1. Quick overview of the paper
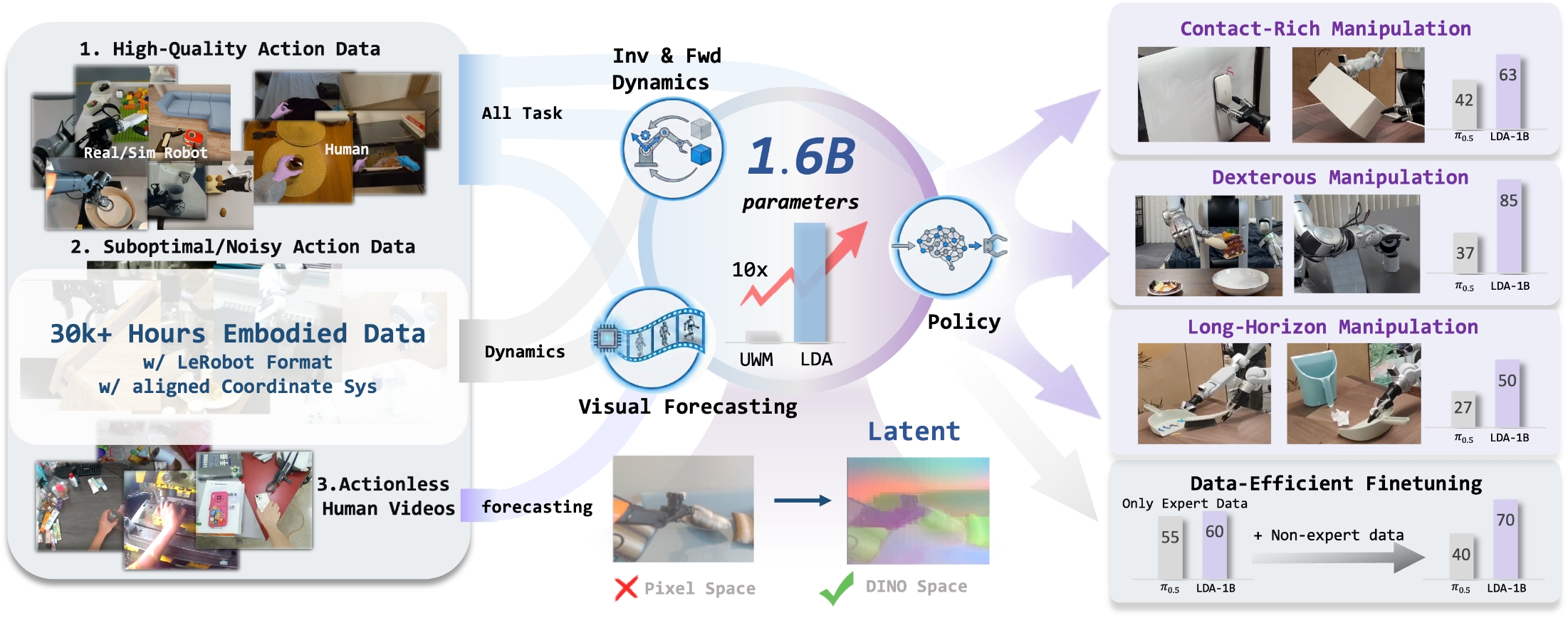
The core proposition of this paper is that the basic robot model should not only treat large-scale data as behavioral clone samples, but should allocate embodied data of different qualities, different modalities, and even no action annotations to policy, forward dynamics, inverse dynamics, and visual forecasting according to the supervision signals they can provide. LDA-1B uses DINO latent to predict future visual states, and uses MM-DiT to uniformly model action and visual latent, allowing 30k+ hours of mixed data to truly participate in training.
| What should the paper solve? | The existing robot foundation model mainly extends behavior cloning, and usually only consumes high-quality robot teaching; a large number of low-quality trajectories, human videos, and no-action videos are either filtered out or only used crudely. The author wants to solve the problem of "how heterogeneous embodied data can be utilized at scale". |
|---|---|
| The author's approach | LDA-1B is proposed: use Universal Embodied Data Ingestion to assign different training targets to different data; use DINOv3 latent as the future visual prediction target; use multi-modal diffusion transformer to share attention between action tokens and visual tokens but retain modal experts; build the EI-30K data set. |
| most important results | The average success rate of RoboCasa-GR1 is 55.4%, which is higher than the 47.6% of GR00T-N1.6 and 51.3% of GR00T-EI10k; there are obvious gains in contact-rich, dexterous, and long-horizon scenarios in real robots; after adding low-quality trajectories, LDA increases by 10%, while $\pi_{0.5}$ decreases. |
| Things to note when reading | "1B" is not the only key, the key is DINO latent + data role division + four-task joint training. Many improvements in experiments come from the coupling of data, latent representation, and architecture, and cannot be attributed solely to the number of parameters. |
2. Problem background
2.1 Why "just doing BC extension" is not enough
Most of the existing basic robot models compress the training goals into one form: given the current observation and language, predict the next action. This paradigm is straightforward when high-quality robot teaching is sufficient, but has three bottlenecks.
- Data waste: Low-quality trajectories, exploration trajectories, failed retries, human videos, and no-action videos are not suitable for direct BC, but contain information such as environmental dynamics, object affordance, and contact consequences.
