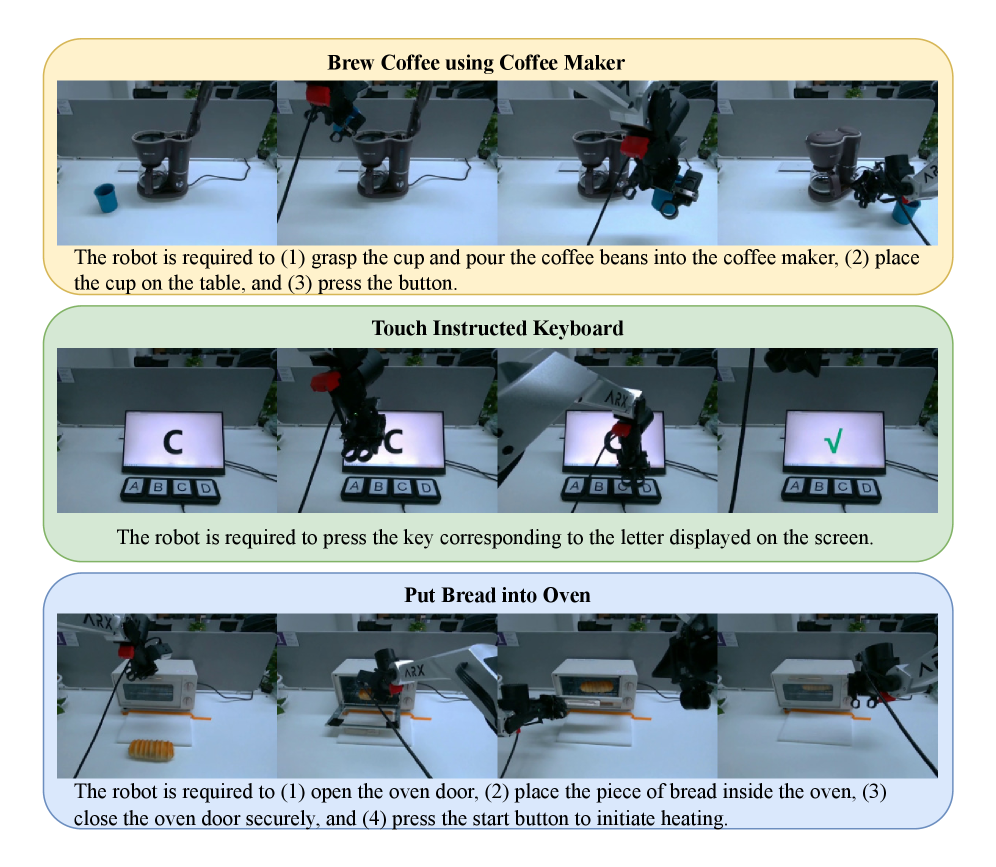
Motus: A Unified Latent Action World Model
1. Quick overview of the paper
Difficulty rating:★★★★☆. Reading requires understanding of VLA/action chunking, diffusion or rectified flow, video generation model, Mixture-of-Transformers, latent action and robot evaluation protocol.
Keywords:Unified Embodied Foundation Model, Latent Action, World Model, MoT, Rectified Flow, Cross-Embodiment Pretraining。
| Reading positioning | content |
|---|---|
| What should the paper solve? | Existing embodied models split understanding, future prediction, inverse dynamics, video generation and action output into isolated models; at the same time, large-scale videos, human perspective data and cross-robot trajectories make it difficult to jointly train action modules due to inconsistent action spaces. |
| The author's approach | Use MoT + Tri-model Joint Attention to connect VGM, action expert, and understanding expert; use UniDiffuser-style scheduler with different mode timesteps to switch five modeling modes; use optical flow to train latent action to compress pixel motion into a space close to the control dimension. |
| most important results | The average success rate of RoboTwin 2. 0 reaches Clean 88. 66% and Randomized 87. 02%, which is an absolute improvement of about 45 points compared to $\pi_{0.5}$; the average PSR of real AC-One is 63. 22%, and the average PSR of Agilex-Aloha-2 is 59. 30%. |
| Things to note when reading | The "unification" of Motus is not to splice all data directly into a common Transformer, but to achieve it through expert retention, joint attention interaction, modal noise scheduling and latent action alignment; the appendix algorithm illustrates how the five modes are switched by the same rectified-flow model. |
Core contribution list
- Unifying five embodied modeling paradigms.The paper puts WM, IDM, VLA, VGM, and Video-Action Joint Prediction into a generative model framework; this means that the same model can predict videos, actions, or both at the same time.
- MoT + Tri-model Joint Attention。VGM, action expert, and understanding expert each retain the Transformer module, and at the same time perform splicing interactions in the multi-head self-attention layer; this means that the model can use the prior of pre-trained VGM/VLM instead of training the unified backbone from scratch.
- Optical-flow latent action。The author treats optical flow as pixel-level delta action, which is compressed into 14-dimensional latent action by DC-AE and lightweight encoder; this means that videos without real action labels can also provide action-related motion supervision.
- Three-stage training with six-layer data pyramid.Stage 1 adapts to VGM, Stage 2 uses latent actions for unified training, and Stage 3 uses the target robot's real actions SFT; this means that data enters the training process hierarchically from web/egocentric/synthetic/multi-robot/target-robot.
