Motus: A Unified Latent Action World Model
1. 论文速览
难度评级:★★★★☆。阅读需要同时理解 VLA/action chunking、diffusion 或 rectified flow、video generation model、Mixture-of-Transformers、latent action 与机器人评测协议。
关键词:Unified Embodied Foundation Model, Latent Action, World Model, MoT, Rectified Flow, Cross-Embodiment Pretraining。
| 阅读定位 | 内容 |
|---|---|
| 论文要解决什么 | 现有 embodied models 把理解、未来预测、逆动力学、视频生成和动作输出拆成孤立模型;同时大规模视频、人类视角数据和跨机器人轨迹因为动作空间不一致而难以共同训练动作模块。 |
| 作者的方法抓手 | 用 MoT + Tri-model Joint Attention 连接 VGM、action expert、understanding expert;用不同模态 timesteps 的 UniDiffuser-style scheduler 切换五种建模模式;用 optical flow 训练 latent action,把像素运动压缩到接近控制维度的空间。 |
| 最重要的结果 | RoboTwin 2.0 平均成功率达到 Clean 88.66%、Randomized 87.02%,相对 $\pi_{0.5}$ 绝对提升约 45 个点;真实 AC-One 平均 PSR 63.22%,Agilex-Aloha-2 平均 PSR 59.30%。 |
| 阅读时要注意的点 | Motus 的“统一”不是把所有数据直接拼接进一个普通 Transformer,而是通过专家保留、joint attention 交互、模态噪声调度和 latent action 对齐共同实现;附录算法说明了五种模式如何由同一个 rectified-flow 模型切换。 |
核心贡献清单
- 统一五种 embodied modeling paradigms。论文把 WM、IDM、VLA、VGM、Video-Action Joint Prediction 放入一个生成式模型框架中;这意味着同一模型既可以预测视频,也可以预测动作,或同时预测两者。
- MoT + Tri-model Joint Attention。VGM、action expert、understanding expert 各自保留 Transformer 模块,同时在 multi-head self-attention 层进行拼接式交互;这意味着模型可以利用预训练 VGM/VLM 的先验而不是从零训练统一 backbone。
- Optical-flow latent action。作者把 optical flow 当作像素级 delta action,经 DC-AE 和轻量 encoder 压缩为 14 维 latent action;这意味着没有真实动作标签的视频也能提供动作相关运动监督。
- 三阶段训练与六层数据金字塔。Stage 1 适配 VGM,Stage 2 用 latent actions 统一训练,Stage 3 用目标机器人真动作 SFT;这意味着数据从 web/egocentric/synthetic/multi-robot/target-robot 分层进入训练流程。
- 仿真和真机验证。论文在 RoboTwin 2.0、LIBERO-Long、VLABench 与两类真实双臂平台上报告结果;这意味着作者不仅验证 VLA policy,也展示了 VGM、WM、IDM 等模式的补充能力。
2. 动机
2.1 要解决什么问题
论文关注 language-conditioned robotic manipulation。给定当前视觉观测 $\mathbf{o}_t$、语言指令 $\ell$,以及可选的 proprioception $\mathbf{p}_t$,策略需要预测未来 $k$ 步 action chunk $\mathbf{a}_{t+1:t+k}$。传统目标写作:
这个公式在说:用专家演示数据训练一个策略,让它在当前观测和指令下给出专家会做的未来动作块。
$$\max_\theta\ \mathbb{E}_{(\mathbf{o}_t,\mathbf{p}_t,\mathbf{a}_{t+1:t+k},\ell)\sim D_{\text{expert}}}\log p_\theta(\mathbf{a}_{t+1:t+k}\mid \mathbf{o}_t,\mathbf{p}_t,\ell).$$| $\mathbf{o}_t$ | 当前视觉观测,属于 observation space $\mathcal{O}$。 |
| $\mathbf{p}_t$ | 机器人本体感知;论文脚注说明在 joint position control 中 proprioception 与 action 共享表示空间。 |
| $\mathbf{a}_{t+1:t+k}$ | 未来动作块,action chunking 的长度为 $k$。 |
| $\ell$ | 语言指令。 |
