1. 论文速览
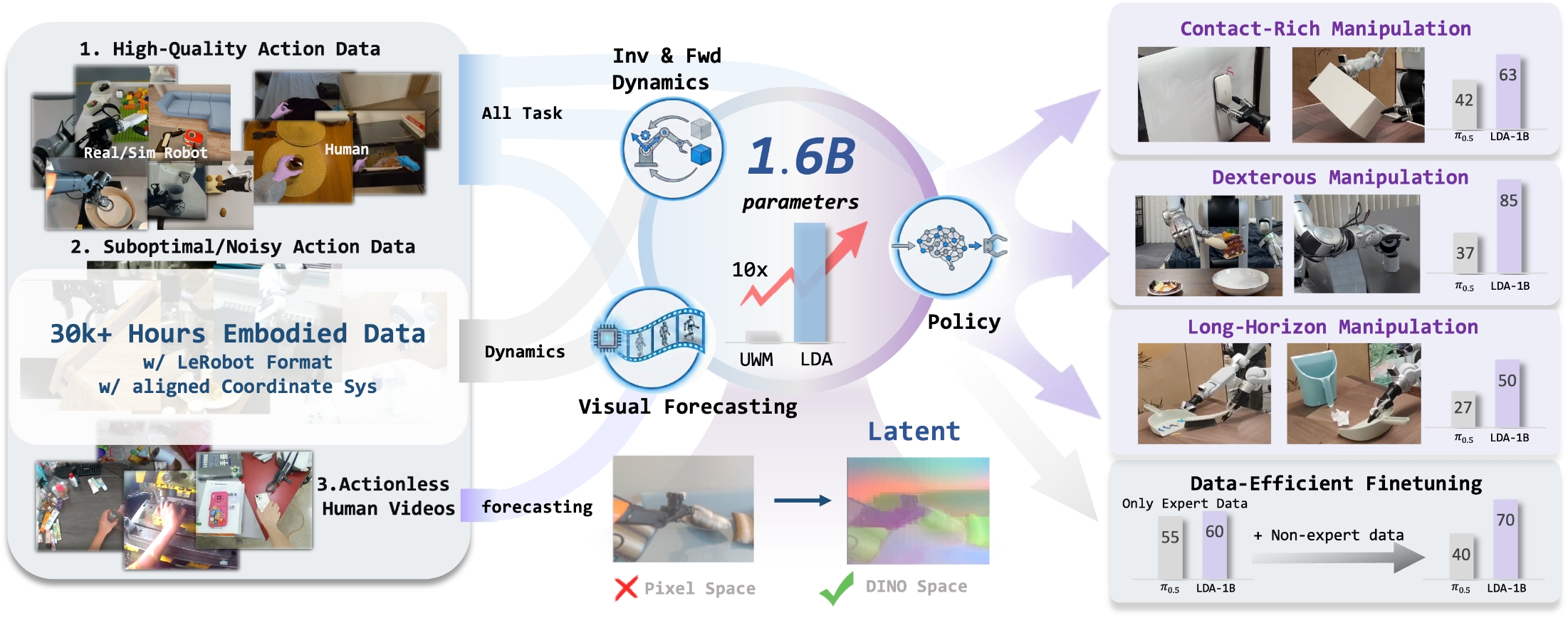
这篇论文的核心主张是:机器人基础模型不应该只把大规模数据当作行为克隆样本,而应该把不同质量、不同模态、甚至没有动作标注的具身数据,按其可提供的监督信号分配给 policy、forward dynamics、inverse dynamics 和 visual forecasting。LDA-1B 用 DINO latent 预测未来视觉状态,并用 MM-DiT 统一建模动作和视觉 latent,从而让 30k+ 小时混合数据真正参与训练。
| 论文要解决什么 | 现有 robot foundation model 主要扩展 behavior cloning,通常只吃高质量机器人示教;大量低质量轨迹、人类视频、无动作视频要么被过滤掉,要么只被粗糙使用。作者想解决“异构具身数据如何被规模化利用”的问题。 |
|---|---|
| 作者的方法抓手 | 提出 LDA-1B:用 Universal Embodied Data Ingestion 给不同数据分配不同训练目标;用 DINOv3 latent 作为未来视觉预测目标;用 multi-modal diffusion transformer 在动作 token 与视觉 token 间共享注意力但保留模态专家;构建 EI-30K 数据集。 |
| 最重要的结果 | RoboCasa-GR1 平均成功率 55.4%,高于 GR00T-N1.6 的 47.6% 和 GR00T-EI10k 的 51.3%;真实机器人中 contact-rich、dexterous、long-horizon 场景有明显增益;低质量轨迹加入后 LDA 提升 10%,而 $\pi_{0.5}$ 下降。 |
| 阅读时要注意的点 | “1B”不是唯一关键,关键是 DINO latent + 数据角色分工 + 四任务联合训练。实验中许多提升来自数据、latent 表征、架构三者耦合,不能只归因于参数量。 |
2. 问题背景
2.1 为什么“只做 BC 扩展”不够
现有机器人基础模型大多把训练目标压成一个形式:给定当前观察和语言,预测下一段动作。这个范式在高质量机器人示教充足时很直接,但有三个瓶颈。
- 数据浪费:低质量轨迹、探索轨迹、失败重试、人类视频和无动作视频不适合直接 BC,却包含环境 dynamics、物体 affordance、接触后果等信息。
- 目标错配:BC 惩罚“动作不像专家”,但不显式要求模型理解动作会怎样改变世界状态。接触丰富、长时序任务尤其容易累积错误。
- 表征过载:如果用 pixel 或 VAE latent 预测未来图像,模型会被纹理、光照、背景等 appearance 细节拖住,难以把容量用于可控动力学。
2.2 LDA 的基本假设