- Simulation and real machine verification.The paper reports results on RoboTwin 2. 0, LIBERO-Long, VLABench and two types of real dual-arm platforms; this means that the author not only verified the VLA policy, but also demonstrated the complementary capabilities of VGM, WM, IDM and other modes.
2. Motivation
2. 1 What problem should be solved?
The paper focuses on language-conditioned robotic manipulation. Given the current visual observation $\mathbf{o}_t$, the verbal instruction $\ell$, and the optional proprioception $\mathbf{p}_t$, the policy needs to predict the future $k$ step action chunk $\mathbf{a}_{t+1:t+k}$. Traditional goal writing:
This formula is saying: Use expert demonstration data to train a policy so that it gives future action blocks that the expert will do under current observations and instructions.
$$\max_\theta\ \mathbb{E}_{(\mathbf{o}_t,\mathbf{p}_t,\mathbf{a}_{t+1:t+k},\ell)\sim D_{\text{expert}}}\log p_\theta(\mathbf{a}_{t+1:t+k}\mid \mathbf{o}_t,\mathbf{p}_t,\ell).$$| $\mathbf{o}_t$ | The current visual observation belongs to observation space $\mathcal{O}$. |
| $\mathbf{p}_t$ | Robot ontology perception; the footnote of the paper explains that proprioception and action share the representation space in joint position control. |
| $\mathbf{a}_{t+1:t+k}$ | Future action chunks, the length of action chunking is $k$. |
| $\ell$ | Language instructions. |
The paper believes that a general embodied agent not only needs this kind of VLA conditional distribution, but also needs to be able to understand the scene, generate the future, predict the consequences based on the actions, infer the actions based on the video, and generate videos and actions simultaneously. Therefore, the author writes the problem as a unified modeling of five distributions:
| model | distributed | effect |
|---|---|---|
| VLA | $p(\mathbf{a}_{t+1:t+k}\mid \mathbf{o}_t,\ell)$ | Take actions directly from the current image and commands. |
| World Model | $p(\mathbf{o}_{t+1:t+k}\mid \mathbf{o}_t,\mathbf{a}_{t+1:t+k})$ | Given an action, predict future visual consequences. |
| IDM | $p(\mathbf{a}_{t+1:t+k}\mid \mathbf{o}_{t:t+k})$ | Given current and future videos, infer actions. |
| VGM | $p(\mathbf{o}_{t+1:t+k}\mid \mathbf{o}_t,\ell)$ | Given an initial image and language, imagine the task of future videos. |
| Joint | $p(\mathbf{o}_{t+1:t+k},\mathbf{a}_{t+1:t+k}\mid \mathbf{o}_t,\ell)$ | Simultaneously generate future videos and actions. |
2. 2 Limitations of existing methods
The paper divides the bottlenecks of existing methods into two categories. The first category is capability separation: VLAs usually learn policy directly from vision-language input, the video/world-model series emphasizes future prediction, $\mathcal{F}_1$ combines VLA with IDM but does not cover world model or VGM, and UWM covers five types of models but does not fully utilize internet-scale multimodal priors and domain priors in large-scale robot trajectories. The second category is data heterogeneity: cross-robot action spaces are different in dimension, scope, and semantics. Internet videos and egocentric human videos do not have action labels, so it is difficult to use these data directly for action expert pretraining.
The author clearly named these two points as two challenges in Problem Formulation: Challenge 1 is how to unify multi-modal generation capabilities in a framework; Challenge 2 is how to utilize heterogeneous data, especially videos with missing action labels but rich motion information.
2. 3 The solution ideas of this article
The high-level idea of Motus is to "retain expert capabilities and then allow experts to interact under unified generative scheduling. " VGM provides physical and temporal priors, VLM/understanding expert provides visual language understanding and spatial positioning priors, and action expert is responsible for controlling the output. Tri-model Joint Attention allows three types of tokens to interact; UniDiffuser-style scheduler allows the same model to execute VLA, WM, IDM, VGM or Joint mode under different combinations of conditions by setting different noise timesteps for observation/action. For the problem of data heterogeneity, the paper does not forcefully unify the real actions of all robots, but learns latent actions from optical flow, and then uses a small number of action labels and task-agnostic data to bring the latent actions closer to the real control distribution.
3. Summary of related work
3. 1 Related work of the thesis self-description
Unified Multimodal Models。The paper starts from unified multi-modal generation models such as Emu3, Chameleon, Mmada, DualDiffusion, Show-o2, and Janus, and emphasizes that Bagel shares the self-attention layer of understanding expert and generation expert through MoT. Motus draws on this "expert retention + attention interaction" structure, but the application object extends from image and text generation to the embodied setting of video, action, and language.
Embodied foundation model paradigms。OpenVLA, $\pi_{0.5}$, GR00T-N1, etc. use VLM's image and text understanding capabilities for action prediction; UniPi, RoboDreamer, Vidar, etc. use VGM or future video to support world modeling or policy; $\mathcal{F}_1$ explicitly imagines future visual states and then uses IDM to output actions; UWM unifies five robotic modeling forms in a diffusion backbone. The core difference between Motus and UWM is the introduction of universal priors for pre-training VLM/VGM, and the addition of large-scale robot trajectories and latent action pre-training.
