
Reverse decomposition into two parts: visual recovery and movement recovery:
where $\mathbf{c}$ is text and current image. Note that the action distribution is explicitly conditioned on $\mathbf{v}_t$, so each action recovery step can take advantage of future visual tokens at the current stage.
4.4 Loss Function
During training, the author does not explicitly expand the complete multi-step diffusion chain, but uses a single-step mask-predict objective: randomly sampling mask ratio $\rho_t$, covering part of the clean future image/action token, and only calculating cross-entropy at the blocked position.
The number of visual tokens may be much greater than that of action tokens, so the paper uses $\omega$ to reduce the visual loss weight to avoid visual items dominating the training.
$$\mathcal{L}_{\text{CE}}(\theta)= -\omega\sum_j^{L_v}\log p_\theta^{(v)}(v_{0, j}\mid\mathbf{v}_t, \mathbf{c})\mathbb{1}\{v_{t, j}=\mathrm{M}\} -\sum_i^{L_a}\log p_\theta^{(a)}(a_{0, i}\mid\mathbf{v}_t, \mathbf{a}_t, \mathbf{c})\mathbb{1}\{a_{t, i}=\mathrm{M}\}$$Appendix Loss Formulations Four types of losses, namely MSE, continuous diffusion, discrete diffusion, and next-token prediction, are also defined in Table 1 for comparing different VLAs. The most critical thing in the report is $\mathcal{L}_{\mathrm{Diff\text{-}disc}}$: it is masked-token prediction on a limited vocabulary, rather than noise prediction in continuous space.

4.5 Two-stage training
- Stage (i): world-model style post-training. Initialized from the pretrained VLM backbone, future image predictions are trained on large-scale video data with the sequence
[text; current image; future image], The goal is to infuse VLA with the ability to model future, states. - Stage (ii): robot action fine-tuning. Use full sequences on downstream robot motion data
[text; current image; future image; action], jointly train image generation and action generation according to JD3P.
Appendix Training Details Given training resources: CALVIN-ABCD action chunk 10, 8 H100s, training takes about 24 hours; LIBERO four suite joint training, action chunk 10, 8 H100s, about 30 hours; SimplerEnv uses Bridge data training, action chunk 5, 8 H100s, about 30 hours; real-world experiments collect 600+ trajectories, action chunk 8, 8 H100s, about 8 hours. Another configuration is also written in the real-world task section of the text: 4 H100 training for 24 hours, 9000 steps, batch size 64, learning rate 8e-5, weight decay 0.1. The two GPU/duration descriptions are not completely consistent, and should be further checked with the official code configuration when reproducing.
4.6 Reasoning
Inference starts from all masked future image/action tokens and repeats for a small number of iterations. Each round predicts the distribution of all mask positions in parallel, selects a part of the most reliable positions to fill in tokens based on confidence, and continues to mask the rest. The mask ratio changes from high to low using cosine schedule.