- Target mismatch: BC penalizes "acting like an expert" but does not explicitly require the model to understand how the action changes the state of the world. Exposure to rich, long-term tasks is especially likely to accumulate errors.
- Representation overload: If you use pixel or VAE latent to predict future images, the model will be hampered by appearance details such as texture, lighting, and background, making it difficult to use capacity for controllable dynamics.
2.2 Basic assumptions of LDA
The implicit assumptions of LDA can be summarized as: Heterogeneous data is not BC data of uniform quality, but a set of dynamics data with different supervisory values.High-quality robot/human teaching can train policy and dynamics; low-quality action trajectories, although not suitable for imitation, can still train forward/inverse dynamics; motion-free videos can at least train visual time evolution and object state changes.
4. Detailed explanation of method
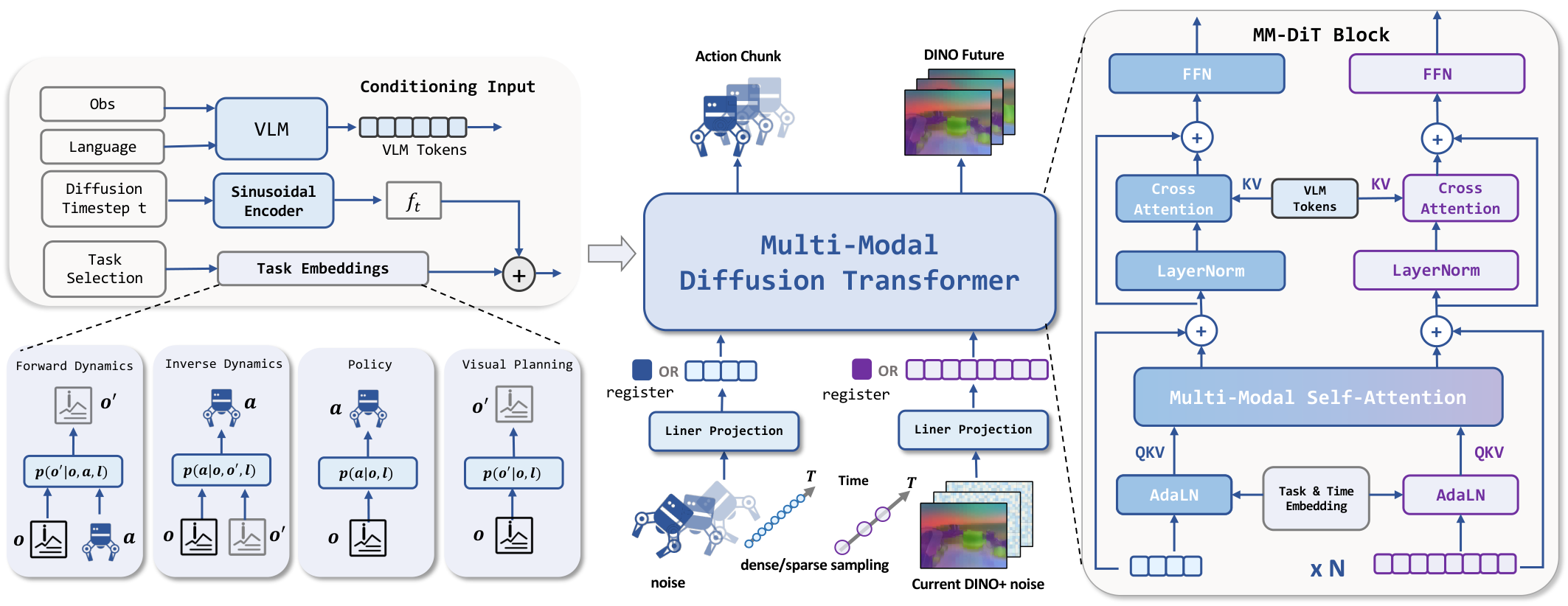
4.1 From Unified World Model to LDA
The paper first writes robot learning into four types of conditional distributions. Suppose the current observation is $o_t$, the future action block is $a_{t+1: t+k}$, and the future observation is $o_{t+1: t+k}$:
- Policy: $p(a_{t+1: t+k}\mid o_t)$, predict actions for the current state.
- Forward Dynamics: $p(o_{t+1: t+k}\mid o_t, a_{t+1: t+k})$, predict the future state of the action.
- Inverse Dynamics: $p(a_{t+1: t+k}\mid o_{t: t+k})$, invert actions for status changes.
- Visual Planning / Forecasting: $p(o_{t+1: t+k}\mid o_t)$ does not rely on action labels and only predicts visual evolution.
UWM treats both actions and future observations as diffusion variables, and the noise predictor can be written as:
$$ (\epsilon_a^\theta, \epsilon_o^\theta)=s_\theta(o, a_{t_a}, o'_{t_o}, t_a, t_{o'}) $$
On this basis, LDA adds the language command $\ell$, and changes future observations from pixel/VAE latent to DINO latent.