论文认为一个通用 embodied agent 不只需要这一种 VLA 条件分布,还需要能理解场景、生成未来、根据动作预测后果、根据视频反推出动作,以及同时生成视频和动作。因此作者把问题写成五种分布的统一建模:
| 模式 | 分布 | 作用 |
|---|---|---|
| VLA | $p(\mathbf{a}_{t+1:t+k}\mid \mathbf{o}_t,\ell)$ | 从当前图像和指令直接出动作。 |
| World Model | $p(\mathbf{o}_{t+1:t+k}\mid \mathbf{o}_t,\mathbf{a}_{t+1:t+k})$ | 给定动作,预测未来视觉后果。 |
| IDM | $p(\mathbf{a}_{t+1:t+k}\mid \mathbf{o}_{t:t+k})$ | 给定当前和未来视频,反推出动作。 |
| VGM | $p(\mathbf{o}_{t+1:t+k}\mid \mathbf{o}_t,\ell)$ | 给定初始图像和语言,想象任务未来视频。 |
| Joint | $p(\mathbf{o}_{t+1:t+k},\mathbf{a}_{t+1:t+k}\mid \mathbf{o}_t,\ell)$ | 同时生成未来视频和动作。 |
2.2 已有方法的局限
论文把已有方法的瓶颈分成两类。第一类是能力割裂:VLAs 通常从 vision-language 输入直接学 policy,video/world-model 系列强调未来预测,$\mathcal{F}_1$ 结合 VLA 和 IDM 但不覆盖 world model 或 VGM,UWM 覆盖五类模型但没有充分利用 internet-scale multimodal priors 与大规模机器人轨迹中的领域先验。第二类是数据异构:跨机器人 action space 在维度、范围和语义上都不同,互联网视频和 egocentric human videos 又没有 action labels,因此很难把这些数据直接用于 action expert pretraining。
作者在 Problem Formulation 中把这两点明确命名为两个挑战:Challenge 1 是如何在一个框架里统一多模态生成能力;Challenge 2 是如何利用 heterogeneous data,尤其是动作标签缺失但含有丰富运动信息的视频。
2.3 本文的解决思路
Motus 的高层思路是“保留专家能力,再让专家在统一生成式调度下交互”。VGM 提供物理和时序先验,VLM/understanding expert 提供视觉语言理解与空间定位先验,action expert 负责控制输出。Tri-model Joint Attention 让三类 token 交互;UniDiffuser-style scheduler 通过给 observation/action 设置不同噪声 timestep,让同一个模型在不同条件组合下执行 VLA、WM、IDM、VGM 或 Joint mode。对数据异构问题,论文不强行统一所有机器人的真实动作,而是从 optical flow 中学习 latent action,再通过少量动作标签和 task-agnostic data 把 latent action 拉近真实控制分布。
3. 相关工作梳理
3.1 论文自述的相关工作
Unified Multimodal Models。论文从 Emu3、Chameleon、Mmada、DualDiffusion、Show-o2、Janus 等统一多模态生成模型切入,强调 Bagel 通过 MoT 共享 understanding expert 和 generation expert 的 self-attention 层。Motus 借鉴的是这种“专家保留 + attention 交互”的结构,但应用对象从图文生成扩展到 video、action、language 的 embodied setting。
Embodied foundation model paradigms。OpenVLA、$\pi_{0.5}$、GR00T-N1 等使用 VLM 的图文理解能力做 action prediction;UniPi、RoboDreamer、Vidar 等使用 VGM 或未来视频来支持 world modeling 或 policy;$\mathcal{F}_1$ 通过显式想象未来视觉状态再用 IDM 输出动作;UWM 在一个 diffusion backbone 中统一五种 robotic modeling forms。Motus 与 UWM 的核心区别是引入预训练 VLM/VGM 的通用先验,并加入大规模机器人轨迹和 latent action 预训练。
Latent Action Models。论文指出早期 latent action 通常通过 IDM + FDM,从相邻帧重建 next frame 来学低维动作,但 RGB 重建容易带入光照、纹理等外观信息。后续方法通过低容量 autoencoder、$\beta$-VAE、DINOv2 features、object keypoints、language instructions 或少量 action labels 降低冗余。Motus 选择 optical flow 作为 motion-centric supervision,把动作理解为 pixel-level displacement。