Latent Action Models。The paper points out that early latent actions usually use IDM + FDM to reconstruct the next frame from adjacent frames to learn low-dimensional actions, but RGB reconstruction can easily bring in appearance information such as lighting and texture. Subsequent methods reduce redundancy through low-capacity autoencoder, $\beta$-VAE, DINOv2 features, object keypoints, language instructions, or a small number of action labels. Motus chooses optical flow as motion-centric supervision and understands motion as pixel-level displacement.
3. 2 Direct comparison with previous works
| Dimensions | $\mathcal{F}_1$ | UWM | Bagel/MoT class unified model | Motus |
|---|---|---|---|---|
| Core idea | VLA explicitly imagines future vision, and then outputs actions through IDM. | Unify WM, VLA, IDM, VGM, Joint in diffusion backbone. | Sharing attention between comprehension and production experts with MoT. | Put VGM, action expert, and VLM-derived understanding expert into the MoT, and use the scheduler to switch between the five embodied modes. |
| key assumptions | Predicting future images helps in action inference. | The five distributions can be unified by a single diffusion framework. | Experts can retain expertise while blending through attention. | Pretrained VGM/VLM priors can be reused, and actions can be pretrained from unlabeled videos via optical-flow latent actions. |
| deficiency or boundary | Does not override world model or VGM. | There is a lack of sufficient general multimodal priors and priors in large-scale robotics domains. | Not designed for robot action/world model. | Requires three-stage training, optical flow preprocessing, VAE latent action alignment and target robot SFT. |
| Paper report performance | It is not used as the baseline of the main table of this article. | Not used as main table baseline. | As an architecture source rather than a robot baseline. | RoboTwin 2. 0 Clean 88. 66, Randomized 87. 02; the average PSR of the real machine is 63. 22 and 59. 30 respectively on the two platforms. |
4. Detailed explanation of method
4. 1 Method overview
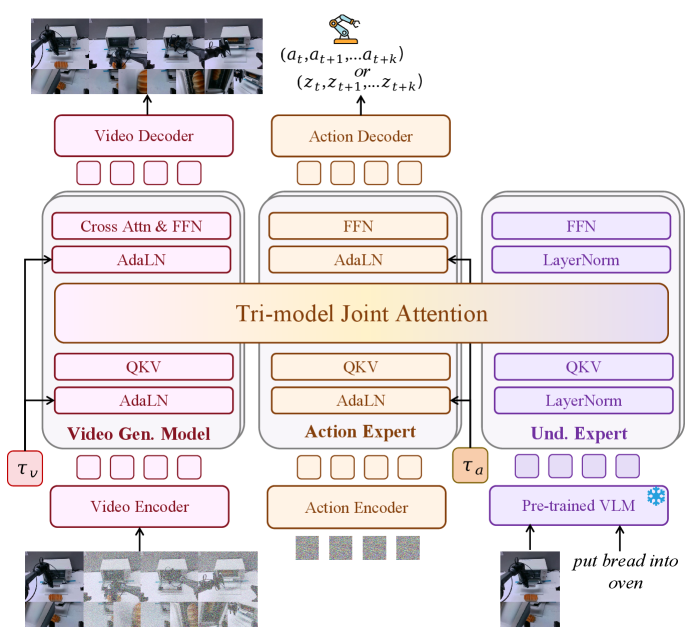
The overall data flow of Motus can be understood separately by training and inference. During training, the model inputs the current observation, language, noisy future observation/action chunk, and the timestep of each observation/action; the model outputs two velocity fields, and uses rectified-flow loss to simultaneously supervise future videos and future actions. During inference, by setting the initial timestep of different modes to clean or noise, the same model can obtain VGM, WM, IDM, VLA or Joint mode.Appendix Training and Inference
4. 2 Method evolution
| stage | Represent ideas | What does this article inherit or change? |
|---|---|---|
| Separate VLA / VGM / WM / IDM | Each ability is trained independently, with different input and output distributions. | Motus writes five distributions as different conditionalized forms of the same multimodal generative model. |
| UWM | Put observation tokens and action tokens into a single diffusion backbone. | Motus does not train a single backbone from scratch, but reuses pre-trained experts such as Wan 2. 2 5B and Qwen3-VL-2B. |
| MoT unified multimodal model | Expert-preserved FFN/blocks are fused via shared attention. | Motus transformed MoT into Tri-model Joint Attention, targeting video/action/language experts. |
| Latent Action | Extracting low-dimensional actions from visual variations. | Motus uses optical flow instead of RGB next-frame reconstruction for more direct motion supervision and aligns the distribution with a small number of ground-truth action labels. |
4. 3 Core design and mathematical derivation
4.3.1 Unified rectified-flow objective
This set of three formulas is doing one thing: let the action branch and observation branch predict the velocity field "from real data to noise", and then add the two errors.