4.2 Universal Embodied Data Ingestion
This section is the core training design of the paper. LDA does not send all data into the same BC loss, but uses task specification and task embedding to decide which supervision terms to activate.
| data type | What supervision can be provided? | Can't force anything | How to use it in LDA |
|---|---|---|---|
| High quality robot/human teaching | Action decisions, state transitions caused by actions, visual future | - | policy, forward dynamics, inverse dynamics, and visual forecasting are all available |
| Low quality/non-expert tracks | Real contact, failure recovery, environment transfer, object response | Not suitable for direct imitation as expert action | Mainly train dynamics and visual forecasting; conditionally participate in policy post-training |
| No action first-person video | Object state changes, visual temporal structure, affordance priors | Unable to supervise action prediction or inverse dynamics | for visual forecasting, supplementing 10k hours of visual experience |
The model uses four learnable task embeddings to represent the current task: policy, forward dynamics, inverse dynamics, and visual forecasting. The missing mode uses two register tokens as placeholders, one corresponding to the action and one corresponding to the visual state. This is important: it allows the same transformer to still see a structurally consistent sequence of tokens across different conditional missing modes.
4.3 Flow Matching Goals
The paper uses flow-matching to train actions and observe latent velocity fields. The action goals and visual goals are:
$$ \mathcal{L}_{action}= \mathbb{E}\left\|v_a^\theta-(\epsilon_a-a_{t+1: t+k})\right\|_2^2 $$
$$ \mathcal{L}_{obs}= \mathbb{E}\left\|v_o^\theta-(\epsilon_o-o_{t+1: t+k})\right\|_2^2 $$
The total loss is $\mathcal{L}=\mathcal{L}_{action}+\mathcal{L}_{obs}$, but during actual training, action loss or observation loss will be selectively turned on according to the task specification. For example, action-free videos have no action supervision and only activate visual prediction; low-quality trajectories can be used more for dynamics instead of forcing actions to be taught by experts.
4.4 Why predict DINO latent instead of pixels
One of the most critical engineering judgments of this paper is that the future visual state does not target RGB or VAE latent, but the latent feature of DINOv3-ViT-s. The advantage of DINO latent is to retain object semantics, spatial structure and affordances, while weakening control-irrelevant factors such as texture, lighting, and background.

4.5 Action space and time frequency
LDA uses hand-centric action space to unify robot and human data. Movements include delta wrist pose and finger configuration. Parallel grippers use a single degree of freedom gripper width; dexterous hands use keypoints or joint configurations in the wrist coordinate system. Visual observations are sampled at 3 Hz, actions are sampled at 10 Hz, and the action chunk length is 16.

4.6 MM-DiT architecture
MM-DiT receives action tokens, visual latent tokens, current observations, verbal instructions, diffusion timestep and task embedding. The paper emphasizes two points:
- Share attention: Actions and visual tokens interact in self-attention, allowing the model to learn "which visual areas change due to actions."
- Modal Expert: Action and visual modes retain their own QKV projection, FFN and output head to avoid compressing tokens with completely different numerical structures into the same set of linear transformations.
VLM uses Qwen3-VL as the language and visual condition encoder; the appendix explains that the pre-training stage freezes VLM and DINO encoder, mainly training MM-DiT and action encoder/decoder. During the fine-tuning phase, VLM will be unfrozen for end-to-end adaptation. MM-DiT also conditions a two-step history window including past DINO observations and actions to capture short-term dynamics.
| Configuration items | numerical value |
|---|---|
| VLM | Qwen3-VL |
| Observation Encoder | DINOv3-ViT-s |
| Hidden Size / Layers / Heads | 1536 / 16 / 32 |
| Image / Latent Image Shape | $(224, 224, 3)$ / $(14, 14, 384)$ |
| Action Chunk | 16 |
| Batch Size | pretraining: $32\times48$; finetuning: $12\times8$ |
| Optimizer | AdamW, lr $10^{-4}$, weight decay $10^{-5}$, betas [0.9, 0.95], eps $10^{-8}$ |
| Schedule | cosine, minimum lr $5\times10^{-7}$ |
| Pretraining Cost | 48 NVIDIA H800 GPUs, 400k iterations, 4, 608 GPU hours |
5. Data and preprocessing
EI-30K is an important fulcrum for the establishment of the thesis method. It is not a single robot data set, but unifies real robots, simulated robots, human first-perspective data with moving humans, and first-perspective videos of non-moving human beings.