3.2 直接前作对比
| 维度 | $\mathcal{F}_1$ | UWM | Bagel/MoT 类统一模型 | Motus |
|---|---|---|---|---|
| 核心思路 | VLA 显式想象未来视觉,再通过 IDM 输出动作。 | 在 diffusion backbone 中统一 WM、VLA、IDM、VGM、Joint。 | 用 MoT 让理解和生成专家共享注意力。 | 把 VGM、action expert、VLM-derived understanding expert 放入 MoT,并用 scheduler 切换五种 embodied modes。 |
| 关键假设 | 预测未来图像有助于动作推断。 | 五种分布可用单一扩散框架统一。 | 专家可以保留专长,同时通过 attention 融合。 | 预训练 VGM/VLM 先验可复用,动作可通过 optical-flow latent action 从无标签视频中预训练。 |
| 不足或边界 | 不覆盖 world model 或 VGM。 | 缺少充分的通用多模态先验和大规模机器人领域先验。 | 不是针对机器人动作/世界模型设计。 | 需要三阶段训练、光流预处理、VAE latent action 对齐和目标机器人 SFT。 |
| 论文报告性能 | 未作为本文主表 baseline。 | 未作为主表 baseline。 | 作为架构来源而非机器人 baseline。 | RoboTwin 2.0 Clean 88.66、Randomized 87.02;真机平均 PSR 在两平台上分别 63.22、59.30。 |
4. 方法详解
4.1 方法概览
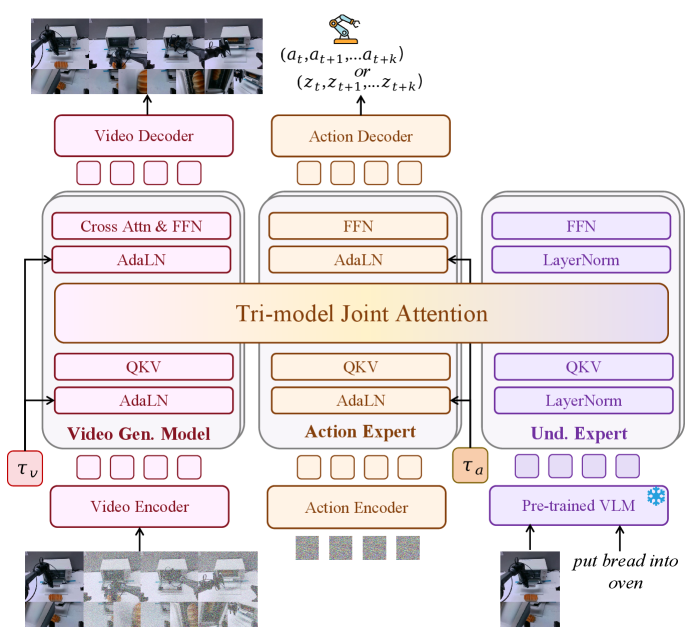
Motus 的整体数据流可以按训练和推理分开理解。训练时,模型输入当前观测、语言、带噪未来 observation/action chunk,以及 observation/action 各自的 timestep;模型输出两个 velocity fields,用 rectified-flow loss 同时监督未来视频和未来动作。推理时,通过设置不同模态的初始 timestep 为 clean 或 noise,同一个模型就能得到 VGM、WM、IDM、VLA 或 Joint mode。附录 Training and Inference
4.2 方法演变脉络
| 阶段 | 代表思路 | 本文继承或改变了什么 |
|---|---|---|
| 分离式 VLA / VGM / WM / IDM | 每个能力独立训练,输入输出分布不同。 | Motus 把五种分布写成同一个多模态生成模型的不同条件化形式。 |
| UWM | 把 observation tokens 和 action tokens 放进单一 diffusion backbone。 | Motus 不从零训练单一 backbone,而是复用 Wan 2.2 5B、Qwen3-VL-2B 等预训练专家。 |
| MoT 统一多模态模型 | 专家保留 FFN/blocks,通过共享 attention 融合。 | Motus 将 MoT 改造为 Tri-model Joint Attention,面向 video/action/language 三类专家。 |
| Latent Action | 从视觉变化中提取低维动作。 | Motus 用 optical flow 而不是 RGB next-frame reconstruction 作为更直接的运动监督,并用少量真实动作标签对齐分布。 |
4.3 核心设计与数学推导
4.3.1 Unified rectified-flow objective
这组三个公式在做一件事:分别让 action 分支和 observation 分支预测“从真实数据走向噪声”的速度场,然后把两个误差相加。
$$ l_{\text{action}}^\theta = \mathbb{E}_{\substack{(\mathbf{o}_{t:t+k}, \mathbf{a}_{t+1:t+k}, \ell)\sim\mathcal{D}\\ \tau_a\sim \mathcal{U}(0,T_\tau),\ \epsilon_a\sim\mathcal{N}(\mathbf{0},\mathbf{I})}} \left\|v_a^\theta-(\epsilon_a-\mathbf{a}_{t+1:t+k})\right\|_2^2 $$ $$ l_{\text{obs}}^\theta = \mathbb{E}_{\substack{(\mathbf{o}_{t:t+k}, \mathbf{a}_{t+1:t+k}, \ell)\sim\mathcal{D}\\ \tau_o\sim \mathcal{U}(0,T_\tau),\ \epsilon_o\sim\mathcal{N}(\mathbf{0},\mathbf{I})}} \left\|v_o^\theta-(\epsilon_o-\mathbf{o}_{t+1:t+k})\right\|_2^2,\quad l^\theta=l_{\text{action}}^\theta+l_{\text{obs}}^\theta. $$| $v_a^\theta, v_o^\theta$ | 模型预测的 action velocity field 与 observation velocity field。 |