LDA 的隐含假设可以概括为:异构数据并不是统一质量的 BC 数据,而是一组带有不同监督价值的 dynamics 数据。高质量机器人/人类示教可以训练 policy 和 dynamics;低质量动作轨迹虽然不适合 imitation,却仍可训练 forward/inverse dynamics;无动作视频至少可以训练视觉时间演化和物体状态变化。
4. 方法详解
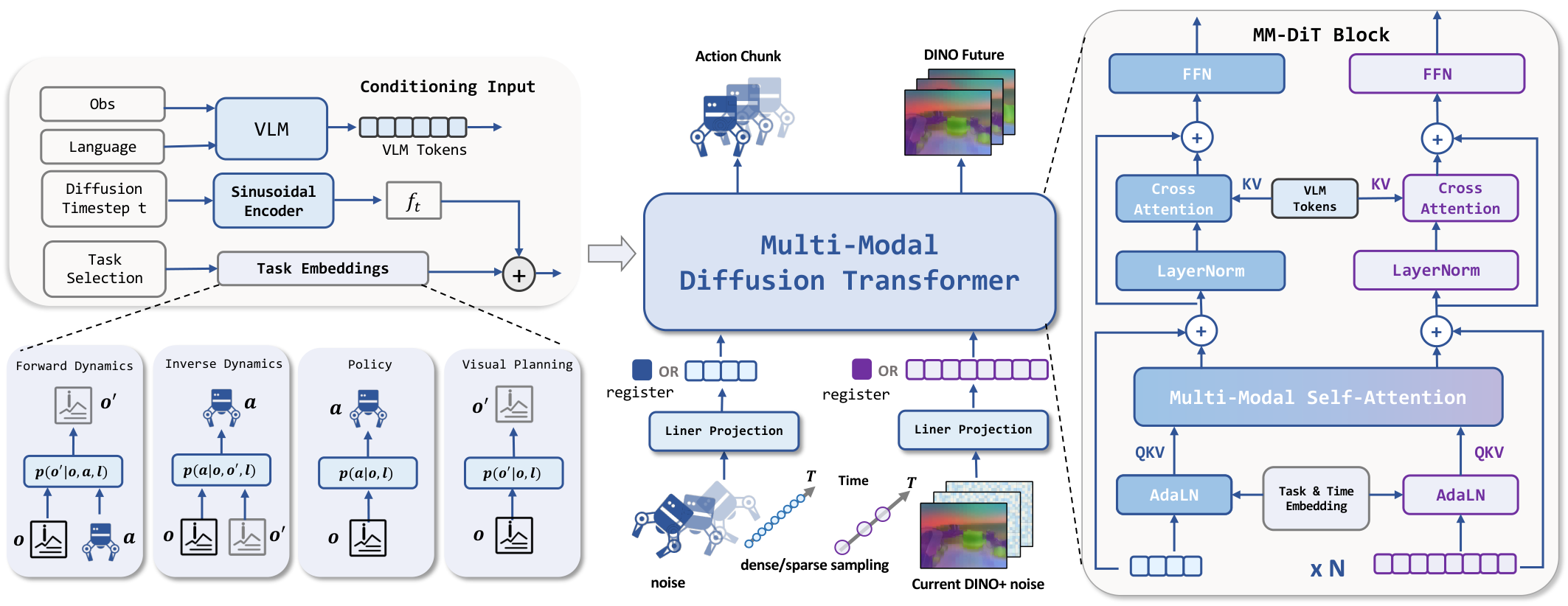
4.1 从 Unified World Model 到 LDA
论文先把机器人学习写成四类条件分布。设当前观测为 $o_t$,未来动作块为 $a_{t+1:t+k}$,未来观测为 $o_{t+1:t+k}$:
- Policy: $p(a_{t+1:t+k}\mid o_t)$,给当前状态预测动作。
- Forward Dynamics: $p(o_{t+1:t+k}\mid o_t, a_{t+1:t+k})$,给动作预测未来状态。
- Inverse Dynamics: $p(a_{t+1:t+k}\mid o_{t:t+k})$,给状态变化反推出动作。
- Visual Planning / Forecasting: $p(o_{t+1:t+k}\mid o_t)$,不依赖动作标签,只预测视觉演化。
UWM 把动作和未来观测都当作扩散变量,噪声预测器可写为:
$$ (\epsilon_a^\theta,\epsilon_o^\theta)=s_\theta(o,a_{t_a},o'_{t_o},t_a,t_{o'}) $$
LDA 在此基础上加入语言指令 $\ell$,并把未来观测从 pixel/VAE latent 换成 DINO latent。
4.2 Universal Embodied Data Ingestion
这一节是论文最核心的训练设计。LDA 不把所有数据都送进同一个 BC loss,而是用任务 specification 和 task embedding 决定激活哪些监督项。
| 数据类型 | 能提供什么监督 | 不能硬做什么 | LDA 中的使用方式 |
|---|---|---|---|
| 高质量机器人/人类示教 | 动作决策、动作导致的状态转移、视觉未来 | - | policy、forward dynamics、inverse dynamics、visual forecasting 都可用 |
| 低质量/非专家轨迹 | 真实接触、失败恢复、环境转移、物体响应 | 不适合直接当 expert action 模仿 | 主要训练 dynamics 与 visual forecasting;有条件地参与 policy 后训练 |
| 无动作第一视角视频 | 物体状态变化、视觉时间结构、可供性先验 | 无法监督动作预测或 inverse dynamics | 用于 visual forecasting,补充 10k 小时视觉经验 |