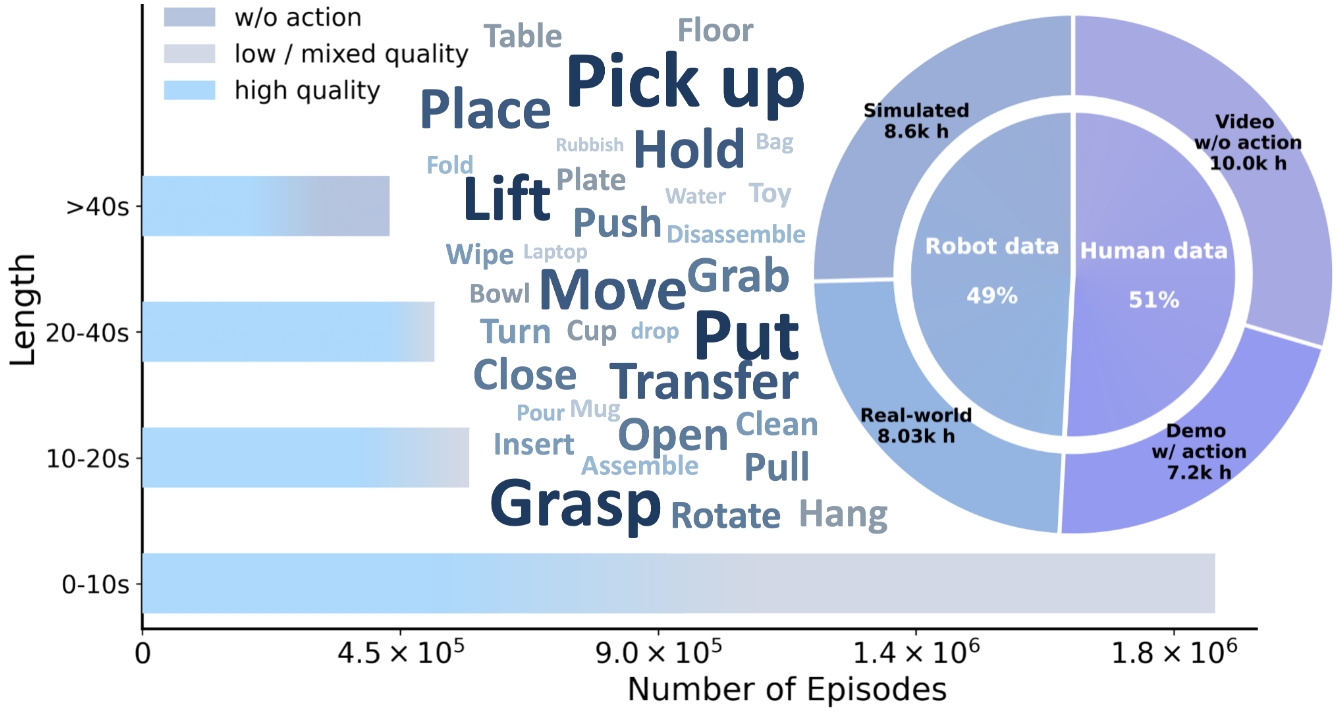
| Category | hours | primary data sources | role |
|---|---|---|---|
| Real-world Robot | 8.03k h | Open X-Embodiment 3000h, Agibot World 3276h, RoboMIND 305h, Humanoid Everyday 30h, RoboCOIN 500h, Galaxea 500h, LET 1000h | Realistic robot motion, contact, failure and recovery modes |
| Simulated Robot | 8.6k h | InternData-A1 7433h, Behavior-1k 1200h | High-density, low-noise action supervision and long-term task structure |
| Ego Human with Action | 7.2k h | Ego4D, EPIC-KITCHENS, Ego-Exo4D, SSV2, EgoDex, HOT3D, HoloAssist, OAKINK2, TACO, HOI4D, ARCTIC | Human intentions, hand movements, fine-grained dexterity priors |
| Ego Human Actionless | 10k h | Egocentric-10k, RH20T-human, EgoMe, Taste-Rob | visual affordance, temporal structure, motionless visual forecasting |
5.1 Standardized pipeline
The appendix gives a more detailed data processing process, which can be divided into three layers.
- Format standardization: All raw data is converted to LeRobot 2.1 style format, including end-effector poses, hand articulation, camera intrinsic/extrinsic, task metadata, episode boundary and timestamps. All sequences were uniformly resampled to 10 Hz.
- Coordinate alignment and cleaning: Define canonical EEF frames for each dataset, unifying wrist or gripper centers with rigid offsets; perform camera motion decoupling on moving camera sequences; convert human hands to 21-point MANO representations; discard occluded, truncated, or kinematically invalid frames.
- Post-training processing: VLM unifies language annotation and completes missing descriptions; removes fragments without valid hand-object interaction; retains but labels low-quality trajectories; organizes metadata by human/robot, task, and quality.
6. Key points for experimental reproducibility
6.1 RoboCasa-GR1 simulation experiment
RoboCasa-GR1 consists of 24 tabletop rearrangement and articulated-object manipulation tasks using a GR-1 humanoid robot with Fourier dexterous hands. The input is the egocentric RGB of the head-mounted camera. All models were fine-tuned on 1, 000 trajectories per task according to the GR00T protocol, evaluated 51 times per task, and the average success rate is reported.
| model | state representation | MM-DiT | VLM | success rate |
|---|---|---|---|---|
| GR00T-N1.6 | - | - | - | 47.6 |
| StarVLA | - | - | Qwen3-VL | 47.8 |
| GR00T-EI10k | - | - | Qwen3-VL | 51.3 |
| UWM-0.1B | VAE | No | No | 14.2 |
| UWM-1B | VAE | No | Qwen3-VL | 19.3 |
| UWM + MM-DiT | VAE | Yes | Qwen3-VL | 20.0 |
| LDA (DiT) | DINO | No | Qwen3-VL | 48.9 |
| LDA-0.5B | DINO | Yes | Qwen3-VL | 50.7 |
| LDA-1B | DINO | Yes | Qwen3-VL | 55.4 |
The most noteworthy thing about this table is not "LDA is 7.8 points higher than GR00T", but the ablation logic: when UWM is expanded from 0.1B to 1B, and MM-DiT is replaced, it still stops at around 20; once it is replaced with DINO latent, the success rate jumps to 55.4. This strongly supports the author's argument about structured latent state.