| $\epsilon_a,\epsilon_o$ | 分别采样自标准高斯的 action/video 噪声。 |
| $\tau_a,\tau_o$ | action 和 observation 的独立噪声时间步;它们允许模型在不同模态上设置不同条件强度。 |
| $\epsilon - x^0$ | rectified flow 线性路径 $x^\tau=(1-\tau)x^0+\tau\epsilon$ 的导数方向。 |
为什么目标速度是 $\epsilon-x^0$
附录 Algorithm 1 显式写出 $o_{t+1:t+k}^{\tau_o}=(1-\tau_o)o^0_{t+1:t+k}+\tau_o\epsilon_o$ 和 $a_{t+1:t+k}^{\tau_a}=(1-\tau_a)a^0_{t+1:t+k}+\tau_a\epsilon_a$。对 $\tau$ 求导,得到 $\frac{d x^\tau}{d\tau}=\epsilon-x^0$。因此训练目标让模型在任意中间噪声点预测沿直线路径移动的速度。推理时从噪声沿反方向积分到 clean sample,附录算法用 $x^{\tau-1}=x^\tau+v\,d\tau$ 形式表示离散更新。
4.3.2 UniDiffuser-style scheduler 如何切换五种模式
Motus 不是训练五个单独模型,而是用 observation/action 的 noise level 表示“这个模态是条件还是要生成的变量”。如果某个模态要作为条件,它的 timestep 设为 0,即 clean;如果某个模态要生成,它从 $T_\tau$ 噪声开始迭代去噪。附录 Algorithms 2-6
| 模式 | 给模型的 clean 条件 | 保持 noisy 或需要去噪的变量 | 输出 |
|---|---|---|---|
| VGM | $o_t^0,\ell$ | $o_{t+1:t+k}^{T_\tau}$ 去噪;$a_{t+1:t+k}^{T_\tau}$ 维持噪声 | 未来视频 $o^0_{t+1:t+k}$ |
| World Model | $o_t^0,a^0_{t+1:t+k},\ell$ | $o_{t+1:t+k}^{T_\tau}$ 去噪 | 动作条件下的未来视频 |
| IDM | $o^0_{t:t+k},\ell$ | $a_{t+1:t+k}^{T_\tau}$ 去噪 | 解释视频变化的动作 |
| VLA | $o_t^0,\ell$ | $a_{t+1:t+k}^{T_\tau}$ 去噪;未来 observation 保持噪声 | 动作 chunk |
| Joint | $o_t^0,\ell$ | observation 和 action 同时从噪声去噪 | 未来视频和动作 |
4.3.3 Tri-model Joint Attention
Motus 包含三个专家:Wan 2.2 5B 作为 generative expert,Qwen3-VL-2B 作为 VLM 来源的 understanding expert,以及一个与 Wan 深度相同的 action expert。每个专家保留自己的 Transformer 模块和 FFN,但 self-attention 层的 QKV 被连接到同一个 Tri-model Joint Attention 中。这样做的目标是保留专家职能,同时允许 video tokens、action tokens 和 understanding tokens 跨专家交互。
与 UWM 直接串接 observation/action tokens 进入同一 backbone 不同,Motus 的 MoT 设计让预训练 VGM/VLM 权重更容易被利用。action expert 的 block 包含 AdaLN、FFN 和 Tri-model Joint Attention;understanding expert 使用 VLM 最后一层对应 tokens 作为输入,并由 LayerNorm、FFN、Tri-model Joint Attention 组成。
4.3.4 Action-Dense Video-Sparse Prediction
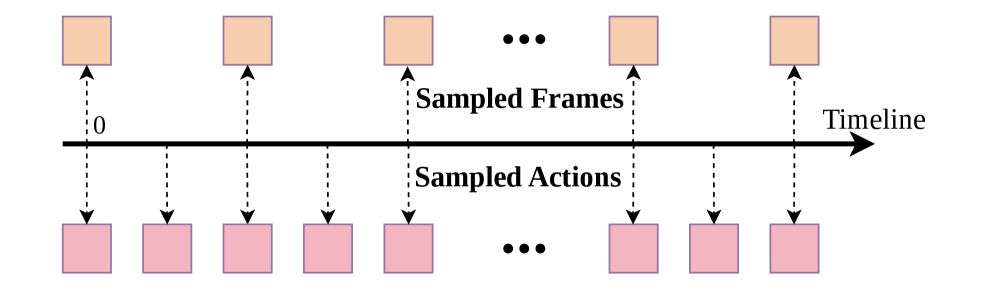
这个设计解决三件事:降低训练/推理开销;避免预测大量高度相似的未来帧;避免 Tri-model Joint Attention 中 video tokens 数量压倒 action tokens,导致模型过度关注视频预测而削弱动作预测。
4.3.5 Optical-flow latent action
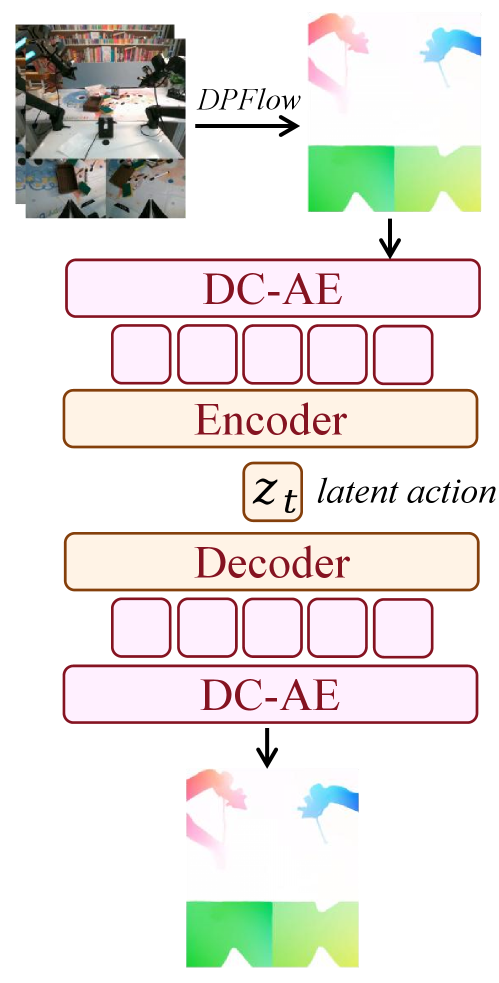
这个公式在训练 latent action VAE:既要重建光流,又要让 latent action 对齐真实动作,还要用 KL 项约束 latent 空间。