5. Experiments and results
5.1 Benchmarks
| Benchmark | settings | indicator |
|---|---|---|
| CALVIN | 4 environments A/B/C/D, 34 tasks, 1000 language instructions; each model evaluates 500 rollouts, and each rollout has 5 consecutive sub-tasks. | Average finished length avg. len., maximum 5. |
| LIBERO | There are four suites of Spatial, Object, Goal and Long; each suite has 10 tasks and each task has 50 rollouts. | The success rate and average success rate of each suite. |
| SimplerEnv-WidowX | Real-to-sim environment, tasks include Put Spoon, Put Carrot, Stack Block, Put Eggplant; change lighting, texture, color, and perspective. | Single task success rate and overall. |
| Real-world | UR5e + Inspire RH56E2 hand + D435i wrist camera + Gemini 336L static camera; three types of tasks: stacking bowls, putting blocks, flipping towers. | Each method is evaluated 30 times per task, seen/unseen setting. |
5.2 Main Results in Simulation
| Benchmark | UD-VLA results | Key contrasts |
|---|---|---|
| CALVIN ABCD->D | 1/2/3/4/5 company mission success rate is 0.992/0.968/0.936/0.904/0.840, Avg. Len. 4.64. | Higher than MDT 4.52, UP-VLA 4.42, MODE 4.39, UniVLA* 4.26, GR-1 4.21. |
| LIBERO | Spatial 94.1%, Object 95.7%, Goal 91.2%, Long 89.6%, Average 92.7%. | The Average in the table is higher than DreamVLA 92.6%, FlowVLA 88.1%, and $\pi_0$-FAST 85.5%. Long suite is 89.6%, the highest in the table. |
| SimplerEnv-WidowX | Put Spoon 58.3%, Put Carrot 62.5%, Stack Block 54.1%, Put Eggplant 75.0%, Overall 62.5%. | Overall in the table is higher than F1 59.4%, $\pi_0$-FAST 48.3%, and SpatialVLA 42.7%. |
5.3 In-Depth Analysis / Ablation
| question | settings | result | Paper explanation |
|---|---|---|---|
| Is the Attention mechanism critical? | Causal / Bidirectional / Hybrid | Avg. Len. 4.04 / 4.32 / 4.64 | Intra-block bidirectional is suitable for image spatial consistency and action dimension correlation; cross-modal full bidirectional will leak information, so hybrid is best. |
| Are future images more useful for reconstruction than current images? | Null / Current Image / Future Image | Avg. Len. 4.21 / 4.39 / 4.64 | Current image reconstruction enhances fine-grained perception, but only learns static information; future images provide temporal dynamics and action planning clues. |
| Is JD3P better than other decoding mechanisms? | AR / Jacobi / Independent Diffusion / JD3P | Avg. Len. 4.18 / 4.16 / 4.35 / 4.64; speed 50.2 / 101.6 / 144.4 / 219.3 tokens/s. | Joint denoising allows actions to repeatedly benefit from intermediate image denoising states; independent diffusion has limited information flow. |
5.4 Real-World Experiment
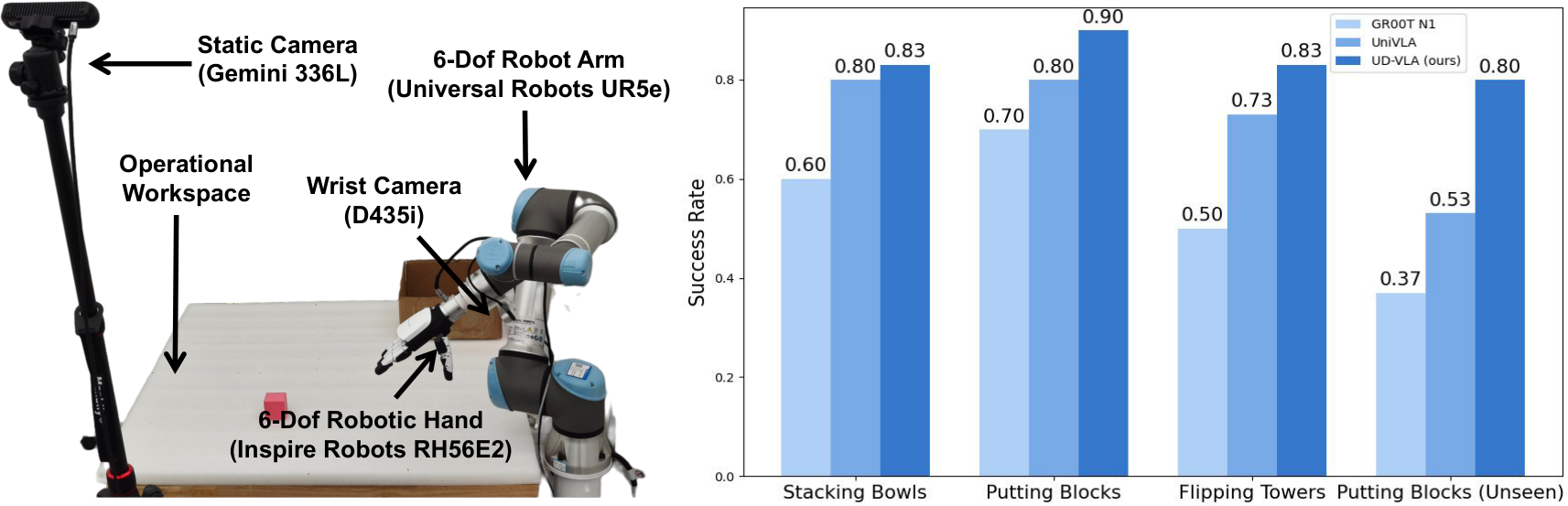
Real-world data includes three types of tasks: stacking bowls, putting blocks into a box, and flipping towers/towels. Each type of task contains objects of different colors and shapes, and the data is collected in three backgrounds; the main text contains 200 trajectories for each category, 15 Hz, and the appendix contains a total of 600+ trajectories. The evaluation includes seen and unseen; unseen includes new objects and new backgrounds.