$$ l_{\text{action}}^\theta = \mathbb{E}_{\substack{(\mathbf{o}_{t:t+k}, \mathbf{a}_{t+1:t+k}, \ell)\sim\mathcal{D}\\ \tau_a\sim \mathcal{U}(0,T_\tau),\ \epsilon_a\sim\mathcal{N}(\mathbf{0},\mathbf{I})}} \left\|v_a^\theta-(\epsilon_a-\mathbf{a}_{t+1:t+k})\right\|_2^2 $$ $$ l_{\text{obs}}^\theta = \mathbb{E}_{\substack{(\mathbf{o}_{t:t+k}, \mathbf{a}_{t+1:t+k}, \ell)\sim\mathcal{D}\\ \tau_o\sim \mathcal{U}(0,T_\tau),\ \epsilon_o\sim\mathcal{N}(\mathbf{0},\mathbf{I})}} \left\|v_o^\theta-(\epsilon_o-\mathbf{o}_{t+1:t+k})\right\|_2^2,\quad l^\theta=l_{\text{action}}^\theta+l_{\text{obs}}^\theta. $$| $v_a^\theta, v_o^\theta$ | Action velocity field and observation velocity field predicted by the model. |
| $\epsilon_a,\epsilon_o$ | Action/video noise sampled from standard Gaussian respectively. |
| $\tau_a,\tau_o$ | Separate noise time steps for action and observation; they allow the model to set different condition strengths on different modes. |
| $\epsilon - x^0$ | rectified flow Derivative direction of linear path $x^\tau=(1-\tau)x^0+\tau\epsilon$. |
Why is the target speed $\epsilon-x^0$
Appendix Algorithm 1 Explicitly write $o_{t+1:t+k}^{\tau_o}=(1-\tau_o)o^0_{t+1:t+k}+\tau_o\epsilon_o$ and $a_{t+1:t+k}^{\tau_a}=(1-\tau_a)a^0_{t+1:t+k}+\tau_a\epsilon_a$. Taking the derivative of $\tau$, we get $\frac{d x^\tau}{d\tau}=\epsilon-x^0$. The training goal is therefore to have the model predict the speed of movement along a straight path at any intermediate noise point. During inference, the noise is integrated in the reverse direction to the clean sample. The appendix algorithm uses the form $x^{\tau-1}=x^\tau+v\,d\tau$ to represent discrete updates.
4. 3. 2 How to switch between the five modes of UniDiffuser-style scheduler
Instead of training five separate models, Motus uses the noise level of observation/action to indicate "is this modality a condition or a variable to be generated". If a certain mode is to be used as a condition, its timestep is set to 0, that is, clean; if a certain mode is to be generated, it starts iterative denoising from $T_\tau$ noise.Appendix Algorithms 2-6
| model | clean conditions for the model | Keep variables that are noisy or need to be denoised | output |
|---|---|---|---|
| VGM | $o_t^0,\ell$ | $o_{t+1:t+k}^{T_\tau}$ denoise; $a_{t+1:t+k}^{T_\tau}$ maintain noise | Future Video $o^0_{t+1:t+k}$ |
| World Model | $o_t^0,a^0_{t+1:t+k},\ell$ | $o_{t+1:t+k}^{T_\tau}$ denoising | Future video under action conditions |
| IDM | $o^0_{t:t+k},\ell$ | $a_{t+1:t+k}^{T_\tau}$ denoising | Actions that explain video changes |
| VLA | $o_t^0,\ell$ | $a_{t+1:t+k}^{T_\tau}$ denoise; future observation maintains noise | action chunk |
| Joint | $o_t^0,\ell$ | observation and action simultaneously denoise from noise | Future videos and actions |
4.3.3 Tri-model Joint Attention
Motus contains three experts: Wan 2. 2 5B as the generative expert, Qwen3-VL-2B as the VLM source understanding expert, and an action expert with the same depth as Wan. Each expert retains its own Transformer module and FFN, but the QKV of the self-attention layer is connected into the same Tri-model Joint Attention. The goal is to preserve expert functionality while allowing video tokens, action tokens, and understanding tokens to interact across experts.
Unlike UWM, which directly connects observation/action tokens into the same backbone, Motus' MoT design makes pre-trained VGM/VLM weights easier to utilize. The block of action expert contains AdaLN, FFN and Tri-model Joint Attention; understanding expert uses the last layer of VLM corresponding tokens as input and consists of LayerNorm, FFN and Tri-model Joint Attention.
4.3.4 Action-Dense Video-Sparse Prediction
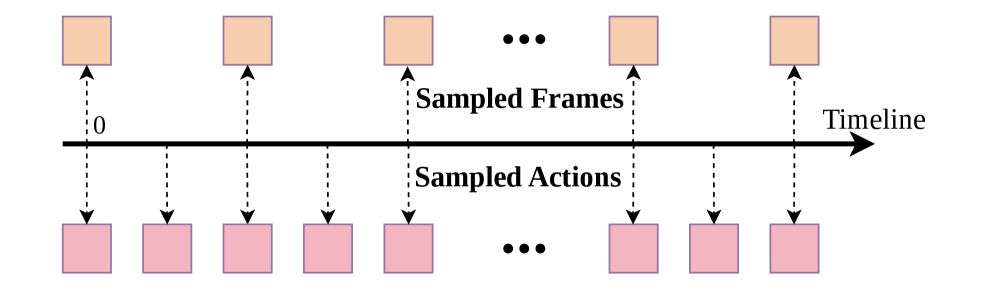
This design solves three things: reduce training/inference overhead; avoid predicting a large number of highly similar future frames; avoid the number of video tokens overwhelming the action tokens in Tri-model Joint Attention, causing the model to focus too much on video prediction and weakening action prediction.