模型使用四个可学习 task embedding 表示当前任务:policy、forward dynamics、inverse dynamics、visual forecasting。缺失模态用两个 register token 作为占位,一个对应动作,一个对应视觉状态。这一点很重要:它让同一个 transformer 在不同条件缺失模式下仍看到结构一致的 token 序列。
4.3 Flow Matching 目标
论文用 flow-matching 形式训练动作与观测 latent 的速度场。动作目标与视觉目标分别为:
$$ \mathcal{L}_{action}= \mathbb{E}\left\|v_a^\theta-(\epsilon_a-a_{t+1:t+k})\right\|_2^2 $$
$$ \mathcal{L}_{obs}= \mathbb{E}\left\|v_o^\theta-(\epsilon_o-o_{t+1:t+k})\right\|_2^2 $$
总损失是 $\mathcal{L}=\mathcal{L}_{action}+\mathcal{L}_{obs}$,但实际训练时会根据任务 specification 选择性打开 action loss 或 observation loss。比如无动作视频没有 action supervision,只激活视觉预测;低质量轨迹可更多用于 dynamics,而不是强行把动作当专家示教。
4.4 为什么预测 DINO latent 而不是像素
这篇论文最关键的工程判断之一是:未来视觉状态不以 RGB 或 VAE latent 为目标,而以 DINOv3-ViT-s 的 latent feature 为目标。DINO latent 的优势是保留对象语义、空间结构和可供性,同时弱化纹理、光照、背景等控制无关因素。

4.5 动作空间与时间频率
LDA 使用 hand-centric action space 来统一机器人和人类数据。动作包括 delta wrist pose 和手指配置。平行夹爪用单自由度 gripper width;灵巧手用 wrist 坐标系下的 keypoints 或关节配置。视觉观测按 3 Hz 采样,动作按 10 Hz 采样,action chunk 长度为 16。

4.6 MM-DiT 架构
MM-DiT 接收动作 token、视觉 latent token、当前观测、语言指令、diffusion timestep 和 task embedding。论文强调两点:
- 共享注意力:动作和视觉 token 在 self-attention 中交互,使模型能学习“动作导致哪些视觉区域变化”。
- 模态专家:动作与视觉模态保留各自的 QKV projection、FFN 和 output head,避免把数值结构完全不同的 token 压成同一套线性变换。