The paper text reports that UD-VLA outperforms GR00T N1 and UniVLA on all real tasks, and the success rate of each task exceeds 80%. The author explains that in seen tasks, action quantization improves action accuracy, and joint denoising ensures action quality; in unseen tasks, future image generation improves visual generalization to unseen targets and backgrounds.
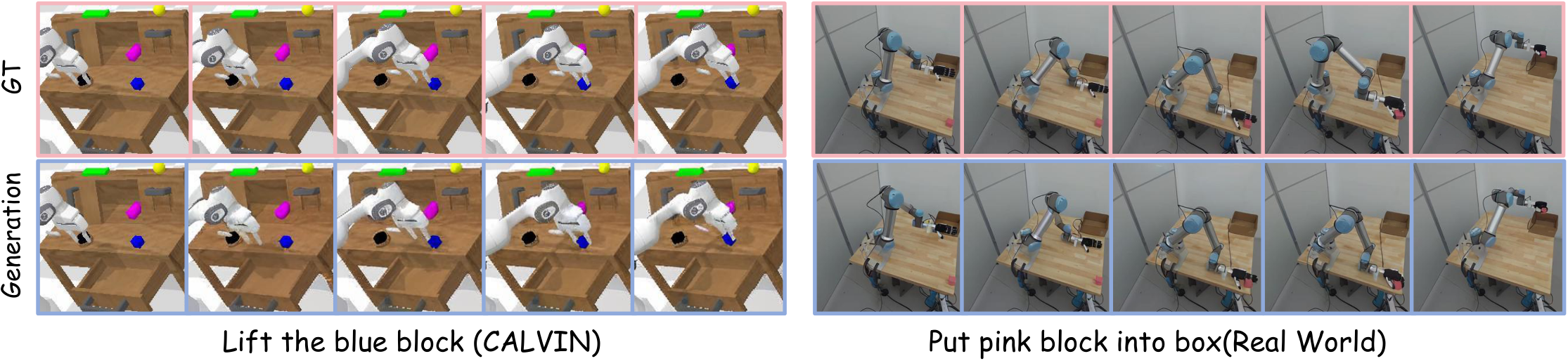
5.5 Future Image Generation Visualization

6. Analysis and discussion within the paper
6.1 Mechanism explanation given by the author
- Future image is a visual CoT.In the CALVIN results, the authors view explicit future image generation as a more efficient chain-of-thought because action prediction can be conditioned on future visual outcomes.
- Multi-step diffusion facilitates visual-motor information exchange.Compared with single-step filled-token prediction, JD3P allows images and actions to continuously interact through multiple rounds of intermediate states.
- Image generation requires bidirectional attention.The paper believes that the main relationship between image tokens is spatial consistency, which is not suitable for strict causal next-token; there is no natural causal order in different dimensions of actions.