$$ \mathcal{L}=\mathcal{L}_{\text{recon}}+\lambda_a\|a_{\text{real}}-a_{\text{pred}}\|^2+\beta\mathcal{L}_{\text{KL}}. $$| $\mathcal{L}_{\text{recon}}$ | flow reconstruction error,让 latent 保留像素运动信息。 |
| $a_{\text{real}}$ | 带标签轨迹或 task-agnostic data 中的真实动作。 |
| $a_{\text{pred}}$ | 从 latent action 解码或预测得到的动作。 |
| $\lambda_a,\beta$ | 附录实现细节给出 $\lambda_a=1.0$,$\beta=10^{-6}$。 |
训练时作者混合 90% unlabeled data 做 self-supervised reconstruction,与 10% labeled trajectories 做 weak action supervision;labeled 部分包括 task-agnostic data 和标准机器人演示。task-agnostic data 采用 AnyPos 思路,用 Curobo 随机采样目标机器人动作空间来收集 image-action pairs,使 latent space 被锚定到可执行控制分布。
4.4 实现要点
模型规模与关键超参数
| 组件 | 配置 | 来源 |
|---|---|---|
| Action Expert | Hidden size 1024;30 layers;24 heads;LayerNorm eps 1e-5;GELU | Implementation Details |
| Understanding Expert | Hidden size 512;30 layers;24 heads;LayerNorm eps 1e-5;GELU | Implementation Details |
| Latent Action VAE | $\lambda_a=1.0$;$\beta=1\times10^{-6}$ | Implementation Details |
| Sampling Rate | Video frames: 8 @ 5Hz;Action chunk: 48 @ 30Hz | Implementation Details |
| Flow Matching | Inference steps 10;sampling strategy: Logit Normal | Implementation Details |
| Model Scale | VGM 5.00B;VLM 2.13B;Action Expert 641.5M;Understanding Expert 253.5M;Total 约 8B | Implementation Details |
训练伪代码
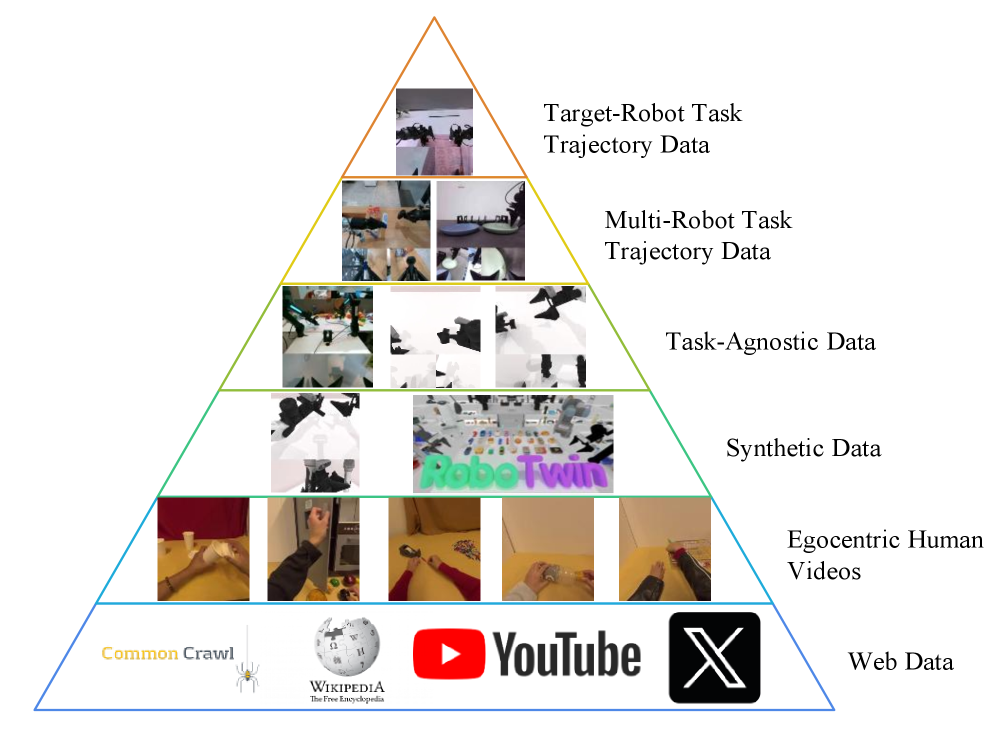
三阶段训练和数据金字塔
| 阶段 | 数据 | 训练对象 | 作用 |
|---|---|---|---|
| Off-the-shelf foundation models | Level 1: Web Data | VGM and VLM | 提供通用视觉、语言和视频生成先验。 |
| Stage 1: Video Generation | Level 2 egocentric human videos;Level 3 synthetic data;Level 5 multi-robot task trajectory data | Only VGM | 让 VGM 适配机器人操作视频和未来任务执行视频。 |
| Stage 2: Unified Training with Latent Actions | Level 2、3、4 task-agnostic data、5 | Motus 三个 experts,使用 latent actions;VLM frozen | 用 videos、language、latent actions 预训练 action expert 和跨模态交互。 |
| Stage 3: SFT | Level 6 target-robot task trajectory data | Motus 三个 experts,使用真实 actions | 适配目标机器人具体动力学和运动学。 |
5. 实验
5.1 实验设置
| 项目 | 设置 |
|---|---|
| 仿真 benchmark | RoboTwin 2.0,50 个代表性 manipulation tasks;每个任务 clean scenes 50 demonstrations,randomized scenes 500 demonstrations,总计 2,500 clean + 25,000 randomized demonstrations。 |
| 仿真随机化 | 随机背景、杂乱桌面、桌高扰动、随机光照。 |
| 仿真训练/评测 | 所有模型从预训练 checkpoint 开始,在 RoboTwin 数据上 finetune 40k steps;每个任务 100 execution trials,以 success rate 评估。 |
| 真机平台 | AC-One 与 Agilex-Aloha-2 两个双臂机器人平台。 |