VLM 使用 Qwen3-VL 作为语言和视觉条件 encoder;附录说明预训练阶段冻结 VLM 与 DINO encoder,主要训练 MM-DiT 和动作 encoder/decoder。微调阶段 VLM 会被解冻以做端到端适配。MM-DiT 还条件化一个两步历史窗口,包括过去 DINO 观测和动作,用于捕捉短时 dynamics。
| 配置项 | 数值 |
|---|---|
| VLM | Qwen3-VL |
| Observation Encoder | DINOv3-ViT-s |
| Hidden Size / Layers / Heads | 1536 / 16 / 32 |
| Image / Latent Image Shape | $(224,224,3)$ / $(14,14,384)$ |
| Action Chunk | 16 |
| Batch Size | pretraining: $32\times48$;finetuning: $12\times8$ |
| Optimizer | AdamW, lr $10^{-4}$, weight decay $10^{-5}$, betas [0.9, 0.95], eps $10^{-8}$ |
| Schedule | cosine, minimum lr $5\times10^{-7}$ |
| Pretraining Cost | 48 NVIDIA H800 GPUs, 400k iterations, 4,608 GPU hours |
5. 数据与预处理
EI-30K 是论文方法成立的重要支点。它不是单一机器人数据集,而是把真实机器人、仿真机器人、带动作人类第一视角数据、无动作人类第一视角视频统一起来。
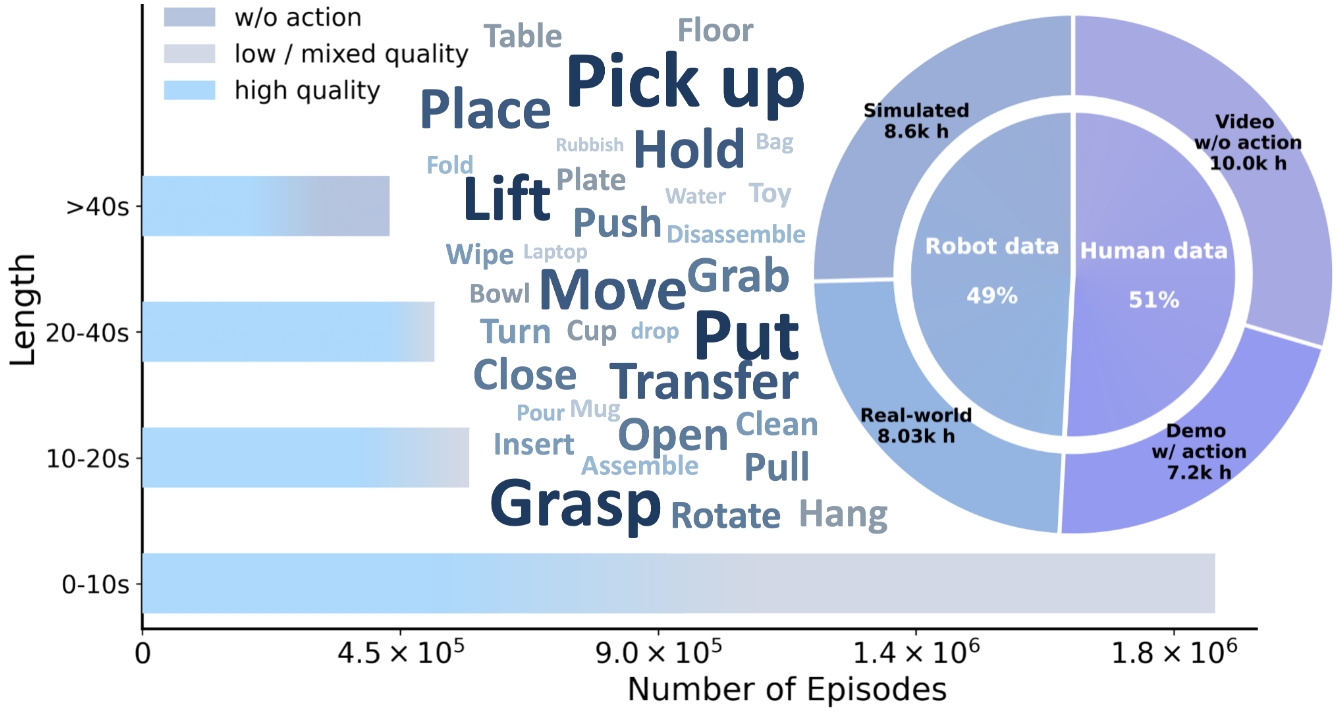
| 类别 | 小时数 | 主要数据源 | 角色 |
|---|---|---|---|
| Real-world Robot | 8.03k h | Open X-Embodiment 3000h, Agibot World 3276h, RoboMIND 305h, Humanoid Everyday 30h, RoboCOIN 500h, Galaxea 500h, LET 1000h | 真实机器人动作、接触、失败与恢复模式 |
| Simulated Robot | 8.6k h | InternData-A1 7433h, Behavior-1k 1200h | 高密度、噪声低的动作监督和长时序任务结构 |
| Ego Human with Action | 7.2k h | Ego4D, EPIC-KITCHENS, Ego-Exo4D, SSV2, EgoDex, HOT3D, HoloAssist, OAKINK2, TACO, HOI4D, ARCTIC | 人类意图、手部动作、细粒度 dexterity 先验 |