4.3.5 Optical-flow latent action
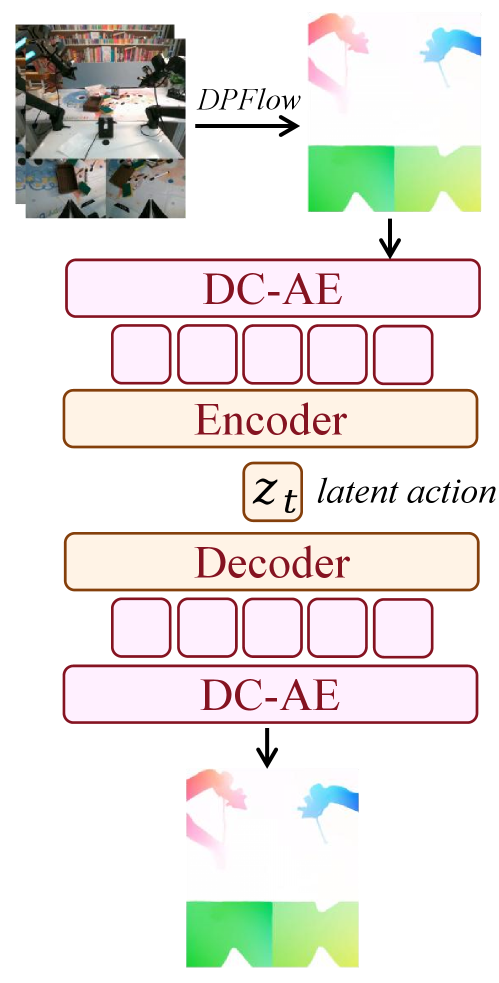
This formula is training latent action VAE: it is necessary to reconstruct the optical flow, align the latent action with the real action, and use KL terms to constrain the latent space.
$$ \mathcal{L}=\mathcal{L}_{\text{recon}}+\lambda_a\|a_{\text{real}}-a_{\text{pred}}\|^2+\beta\mathcal{L}_{\text{KL}}. $$| $\mathcal{L}_{\text{recon}}$ | flow reconstruction error, allowing latent to retain pixel motion information. |
| $a_{\text{real}}$ | Real actions in labeled trajectories or task-agnostic data. |
| $a_{\text{pred}}$ | Action decoded or predicted from latent action. |
| $\lambda_a,\beta$ | The appendix implementation details give $\lambda_a=1.0$, $\beta=10^{-6}$. |
During training, the author mixed 90% unlabeled data for self-supervised reconstruction and 10% labeled trajectories for weak action supervision; the labeled part includes task-agnostic data and standard robot demonstrations. Task-agnostic data adopts the AnyPos idea and uses Curobo to randomly sample the target robot action space to collect image-action pairs, so that the latent space is anchored to the executable control distribution.
4. 4 Implementation points
Model size and key hyperparameters
| components | Configuration | source |
|---|---|---|
| Action Expert | Hidden size 1024;30 layers;24 heads;LayerNorm eps 1e-5;GELU | Implementation Details |
| Understanding Expert | Hidden size 512;30 layers;24 heads;LayerNorm eps 1e-5;GELU | Implementation Details |
| Latent Action VAE | $\lambda_a=1.0$;$\beta=1\times10^{-6}$ | Implementation Details |
| Sampling Rate | Video frames: 8 @ 5Hz;Action chunk: 48 @ 30Hz | Implementation Details |
| Flow Matching | Inference steps 10;sampling strategy: Logit Normal | Implementation Details |
| Model Scale | VGM 5. 00B; VLM 2. 13B; Action Expert 641. 5M; Understanding Expert 253. 5M; Total about 8B | Implementation Details |
Training pseudocode
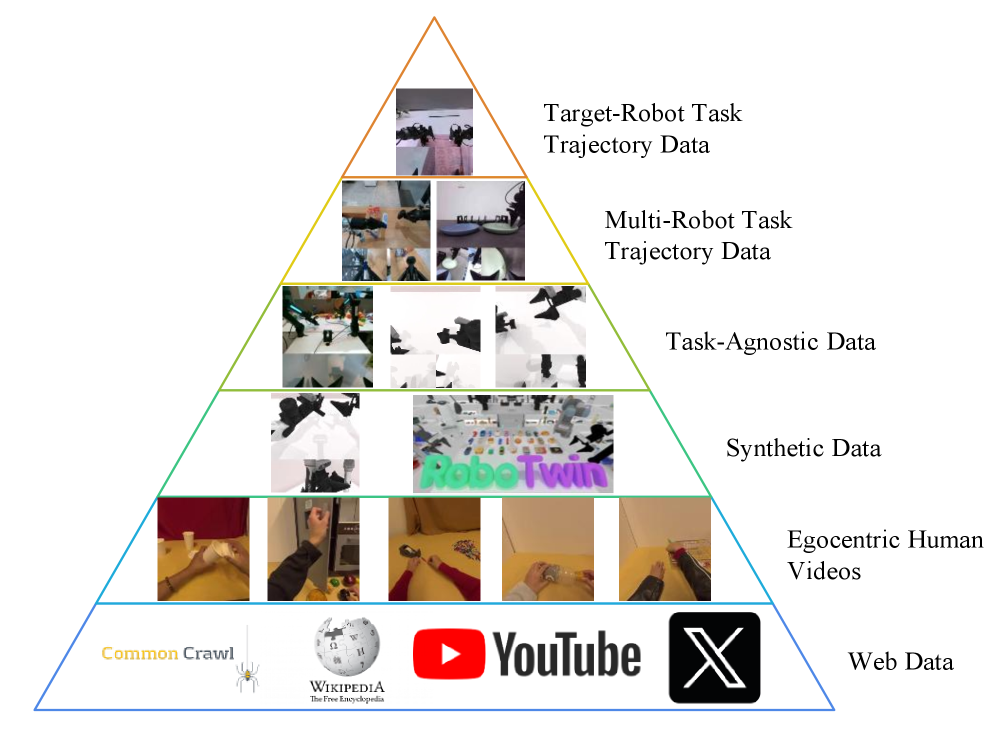
Three-stage training and data pyramid
| stage | data | training object | effect |
|---|---|---|---|
| Off-the-shelf foundation models | Level 1: Web Data | VGM and VLM | Providing general visual, linguistic and video generation priors. |
| Stage 1: Video Generation | Level 2 egocentric human videos;Level 3 synthetic data;Level 5 multi-robot task trajectory data | Only VGM | Adapt VGM to videos of robot operations and future mission execution videos. |
| Stage 2: Unified Training with Latent Actions | Level 2、3、4 task-agnostic data、5 | Motus three experts, using latent actions; VLM frozen | Pre-train action experts and cross-modal interactions with videos, language, and latent actions. |
| Stage 3: SFT | Level 6 target-robot task trajectory data | Motus three experts, using real actions | Adapt target robot specific dynamics and kinematics. |
5. Experiment
5. 1 Experimental setup
| project | set up |
|---|---|