| 真机任务 | 空间理解、柔性物体、精细流体控制、视觉理解、长程规划等任务;每个任务 100 trajectories 训练;每个平台多任务联合训练一个模型。 |
| 真机指标 | Partial Success Rate,按子任务给分,完整成功得满分。 |
| Baselines | $\pi_{0.5}$、X-VLA;消融包括 w/o Pretrain、Stage1-only/Stage1 Pretrain。 |
完整数据集信息
| Dataset | Size | Embodiment | Data Level |
|---|---|---|---|
| Egodex | 230,949 | Human | Level 2: Egocentric Human Videos |
| Agibot | 728,209 | Genie-1 Robot | Level 5: Multi-Robot Task Trajectory Data |
| RDT | 6,083 | Aloha Robot | Level 5 |
| RoboMind Franka | 9,589 | Franka Robot | Level 5 |
| RoboMind Aloha | 7,272 | Aloha Robot | Level 5 |
| RoboTwin | 27,500 | Aloha Robot | Level 3: Synthetic Data |
| Task-Agnostic Data | 1,000 | Aloha Robot | Level 4 |
| In-house Data | 2,000 | Aloha Robot | Level 6: Target-Robot Task Trajectory Data |
训练配置
| 配置 | Stage 1 | Stage 2 | Stage 3 |
|---|---|---|---|
| Batch Size | 256 | 256 | 256 |
| Learning Rate | $8\times10^{-5}$ | $5\times10^{-5}$ | $1\sim5\times10^{-5}$ |
| Optimizer | AdamW | AdamW | AdamW |
| Weight Decay | 0.01 | 0.01 | 0.01 |
| GPU Hours | 约 8000 | 约 10000 | 约 400 |
5.2 主要结果
RoboTwin 2.0 simulation
| Model | Clean Avg. (%) | Randomized Avg. (%) | 说明 |
|---|---|---|---|
| GO-1 附录 Table 14 | 37.80 | 36.24 | 仅在附录 full comparison 中出现。 |
| $\pi_{0.5}$ | 42.98 | 43.84 | 主 baseline。 |
| X-VLA | 72.80 | 72.84 | 强 VLA baseline。 |
| w/o Pretrain | 77.56 | 77.00 | 无预训练消融;正文短表 Clean 写作 72.8,附录 full table 给出 77.56。 |
| Stage1 | 82.26 | 81.86 | 只做 Stage 1 video pretraining。 |
| Motus | 88.66 | 87.02 | Clean 和 Randomized 两列平均最高。 |
作者在正文强调,相比 $\pi_{0.5}$,Motus 在 RoboTwin 2.0 randomized multi-task setting 上有超过 45 个百分点的绝对提升;相比 X-VLA,摘要和贡献段报告约 +15% 改善。附录 Table 14 给出 50 个任务的完整逐项结果,正文 Table 2 是截断展示。
Real-world tasks
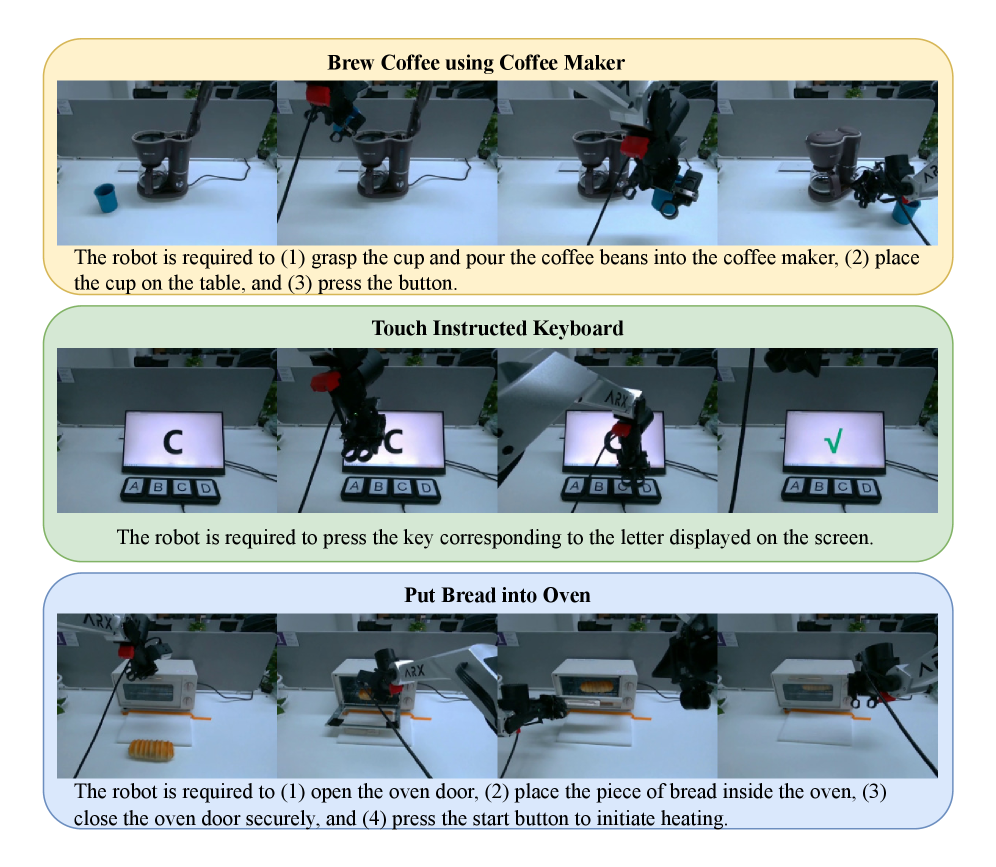
| Platform | $\pi_{0.5}$ Avg. | w/o Pretrain Avg. | Motus Avg. | 关键现象 |
|---|---|---|---|---|
| AC-One | 14.79 | 25.86 | 63.22 | Motus 在 9 个任务中的 8 个最高;Touch Keyboard 由 w/o Pretrain 最高。 |
| Agilex-Aloha-2 | 48.60 | 26.60 | 59.30 | Motus 平均最高;Put Bread into Oven 和 Touch Keyboard 不是最高。 |
正文 Table 4 和 Table 5 用两个任务解释 Partial Success Rate 的计算:AC-One 的 Put Bread into Oven 按 Open Oven、Grab Bread、Put Bread、Close Oven、Spin Button 等子目标给分;Agilex-Aloha-2 的 Get Water from Water Dispenser 按 Grab cup、Fill cup、Complete Success 给分。附录 Table 15 和 Table 16 扩展到所有真机任务的子目标 breakdown。附录 More Real-World Results
5.3 消融实验