| Ego Human Actionless | 10k h | Egocentric-10k, RH20T-human, EgoMe, Taste-Rob | 视觉 affordance、时间结构、无动作 visual forecasting |
5.1 标准化 pipeline
附录给出了更细的数据处理流程,可拆成三层。
- 格式标准化:所有原始数据转换为 LeRobot 2.1 风格格式,包含 end-effector poses、hand articulation、camera intrinsic/extrinsic、task metadata、episode boundary 和 timestamps。所有序列统一重采样到 10 Hz。
- 坐标对齐与清洗:为每个数据集定义 canonical EEF frame,用 rigid offset 统一腕部或夹爪中心;对移动相机序列进行 camera motion decoupling;将人手转换为 21-point MANO 表示;丢弃遮挡、截断或运动学无效帧。
- 训练后处理:VLM 统一语言标注,补全缺失描述;移除没有有效 hand-object interaction 的片段;保留但标注低质量轨迹;按 human/robot、task、quality 组织 metadata。
6. 实验复现要点
6.1 RoboCasa-GR1 仿真实验
RoboCasa-GR1 包含 24 个 tabletop rearrangement 和 articulated-object manipulation 任务,使用 GR-1 humanoid robot 与 Fourier dexterous hands。输入是头戴相机的 egocentric RGB。所有模型按 GR00T 协议每任务微调 1,000 条轨迹,每任务评估 51 次,报告平均成功率。
| 模型 | 状态表征 | MM-DiT | VLM | 成功率 |
|---|---|---|---|---|
| GR00T-N1.6 | - | - | - | 47.6 |
| StarVLA | - | - | Qwen3-VL | 47.8 |
| GR00T-EI10k | - | - | Qwen3-VL | 51.3 |
| UWM-0.1B | VAE | No | No | 14.2 |
| UWM-1B | VAE | No | Qwen3-VL | 19.3 |
| UWM + MM-DiT | VAE | Yes | Qwen3-VL | 20.0 |
| LDA (DiT) | DINO | No | Qwen3-VL | 48.9 |
| LDA-0.5B | DINO | Yes | Qwen3-VL | 50.7 |