| Simulation benchmark | RoboTwin 2. 0, 50 representative manipulation tasks; each task has 50 demonstrations of clean scenes and 500 demonstrations of randomized scenes, for a total of 2, 500 clean + 25, 000 randomized demonstrations. |
| Simulation randomization | Random background, messy desktop, table height disturbance, random lighting. |
| Simulation training/evaluation | All models start from pre-training checkpoint and finetune 40k steps on RoboTwin data; each task is evaluated with 100 execution trials at success rate. |
| Real machine platform | AC-One and Agilex-Aloha-2 are two dual-arm robot platforms. |
| Real machine mission | Spatial understanding, flexible objects, fine fluid control, visual understanding, long-range planning and other tasks; 100 trajectories for each task training; each platform jointly trains a model for multiple tasks. |
| Real machine indicators | Partial Success Rate, points are given according to subtasks, and full points are awarded for complete success. |
| Baselines | $\pi_{0.5}$, X-VLA; ablation includes w/o Pretrain, Stage1-only/Stage1 Pretrain. |
Complete data set information
| Dataset | Size | Embodiment | Data Level |
|---|---|---|---|
| Egodex | 230,949 | Human | Level 2: Egocentric Human Videos |
| Agibot | 728,209 | Genie-1 Robot | Level 5: Multi-Robot Task Trajectory Data |
| RDT | 6,083 | Aloha Robot | Level 5 |
| RoboMind Franka | 9,589 | Franka Robot | Level 5 |
| RoboMind Aloha | 7,272 | Aloha Robot | Level 5 |
| RoboTwin | 27,500 | Aloha Robot | Level 3: Synthetic Data |
| Task-Agnostic Data | 1,000 | Aloha Robot | Level 4 |
| In-house Data | 2,000 | Aloha Robot | Level 6: Target-Robot Task Trajectory Data |
training configuration
| Configuration | Stage 1 | Stage 2 | Stage 3 |
|---|---|---|---|
| Batch Size | 256 | 256 | 256 |
| Learning Rate | $8\times10^{-5}$ | $5\times10^{-5}$ | $1\sim5\times10^{-5}$ |
| Optimizer | AdamW | AdamW | AdamW |
| Weight Decay | 0.01 | 0.01 | 0.01 |
| GPU Hours | about 8000 | about 10000 | about 400 |
5. 2 Main results
RoboTwin 2.0 simulation
| Model | Clean Avg. (%) | Randomized Avg. (%) | illustrate |
|---|---|---|---|
| GO-1 Appendix Table 14 | 37.80 | 36.24 | Appears only in appendix full comparison. |
| $\pi_{0.5}$ | 42.98 | 43.84 | Main baseline. |
| X-VLA | 72.80 | 72.84 | Strong VLA baseline. |
| w/o Pretrain | 77.56 | 77.00 | Without pre-training ablation; the text short table Clean writes 72. 8, and the appendix full table gives 77. 56. |
| Stage1 | 82.26 | 81.86 | Only do Stage 1 video pretraining. |
| Motus | 88.66 | 87.02 | The Clean and Randomized columns have the highest average. |
The author emphasizes in the text that compared to $\pi_{0.5}$, Motus has an absolute improvement of more than 45 percentage points in RoboTwin 2. 0 randomized multi-task setting; compared to X-VLA, the summary and contribution section reports are improved by about +15%. Appendix Table 14 gives the complete step-by-step results for the 50 tasks, and Table 2 of the main text is a truncated presentation.