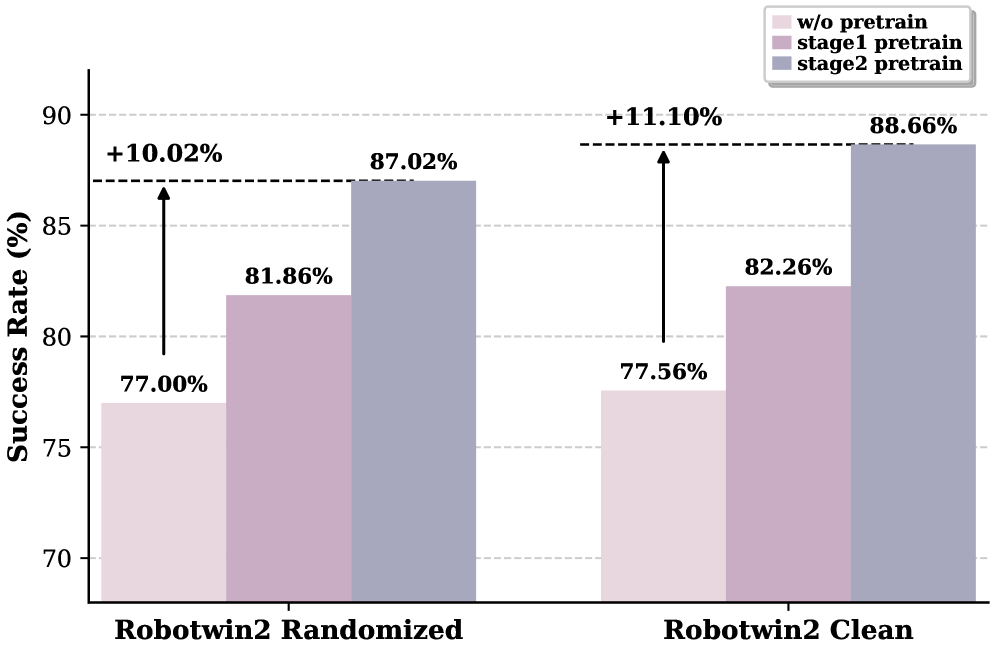
该消融验证三阶段训练中的预训练贡献:Stage 1 相比无预训练有提升,Stage 2 的 unified latent-action pretraining 进一步提高最终成功率。真实实验中 w/o Pretrain 也作为对照出现在 Table 3、15、16 中;AC-One 平均从 25.86 提升到 63.22,Agilex-Aloha-2 平均从 26.60 提升到 59.30。
5.4 补充实验
五种模式的补充验证
| 模式 | 补充结果 | 结论范围 |
|---|---|---|
| VGM | Agilex-Aloha-2 与 AC-One 可视化分别见 Figure 7 和 Figure 9。 | 展示语言和初始图像条件下的视频生成能力。 |
| World Model | Agilex-Aloha-2: FID 9.4571, FVD 49.2848, SSIM 0.88618, LPIPS 0.05449, PSNR 26.1021;AC-One: FID 12.9609, FVD 73.1325, SSIM 0.84605, LPIPS 0.07280, PSNR 24.0379。 | 展示动作条件未来视频预测质量。 |
| IDM | Action MSE: ResNet18+MLP 0.044,DINOv2+MLP 0.122,Motus 0.014。 | Motus 的 IDM mode 在该测试上低于专门训练的 IDM baselines。 |
| VLA | RoboTwin 2.0 randomized average success: Motus (VLA) 83.90,Motus (Joint) 87.02。 | Joint mode 高于单独 VLA mode,但 VLA mode 仍具备竞争力。 |
| Video-Action Joint | Figure 12 展示真机推理中同时生成视频和动作的可视化。 | 补充说明同一模型可同步预测未来视觉与动作。 |






其他 benchmark
| Benchmark | 设置 | 结果 |
|---|---|---|
| LIBERO-Long | LIBERO-100 中 10 个长程语言条件操作任务。 | Motus 97.6,等于 X-VLA 97.6;高于 $\pi_0$ 85.2、GR00T-N1 90.6、UniVLA 94.0、OpenVLA-OFT 94.5。 |
| VLABench In Distribution | Add Condiment、Select Toy、Select Fruit 三个任务。 | Motus 平均 0.48,高于 $\pi_{0.5}$ 平均 0.43。 |
| VLABench Cross Category | 同三任务,跨类别评估。 | Motus 平均 0.25,高于 $\pi_{0.5}$ 平均 0.22。 |
6. 结果分析与讨论
6.1 论文已给出的结果解释
对 RoboTwin 2.0,作者解释为两部分设计共同作用:统一 MoT 模型整合 vision、language 和 action generation,回应 Challenge 1;latent actions 让模型利用 labeled 和 large-scale unlabeled data,提升跨 embodiment 泛化并捕获 motion priors,回应 Challenge 2。正文还强调该 benchmark 的随机背景、杂乱桌面、桌高扰动和光照扰动使其能检验 distribution shift 下的泛化。
对真机结果,作者强调两平台任务包含 spatial understanding、deformable objects manipulation、precision fluid control、visual understanding、long-horizon planning。因为任务可拆分且长程,论文使用 Partial Success Rate,而不是只看二值成功率,以反映模型是否完成关键子目标。
对五种模式的补充结果,作者分别用 VGM/WM 的可视化和生成质量指标、IDM 的 action MSE、VLA 与 Joint 的成功率对比,说明 Motus 不只是 policy,而是在同一模型中执行多种 embodied foundation model 功能。
6.2 论文中的反常或边界结果
真实任务表中并非每个单项都是 Motus 最高。AC-One 的 Touch Instructed Keyboard 中 w/o Pretrain 为 100,Motus 为 82.5;Agilex-Aloha-2 的 Put Bread into Oven 中 $\pi_{0.5}$ 为 36,Motus 为 34;Agilex-Aloha-2 的 Touch Keyboard 中 w/o Pretrain 为 85,Motus 为 80。论文没有对这些单项给出额外解释,因此报告只记录为表中现象,不扩展原因。
附录 VLA vs Joint 表显示 Motus (Joint) 87.02 高于 Motus (VLA) 83.90,这说明论文最终主结果使用 video-action joint prediction mode 更强;但作者仍把 VLA mode 作为同一模型可切换能力展示。