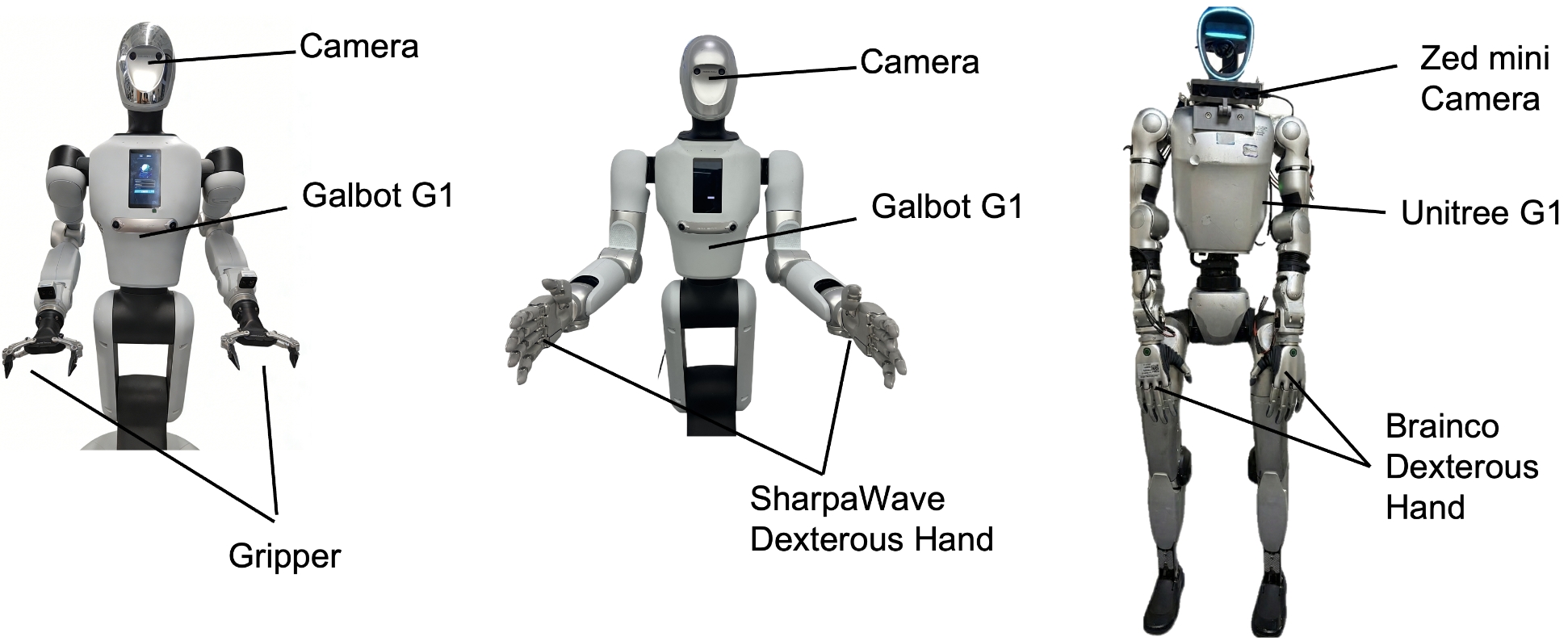
6.2 Real robot experiment
Real experiments cover Galbot G1 and Unitree G1. The Galbot G1 uses dual 7-DoF arms that can be fitted with a two-finger gripper or a 22-DoF SharpaWave dexterity hand; the Unitree G1 uses a 10-DoF BrainCo hand. All configurations use only egocentric RGB head-mounted cameras.
| Task category | Representative tasks | Why is it difficult |
|---|---|---|
| Pick and Place | Pick Vegetable, Handover | Few-shot adaptation, random object position for new robot embodiment |
| Contact-rich | Flip Box, Beat Block | Contact force, collision, state change after object flipping |
| Fine Manipulation | Water Flower, Wipe Board | Continuous closed-loop control, attitude accuracy, tool contact |
| Long-horizon | Sweep Table, Clean/Throw Rubbish | Multi-stage process, early errors will accumulate to subsequent subtasks |
| Dexterous | Pull Nail, Flip Bread | High-dimensional finger control, stable contact, tool use and force direction |
Each task collects 100 teleoperation traces, and it is not mandatory for all expert demonstrations; about 50-80% are expert behaviors, and the rest include pauses, retries, and inefficient actions. Baseline $\pi_{0.5}$ and GR00T only use the filtered expert subset for fine-tuning; LDA uses all trajectories and absorbs the dynamics information of low-quality data through Universal Embodied Data Ingestion.