Real-world tasks
| Platform | $\pi_{0.5}$ Avg. | w/o Pretrain Avg. | Motus Avg. | key phenomena |
|---|---|---|---|---|
| AC-One | 14.79 | 25.86 | 63.22 | Motus tops in 8 out of 9 tasks; Touch Keyboard tops w/o Pretrain. |
| Agilex-Aloha-2 | 48.60 | 26.60 | 59.30 | Motus is the highest on average; Put Bread into Oven and Touch Keyboard are not the highest. |
Table 4 and Table 5 of the text explain the calculation of the Partial Success Rate using two tasks: AC-One's Put Bread into Oven is scored according to sub-goals such as Open Oven, Grab Bread, Put Bread, Close Oven, Spin Button, etc. ; Agilex-Aloha-2's Get Water from Water Dispenser is scored according to Grab cup, Fill cup, Complete Success. Appendix Table 15 and Table 16 extend subgoal breakdown to all real-world missions.Appendix More Real-World Results
5. 3 Ablation experiment
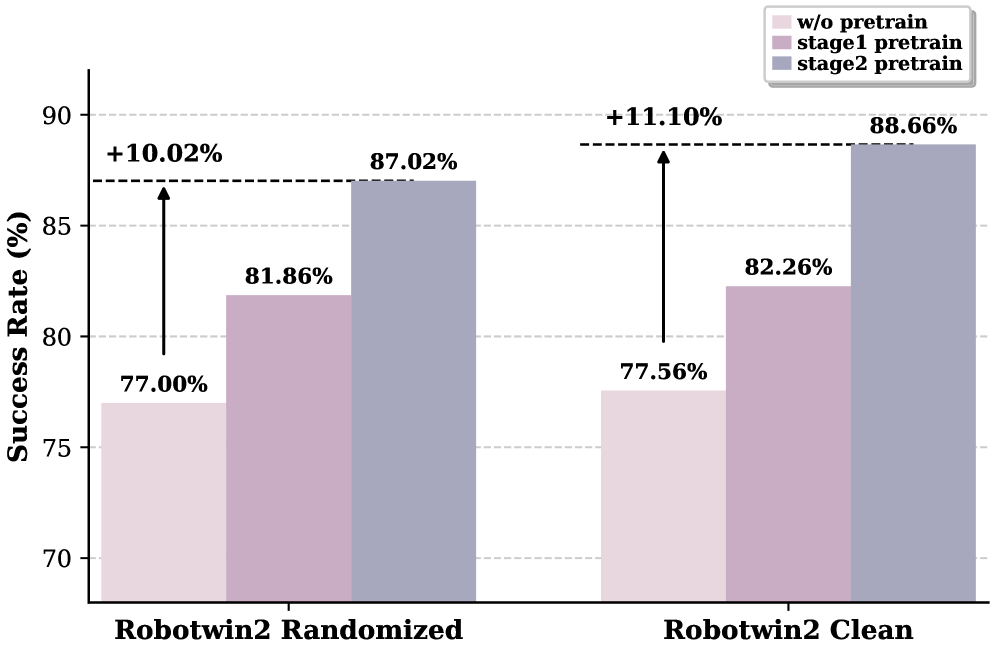
This ablation verifies the pre-training contribution in the three-stage training: Stage 1 is improved compared to no pre-training, and the unified latent-action pretraining of Stage 2 further improves the final success rate. The real experiment w/o Pretrain also appears in Tables 3, 15, and 16 as a control; AC-One improved from 25. 86 to 63. 22 on average, and Agilex-Aloha-2 improved from 26. 60 to 59. 30 on average.
5. 4 Supplementary experiments
Supplementary validation of five modes
| model | Supplementary results | Conclusion scope |
|---|---|---|
| VGM | Agilex-Aloha-2 and AC-One visualizations are shown in Figure 7 and Figure 9 respectively. | Demonstrating video generation capabilities under language and initial image conditions. |
| World Model | Agilex-Aloha-2: FID 9.4571, FVD 49.2848, SSIM 0.88618, LPIPS 0.05449, PSNR 26.1021;AC-One: FID 12.9609, FVD 73.1325, SSIM 0.84605, LPIPS 0.07280, PSNR 24.0379。 | Demonstrating action-conditioned future video prediction quality. |
| IDM | Action MSE: ResNet18+MLP 0.044,DINOv2+MLP 0.122,Motus 0.014。 | Motus' IDM mode is lower than specially trained IDM baselines on this test. |
| VLA | RoboTwin 2.0 randomized average success: Motus (VLA) 83.90,Motus (Joint) 87.02。 | Joint mode is higher than individual VLA mode, but VLA mode is still competitive. |
| Video-Action Joint | Figure 12 shows a visualization of simultaneous video and action generation in real-machine inference. | Supplementary explanation: The same model can simultaneously predict future vision and actions. |






Other benchmarks
| Benchmark | set up | result |
|---|---|---|
| LIBERO-Long | 10 long-range linguistic conditional manipulation tasks in LIBERO-100. | Motus 97. 6, equal to X-VLA 97. 6; higher than $\pi_0$ 85. 2, GR00T-N1 90. 6, UniVLA 94. 0, OpenVLA-OFT 94. 5. |
| VLABench In Distribution | Three tasks: Add Condiment, Select Toy, and Select Fruit. | Motus averaged 0. 48, higher than $\pi_{0.5}$'s average of 0. 43. |
| VLABench Cross Category | Same three tasks, evaluated across categories. | Motus averaged 0. 25, higher than $\pi_{0.5}$'s average of 0. 22. |
6. Result analysis and discussion
6. 1 Interpretation of the results given in the paper
For RoboTwin 2. 0, the author explains that two parts of the design work together: the unified MoT model integrates vision, language and action generation, responding to Challenge 1; latent actions allow the model to utilize labeled and large-scale unlabeled data, improve cross-embodiment generalization and capture motion priors, responding to Challenge 2. The text also emphasizes that the benchmark's random background, cluttered desktop, table height perturbation and lighting perturbation enable it to test generalization under distribution shift.