| LDA-1B | DINO | Yes | Qwen3-VL | 55.4 |
这个表最值得讲的不是“LDA 比 GR00T 高 7.8 个点”,而是消融逻辑:UWM 从 0.1B 扩到 1B、换 MM-DiT,都仍停在 20 左右;一旦换成 DINO latent,成功率跳到 55.4。这强烈支持作者关于结构化 latent state 的论点。

6.2 真实机器人实验
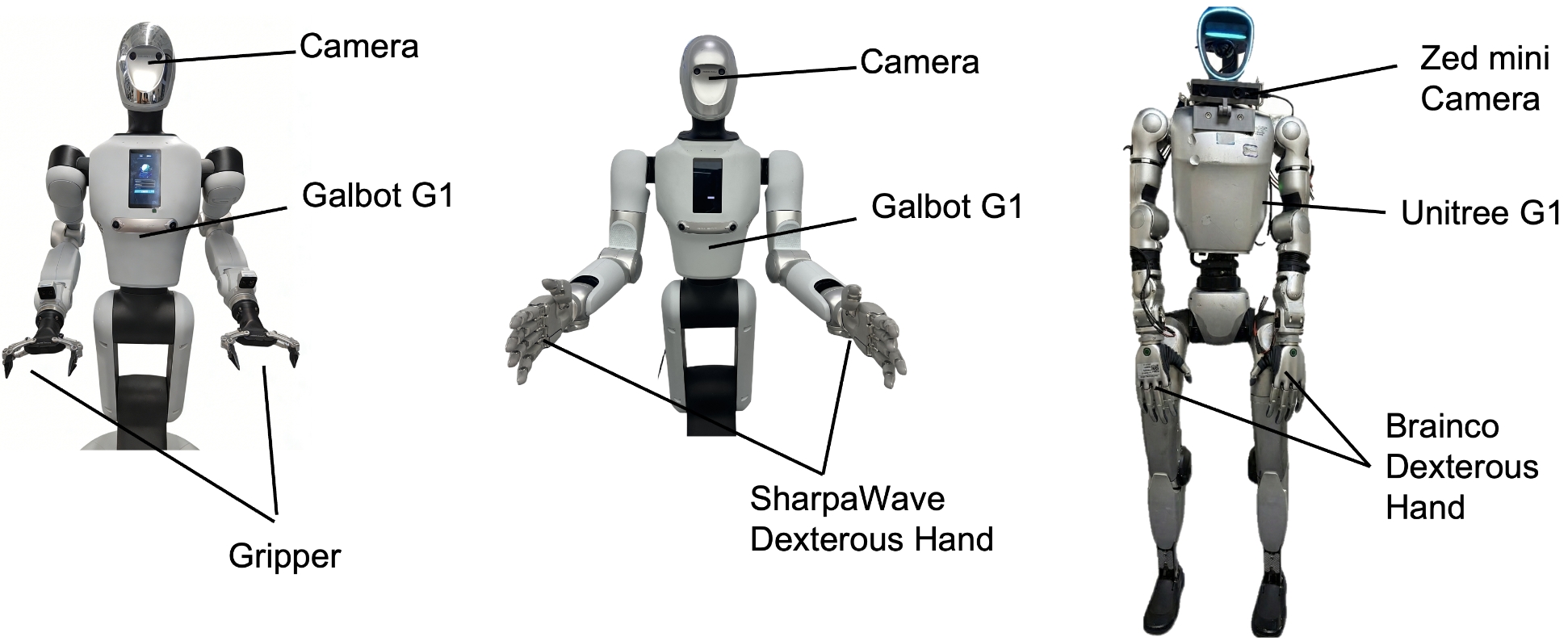
真实实验覆盖 Galbot G1 和 Unitree G1。Galbot G1 使用双 7-DoF 手臂,可安装两指夹爪或 22-DoF SharpaWave 灵巧手;Unitree G1 使用 10-DoF BrainCo hand。所有配置只用头戴相机 egocentric RGB。
| 任务类别 | 代表任务 | 为什么难 |
|---|---|---|
| Pick and Place | Pick Vegetable, Handover | 新机器人 embodiment 的少样本适配、物体位置随机 |
| Contact-rich | Flip Box, Beat Block | 接触力、碰撞、物体翻转后状态变化 |
| Fine Manipulation | Water Flower, Wipe Board | 连续闭环控制、姿态精度、工具接触 |
| Long-horizon | Sweep Table, Clean/Throw Rubbish | 多阶段流程,早期误差会累积到后续子任务 |
| Dexterous | Pull Nail, Flip Bread | 高维手指控制、稳定接触、工具使用和力方向 |
每个任务收集 100 条 teleoperation 轨迹,不强制全为专家演示;大约 50-80% 是专家行为,其余包含暂停、重试、低效动作。基线 $\pi_{0.5}$ 和 GR00T 只用过滤出的专家子集微调;LDA 用全部轨迹,通过 Universal Embodied Data Ingestion 吸收低质量数据的 dynamics 信息。
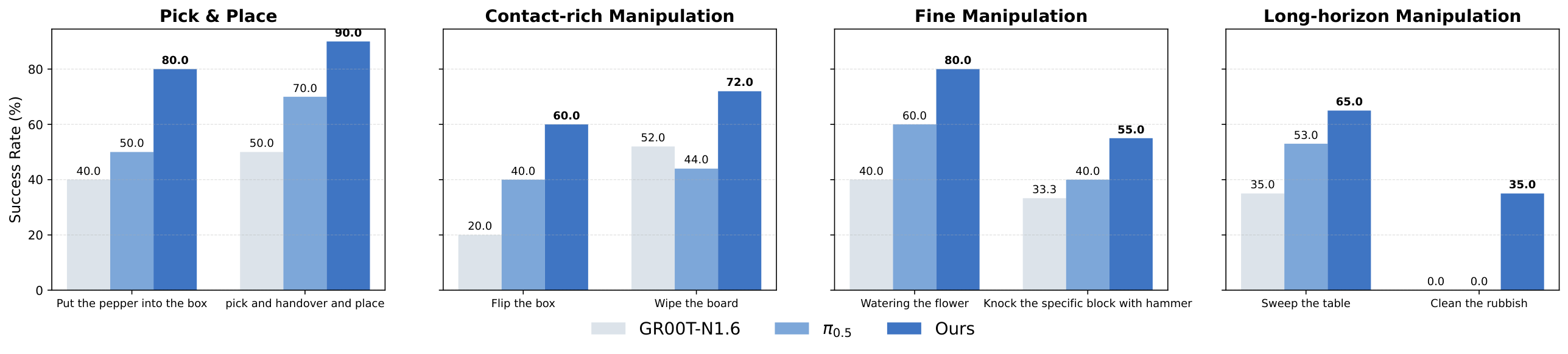
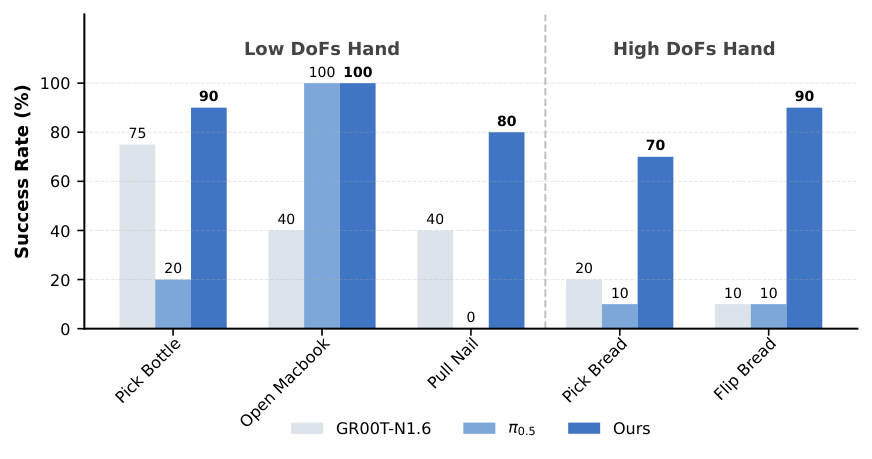
6.3 泛化与混合质量微调
| 模型 | Novel Object | Unseen Background | OOD Position |
|---|---|---|---|
| $\pi_{0.5}$ | 26.7 | 20.0 | 6.7 |
| GR00T | 40.0 | 40.0 | 20.0 |
| LDA-1B | 60.0 | 60.0 | 40.0 |
| 任务 | 模型 | High only | High + Low | 变化 |
|---|---|---|---|---|