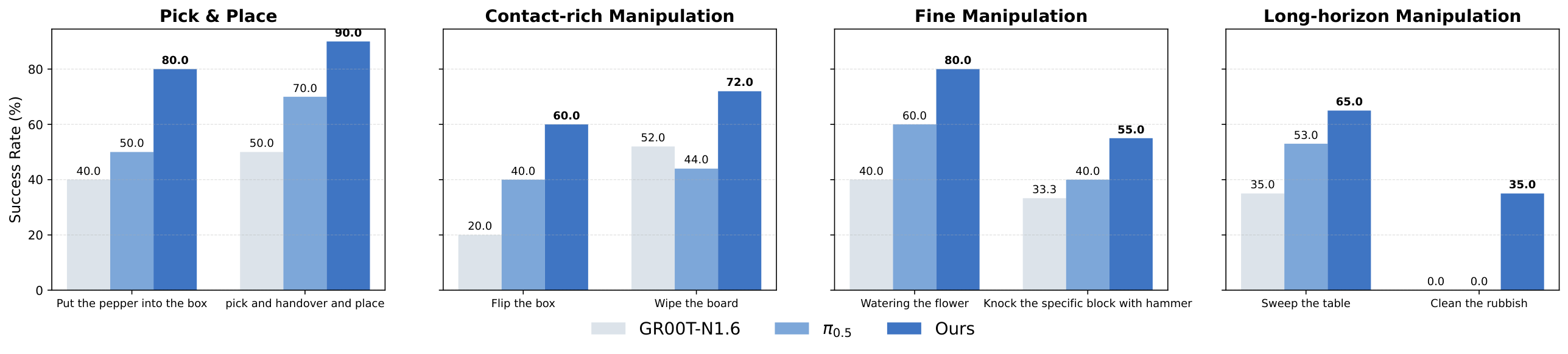
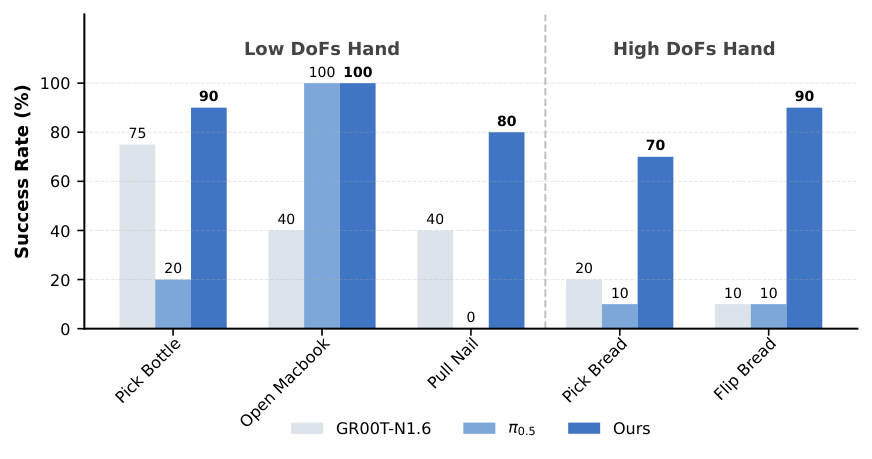
6.3 Generalization and fine-tuning of mixture quality
| model | Novel Object | Unseen Background | OOD Position |
|---|---|---|---|
| $\pi_{0.5}$ | 26.7 | 20.0 | 6.7 |
| GR00T | 40.0 | 40.0 | 20.0 |
| LDA-1B | 60.0 | 60.0 | 40.0 |
| Task | model | High only | High + Low | change |
|---|---|---|---|---|
| Place pen into box | $\pi_{0.5}$ | 60 | 40 | -20 |
| Place pen into box | LDA | 70 | 80 | +10 |
| Bimanually remove lid | $\pi_{0.5}$ | 50 | 40 | -10 |
| Bimanually remove lid | LDA | 50 | 60 | +10 |
This experiment directly verified the central claim of the paper: low-quality data is harmful to ordinary BC baselines, but can be beneficial to LDA, because LDA does not treat these trajectories as equivalent expert actions, but learns dynamics and visual state transfer from them.
6.4 Scaling analysis
The author uses action prediction L1 error as a reproducible proxy on held-out Agibot World to compare model capacity, data size and training goals. Training configurations include Policy Only, Policy + Visual Forecasting, Policy with Forward/Inverse Dynamics, and full co-training.