- Discrete diffusion balances efficiency and performance.The speed of AR is 50.2 tokens/s; JD3P is 219.3 tokens/s, and Avg. Len. is the highest.
6.2 Limitations of author's self-report generation
The paper explicitly acknowledges in the visual analysis that generating future frames lacks visual fidelity, especially fine-grained details such as robotic arms and backgrounds. This is attributed to the lack of large-scale generative pretraining and the use of compressed images with fewer tokens for efficiency. The authors concluded that although pixel-level accuracy is difficult, the generated results still reliably express task progress and are sufficient to serve action planning.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
According to the paper's own evidence, the most valuable part is to advance future visual reasoning from "auxiliary training goals" to "intermediate structures that are jointly optimized during reasoning." JD3P allows the action token not to be generated after reading the future image at once, but to receive the intermediate state guidance of the future image token in each step of discrete denoising. During CALVIN ablation, Future Image compared to Null ranged from 4.21 to 4.64, JD3P compared to AR ranged from 4.18 to 4.64, and the speed ranged from 50.2 to 219.3 tokens/s. This is the paper's most direct evidence supporting the design.
7.2 Why the results hold up
The results are supported by three types of simulation benchmarks, real robots, and multiple groups of ablations: CALVIN checks long sequence language operations, LIBERO checks spatial/object/goal/long generalization, and SimplerEnv checks real-to-sim transfer; real experiments also cover seen/unseen objects and backgrounds. The ablation does not only compare the complete model and the weak baseline, but separates the attention, visual generation target, and decoding mechanism respectively, which makes the causal chain of "hybrid attention + future image + JD3P" clearer.
7.3 Limitations
- Future image quality is limited.The authors explicitly admit that the predicted frames are not detailed enough, especially the robotic arm and background. If the task requires precise geometry, occlusion relationships, or contact states, a low-fidelity future image may be insufficient.
- The real world is still small.The real experiment consists of three types of tasks and 600+ trajectories. Although it includes unseen settings, it is not enough to prove large-scale universality across robots, cross-scenarios, and cross-skills.
- There are inconsistencies between the text and the table.SimplerEnv overall conflicts in the main text and the table; the training resources are also described differently in the real-world section of the main text and the appendix training details. You need to check the official code when reproducing.
- Depends on discrete tokenization quality.Both vision and action are compressed into discrete tokens, and quantization errors in the VQ codebook and FAST action tokenizer may limit fine-grained control.
7.4 Applicable boundaries
The paper evidence mainly covers language condition manipulation benchmark and controlled real desktop tasks. It has not yet been proven that it is suitable for long-term mobile operations, complex force-controlled assembly, high-speed dynamic operations, open environment safety constraints, or no robot form. Real hardware uses UR5e + dexterous hand + RGB-D/static camera; action tokenizer, chunk, camera views and controller may need to be retuned when changing to other embodiments.
8. Reproducibility Audit
| recurring elements | Information given in the paper/project | Audit status |
|---|---|---|
| Source code and diagrams | arXiv provides LaTeX source code, and all figures are independent PDFs; this report has been converted to PNG. | Checkable |
| code | The official GitHub is available on the project page: OpenHelix-Team/UD-VLA. | Found |
| Checkpoint | CALVIN ABCD-D Hugging Face checkpoint is available on the project page: UD-VLA_CALVIN_ABCD_D. | Found |
| Benchmark protocol | The tasks, rollout and indicators of CALVIN, LIBERO and SimplerEnv are given in the main text; the baselines are introduced item by item in the appendix. | more complete |
| training details | Information such as action chunk, number of GPUs, training duration, real experimental batch/lr/weight decay and other information are given. | There are local inconsistencies and code verification is required. |
| method formula | JD3P forward mask noising, reverse factorization, masked CE loss, confidence-guided decoding formulas are complete. | more complete |
| real data | The real experiment uses 600+ self-collected trajectories; the paper does not specify public downloading. | Real experiments are difficult to completely reproduce |