| Place pen into box | $\pi_{0.5}$ | 60 | 40 | -20 |
| Place pen into box | LDA | 70 | 80 | +10 |
| Bimanually remove lid | $\pi_{0.5}$ | 50 | 40 | -10 |
| Bimanually remove lid | LDA | 50 | 60 | +10 |
这个实验直接验证了论文最中心的 claim:低质量数据对普通 BC 基线有害,但对 LDA 可以有益,因为 LDA 不把这些轨迹等价当作专家动作,而是从中学习 dynamics 和视觉状态转移。
6.4 Scaling 分析
作者在 held-out Agibot World 上用 action prediction L1 error 作为可复现 proxy,比较模型容量、数据规模和训练目标。训练配置包括 Policy Only、Policy + Visual Forecasting、Policy with Forward/Inverse Dynamics,以及 full co-training。
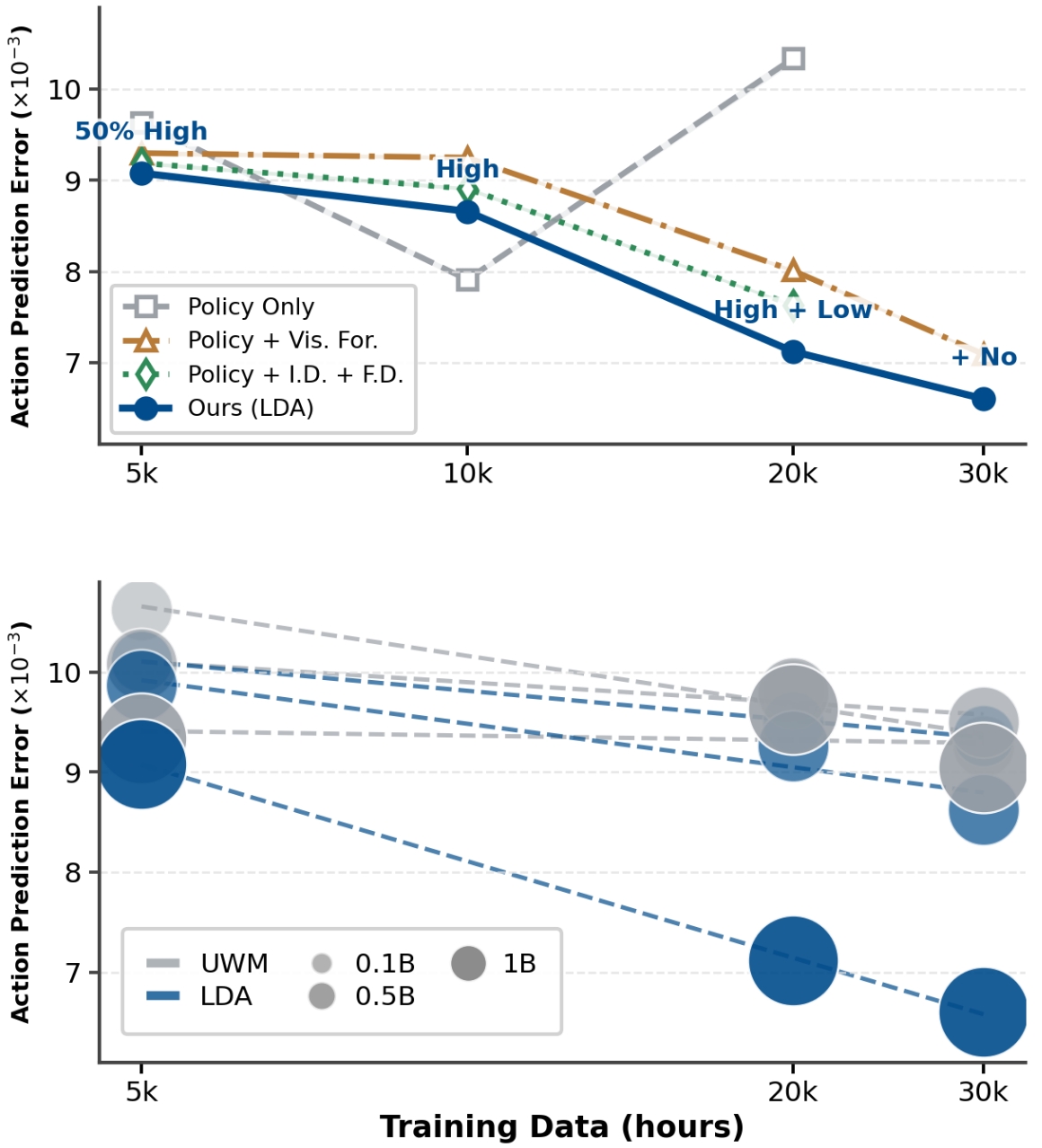
7. 结果分析与讨论
7.1 这篇论文最有价值的地方
最有价值的不是单个 benchmark 数字,而是提出了一个比较清晰的数据利用范式:把异构具身数据拆成可监督的条件分布,而不是统一塞进 BC。这个范式对机器人学习很实际,因为真实数据永远不是干净的 expert-only demo。人类视频、失败轨迹、半成功轨迹、低质量 teleop、仿真数据各自都“不完美”,但它们可以分别服务于 dynamics、visual forecasting 或 policy。
第二个价值是把未来视觉预测从像素空间转移到 DINO latent。很多 robot world model 之所以不稳定,是因为预测目标太像视频生成任务;LDA 则把未来状态表征为更接近控制相关语义的 latent,从而让 dynamics 学习更有针对性。
7.2 结果为什么站得住
论文的证据链比较完整,原因有三点。
- 消融能隔离关键组件:UWM 扩大到 1B 或加入 MM-DiT 后仍只有 19.3/20.0,而 DINO latent LDA 达 55.4,说明表征空间是主要因素之一;去掉 MM-DiT 从 55.4 降到 48.9,说明架构也有贡献。
- 数据角色 claim 有直接实验:混合质量微调里,加入低质量数据使 $\pi_{0.5}$ 下降而使 LDA 上升,正好对应 Universal Data Ingestion 的核心论点。
- 真实机器人任务覆盖多种失败模式:从简单 pick-and-place 到 long-horizon rubbish cleaning、pull nail、flip bread,任务难点不只是视觉识别,而是接触、工具、力方向、时序误差恢复。