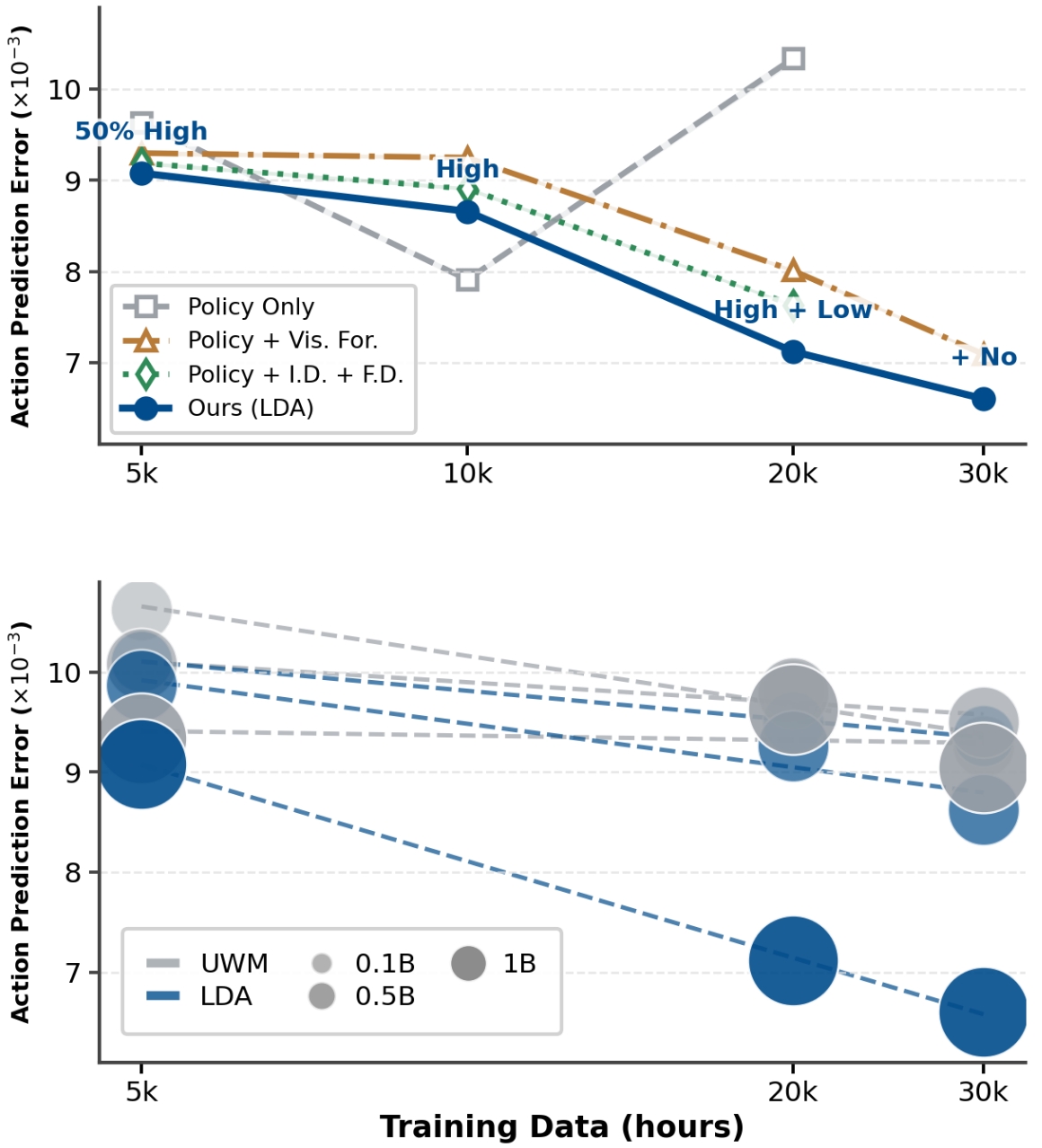
7. Result analysis and discussion
7.1 The most valuable part of this paper
The most valuable thing is not a single benchmark number, but a relatively clear data utilization paradigm: splitting heterogeneous embodied data into supervised conditional distributions instead of stuffing them into BC uniformly. This paradigm is practical for robot learning because real data is never a clean expert-only demo. Human videos, failed trajectories, semi-successful trajectories, low-quality teleops, and simulation data are each "imperfect", but they can serve dynamics, visual forecasting, or policy respectively.
The second value is to transfer future visual predictions from pixel space to DINO latent. The reason why many robot world models are unstable is that the prediction target is too similar to the video generation task; LDA represents the future state as a latent that is closer to the control-related semantics, thereby making dynamics learning more targeted.
7.2 Why the results hold up
The evidence chain of the paper is relatively complete for three reasons.
- Ablation can isolate critical components: After UWM is expanded to 1B or MM-DiT is added, it is still only 19.3/20.0, while DINO latent LDA reaches 55.4, indicating that representation space is one of the main factors; removing MM-DiT drops from 55.4 to 48.9, indicating that the architecture also contributes.
- Data role claim has direct experiments: In mixed quality fine-tuning, adding low-quality data causes $\pi_{0.5}$ to decrease and LDA to increase, which corresponds to the core argument of Universal Data Ingestion.
- Real robot tasks cover multiple failure modes: From simple pick-and-place to long-horizon rubbish cleaning, pull nail, and flip bread, the difficulty of the task is not just visual recognition, but contact, tool, force direction, and timing error recovery.
7.3 Dynamics What we learned
The paper uses two types of visualizations to support that "the model is really learning action-conditioned state transitions." The first category is a PCA visualization of DINO latent forward dynamics, showing that predicted future features maintain object permanence, contact continuity, and motion consistency. The second type is action-conditioned attention: for the same observation, compare the attention under active action and No-Op conditions, and take the difference value $\Delta A = |A_1-A_2|$, thereby eliminating static visual saliency and highlighting the causally relevant areas caused by the action.