Regarding the real machine results, the author emphasizes that the tasks of the two platforms include spatial understanding, deformable objects manipulation, precision fluid control, visual understanding, and long-horizon planning. Because the task is divisible and long-term, the paper uses Partial Success Rate instead of just looking at the binary success rate to reflect whether the model completes the key sub-goals.
For the supplementary results of the five modes, the author used the visualization and generation quality indicators of VGM/WM, the action MSE of IDM, and the success rate comparison of VLA and Joint to illustrate that Motus is not just a policy, but performs multiple embodied foundation model functions in the same model.
6. 2 Anomalous or borderline results in the paper
Not every single item on the real task list is Motus-high. AC-One's Touch Instructed Keyboard has a w/o Pretrain of 100 and a Motus of 82. 5; Agilex-Aloha-2's Put Bread into Oven has a $\pi_{0.5}$ of 36 and a Motus of 34; Agilex-Aloha-2's Touch Keyboard has a w/o Pretrain of 85 and a Motus of 80. The paper does not provide additional explanations for these individual items, so the report only records the phenomena in the table without expanding on the reasons.
The appendix VLA vs Joint table shows that Motus (Joint) 87. 02 is higher than Motus (VLA) 83. 90, which shows that the final main result of the paper is stronger using video-action joint prediction mode; however, the author still uses VLA mode as a display of the switchability of the same model.
7. Analysis, Limitations and Boundaries
The most valuable part of this paper
Based on the paper's own claims and experiments, the core value of Motus is to handle the two issues of "unified model" and "available heterogeneous data" in the same technical closed loop. MoT and Tri-model Joint Attention enable VGM/VLM pre-training priors to enter the robot action model; UniDiffuser-style scheduler unifies five conditions/joint distributions into different timestep settings; optical-flow latent action allows videos without action labels to participate in action expert pre-training through motion prior. These three together support the simulation average success rate, real machine PSR, IDM MSE and WM/VGM visualization results.
Why does the result stand?
The results of the paper are supported by multiple complementary levels: RoboTwin 2. 0 uses 50 tasks, two clean/randomized scenarios, 100 trials/task, and limits all models to 40k finetuning steps; the real machine evaluation covers two dual-arm platforms and a variety of long-range/fine tasks, with 100 trajectories per task, and multi-task joint training; the appendix provides a full 50-task table, real machine sub-goal breakdown, LIBERO-Long, VLABench, WM Build quality, IDM MSE, VLA vs Joint comparison and training configuration. Therefore, the main conclusion is not supported by a single benchmark or a single indicator.
Limitations stated by the author
The text under the heading Conclusion and Limitations does not list specific failure cases or negative limitations, but summarizes that Motus unifies vision-language understanding, video generation, inverse dynamics, world modeling and video-action joint prediction, and explains that in the future, it will continue to explore more advanced unified model architectures, more universal motion priors, and learn latent actions from internet-scale general videos. The report does not expand these future work into new recommendations, but only records them as follow-up directions clearly written by the authors.
applicable boundary
- Rely on pre-trained experts.Motus's architecture is built on experts such as Wan 2. 2 5B and Qwen3-VL-2B, and the paper does not take training from scratch as the main path.
- Rely on optical-flow preprocessing.Latent action requires DPFlow to calculate adjacent frame optical flow, which is then compressed by DC-AE and lightweight encoder.
- Target robots still require SFT.Stage 3 uses Level 6 target-robot task trajectory data to adapt latent action or general motion prior to the real action space of the specific embodiment.
- The real machine data size is still 100 trajectories per task.This shows that the real machine results of the paper were obtained under this training scale and two types of dual-arm platform settings.
8. Repeat audit
Code and models
Partially available.The main file of the paper gives the Project Page; retrieves the GitHub link https://github.com/thu-ml/Motus. Whether the complete training code, weights, and data processing scripts are included depends on the current content of the warehouse.
data
The paper lists the data sources and scale.The appendix lists the scale, embodiment, and data pyramid levels of Egodex, Agibot, RDT, RoboMind, RoboTwin, Task-Agnostic Data, and In-house Data. However, the collection details, filtering rules, and original publishing status of In-house Data will affect full reproduction.
training configuration
Key training hyperparameters are given.Batch size, learning rate, optimizer, weight decay, GPU hours, model size, latent VAE weights, sampling rate and flow matching steps are listed in the appendix.
Main steps to reproduce
- Prepare VGM and VLM pre-training experts: Wan 2. 2 5B, Qwen3-VL-2B.
- Use DPFlow to generate optical flow for video data and train latent action VAE: flow reconstruction + action alignment + KL.
- Stage 1 only trains/adapts the VGM to generate future mission videos on robot operation data.
- Stage 2 trains three experts Motus, VLM frozen, input videos, language and latent actions.
- Stage 3 SFT on the target robot's real action trajectories, replacing latent actions with the target robot's actions.
- When evaluating, set the observation/action timestep according to the target mode: the clean mode is set to 0, and the mode to be generated starts from $T_\tau$ noise.
Potential obstacles to recurrence
Computing power and data are the main bottlenecks.The appendix training configuration shows that Stage 1 takes about 8, 000 GPU hours and Stage 2 takes about 10, 000 GPU hours; the total model size is about 8B. Complete reproduction also requires obtaining large-scale multi-source data and in-house target-robot trajectories, and replicating the real robot PSR evaluation protocol.