7. 分析、局限与边界
这篇论文最有价值的地方
基于论文自身主张和实验,Motus 的核心价值在于把“统一模型”和“可利用异构数据”两个问题放在同一个技术闭环里处理。MoT 与 Tri-model Joint Attention 使 VGM/VLM 预训练先验能够进入机器人动作模型;UniDiffuser-style scheduler 把五种条件/联合分布统一为不同 timestep 设置;optical-flow latent action 让无动作标签视频可以通过 motion prior 参与 action expert 预训练。这三者共同支撑了仿真平均成功率、真机 PSR、IDM MSE 和 WM/VGM 可视化结果。
结果为什么站得住
论文的结果支撑来自多个互补层面:RoboTwin 2.0 使用 50 个任务、clean/randomized 两种场景、100 trials/task,并限制所有模型 40k finetuning steps;真机评测覆盖两个双臂平台和多种长程/精细任务,每任务 100 trajectories,多任务联合训练;附录给出了 full 50-task table、真机子目标 breakdown、LIBERO-Long、VLABench、WM 生成质量、IDM MSE、VLA vs Joint 对比和训练配置。因此,主结论不是只由单一 benchmark 或单一指标支撑。
作者自述的局限性
Conclusion and Limitations 标题下的正文没有列出具体失败案例或负面限制,而是总结 Motus 统一了 vision-language understanding、video generation、inverse dynamics、world modeling 和 video-action joint prediction,并说明未来将继续探索更先进的 unified model architectures、更 universal 的 motion priors,以及从 internet-scale general videos 中学习 latent actions。报告不把这些未来工作扩展为新的建议,只记录为作者明确写出的后续方向。
适用边界
- 依赖预训练专家。Motus 的架构建立在 Wan 2.2 5B 和 Qwen3-VL-2B 等专家之上,论文没有把从零训练作为主要路径。
- 依赖 optical-flow preprocessing。Latent action 需要 DPFlow 计算相邻帧光流,再由 DC-AE 和轻量 encoder 压缩。
- 目标机器人仍需 SFT。Stage 3 使用 Level 6 target-robot task trajectory data,把 latent action 或通用 motion prior 适配到具体 embodiment 的真实动作空间。
- 真机数据规模仍是每任务 100 trajectories。这说明论文的真机结果是在该训练规模和两类双臂平台设置下得到的。
8. 复现审计
代码与模型
部分可查。论文主文件给出 Project Page;检索到 GitHub 链接 https://github.com/thu-ml/Motus。是否包含完整训练代码、权重和数据处理脚本,需要以仓库当前内容为准。
数据
论文列出数据来源与规模。附录列出了 Egodex、Agibot、RDT、RoboMind、RoboTwin、Task-Agnostic Data 和 In-house Data 的规模、embodiment 与数据金字塔层级。但 In-house Data 的采集细节、过滤规则和原始发布状态会影响完全复现。
训练配置
关键训练超参给出。Batch size、learning rate、optimizer、weight decay、GPU hours、模型规模、latent VAE 权重、采样率和 flow matching steps 均在附录中列出。
主要复现步骤
- 准备 VGM 和 VLM 预训练专家:Wan 2.2 5B、Qwen3-VL-2B。
- 用 DPFlow 为视频数据生成 optical flow,并训练 latent action VAE:flow reconstruction + action alignment + KL。
- Stage 1 只训练/适配 VGM,让其在机器人操作数据上生成未来任务视频。
- Stage 2 训练三专家 Motus,VLM frozen,输入 videos、language 和 latent actions。
- Stage 3 在目标机器人真实 action trajectories 上 SFT,替换 latent actions 为目标机器人动作。
- 评测时根据目标模式设置 observation/action timestep:clean 模态设为 0,需要生成的模态从 $T_\tau$ 噪声开始。
潜在复现障碍
算力和数据是主要瓶颈。附录训练配置显示 Stage 1 约 8000 GPU hours,Stage 2 约 10000 GPU hours;模型总规模约 8B。完整复现还需要获取大规模多源数据和 in-house target-robot trajectories,并复现真实机器人 PSR 评测协议。