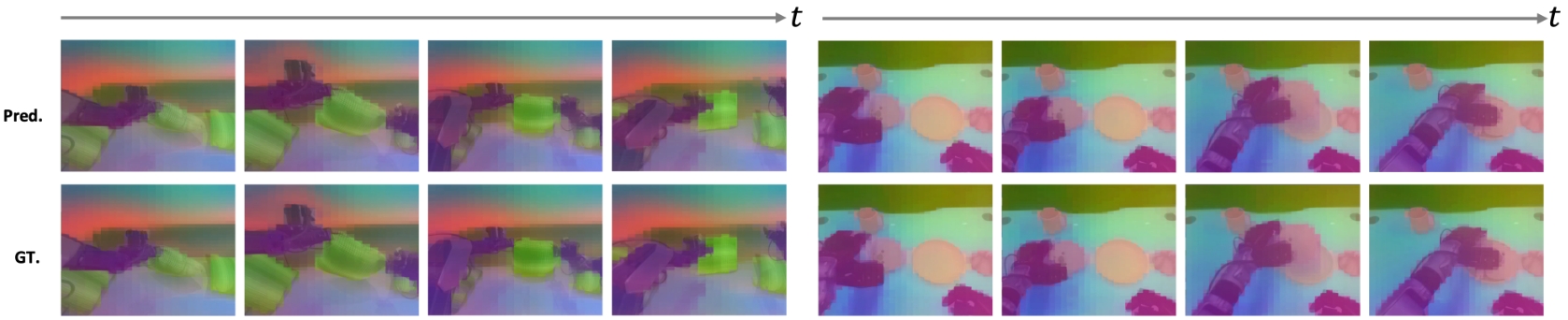

7.4 Limitations and risks
Fixed upper limit for DINO representation: DINO is a general visual representation and is not necessarily optimal for robot contact, mechanics, and maneuverability. The authors also acknowledge the need for joint learning of visual representation and latent dynamics in the future.
Viewing angle offset: The data and experiments are mainly egocentric cameras, and migration to multimodal settings such as external multi-view, tactile, force-sensing or event cameras is still not fully validated.
The threshold for data engineering is high: The coordinate alignment, language standardization, quality annotation and cleaning of EI-30K are huge projects. If these processes cannot be reproduced or are not open source enough, the "universality" of the method will be compromised.
action prediction L1 is just a proxy: The scaling curve is very convincing, but ultimately more real deployment tasks are needed to verify the correlation between proxy and actual success rate.
8. List of follow-up questions for team meetings
Q1: What is the essential difference between LDA and ordinary diffusion policy?
Ordinary diffusion policy mainly denoises actions; LDA simultaneously denoises actions and future DINO latent, and switches policy, forward dynamics, inverse dynamics, and visual forecasting through task embedding. Therefore, it not only learns "how to do it", but also learns "how the world changes after doing it."
Q2: Why is low-quality data useful for LDA but harmful to $\pi_{0.5}$?
If BC is performed directly, low-quality actions will pollute the policy target; LDA can use low-quality trajectories more for dynamics or visual prediction, allowing the model to learn non-expert but real environmental information such as contact, state transfer, and failure recovery. In the fine-tuning experiment, LDA +10% and $\pi_{0.5}$ decreased, which is evidence of this mechanism.
Q3: Will DINO latent lose the fine-grained geometry needed for robot control?
This is a legitimate concern. The authors' experimental evidence shows that DINO latent is more suitable for the current task than VAE/pixel-space UWM, especially the large gap from 20.0 to 55.4 for RoboCasa. However, whether DINO is sufficient to express fine contact, force sense and invisible state is still limited. The conclusion of the paper also proposes joint representation learning in the future.
Q4: Why are 1B parameters better than 3B GR00T?
The explanation of the paper is not "more parameters", but "more correct training objectives and state space". LDA uses 1B parameters to simultaneously learn action and latent dynamics; although GR00T-N1.6 is a strong baseline, it is mainly policy-centric. LDA-1B in RoboCasa is 55.4, which is higher than 3B GR00T-N1.6's 47.6.
Q5: If I want to reproduce it, what's the hardest part?
Model structure is not the only difficulty. Even more difficult is EI-30K style data unification: action frame alignment, camera frame decoupling, MANO/robot gripper representation unification, language re-annotation, quality labels, and correct activation of losses for different tasks.
9. reproducibility information
9.1 Resource links
- arXiv: https: //arxiv.org/abs/2602.12215
- Project page: https: //pku-epic.github.io/LDA
- Code: https: //github.com/jiangranlv/latent-dynamics-action
- Data: project page marked as
Data (Coming Soon).
9.2 Training setup shorthand
VLM: Qwen3-VL
Observation encoder: DINOv3-ViT-s
MM-DiT: hidden 1536, layers 16, heads 32
Image: 224x224x3
DINO latent: 14x14x384
Action chunk: 16
Pretraining batch: 32 * 48
Finetuning batch: 12 * 8
Optimizer: AdamW, lr 1e-4, wd 1e-5, betas [0.9, 0.95]
Schedule: cosine, min lr 5e-7
Compute: 48 H800 GPUs, 400k iterations, 4,608 GPU hours9.3 Coverage check of this report
This report has covered Abstract, Introduction, Related Work, Latent Dynamics Action Model, EI-30K, Experiments, Conclusion, as well as model hyperparameters, RoboCasa task-by-task results, real robot task protocol, EI-30K data processing pipeline, action-conditioned attention and latent dynamics visualization in the appendix. Appendix content has been thematically integrated into Methods, Data, Experiments, and Discussion chapters.
Generation date: 2026-05-08. The source code, PDF and decompression Contents have been retained for subsequent reading or verification.