7.3 Dynamics 学到了什么
论文用两类可视化支持“模型真的在学动作条件化状态转移”。第一类是 DINO latent forward dynamics 的 PCA 可视化,显示预测未来特征能保持 object permanence、contact continuity 和 motion consistency。第二类是 action-conditioned attention:对同一观察,比较 active action 与 No-Op 条件下的 attention,取差值 $\Delta A = |A_1-A_2|$,从而消除静态视觉显著性,突出动作引起的因果相关区域。
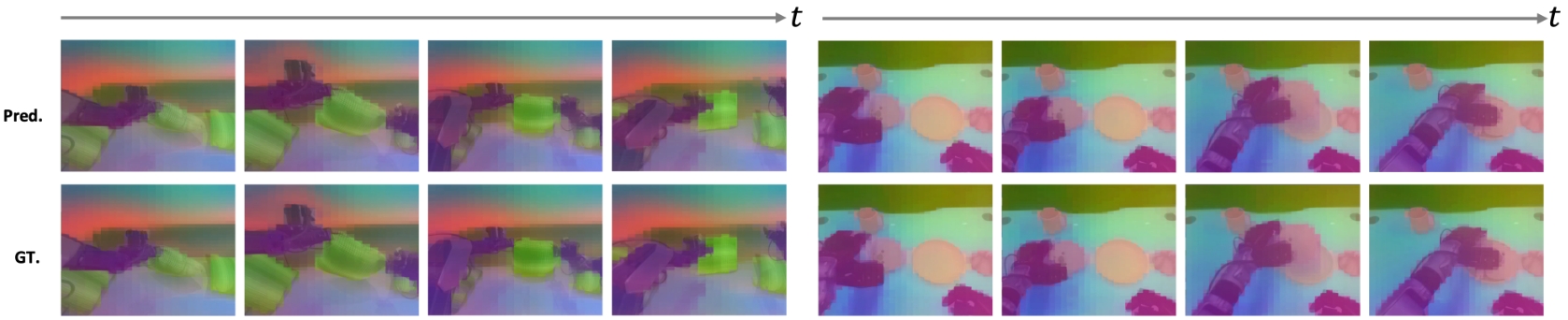

7.4 局限与风险
固定 DINO 表征的上限:DINO 是通用视觉表征,不一定为机器人接触、力学、可操作性最优。作者也承认未来需要联合学习 visual representation 和 latent dynamics。
视角偏置:数据和实验主要是 egocentric camera,迁移到外部多视角、触觉、力觉或事件相机等多模态设置仍未充分验证。
数据工程门槛高:EI-30K 的坐标对齐、语言标准化、质量标注和清洗是巨大工程。若这些过程不可复现或不开源不足,方法的“普适”会打折。
action prediction L1 只是 proxy:scaling 曲线很有说服力,但最终仍需更多真实部署任务验证 proxy 与实际成功率的相关性。
8. 组会追问清单
Q1: LDA 和普通 diffusion policy 的本质区别是什么?
普通 diffusion policy 主要去噪动作;LDA 同时去噪动作和未来 DINO latent,并通过 task embedding 切换 policy、forward dynamics、inverse dynamics、visual forecasting。因此它不仅学“该怎么做”,还学“做了之后世界怎样变”。
Q2: 为什么低质量数据对 LDA 有用,对 $\pi_{0.5}$ 有害?
如果直接 BC,低质量动作会污染 policy target;LDA 可以把低质量轨迹更多用于 dynamics 或视觉预测,让模型学习接触、状态转移、失败恢复等非专家但真实的环境信息。微调实验中 LDA +10%,$\pi_{0.5}$ 下降,正是这个机制的证据。
Q3: DINO latent 会不会丢掉机器人控制需要的细粒度几何?
这是合理担忧。作者的实验证据表明 DINO latent 比 VAE/pixel-space UWM 更适合当前任务,尤其 RoboCasa 从 20.0 到 55.4 的差距很大。但 DINO 是否足够表达精细接触、力觉和不可见状态仍是限制,论文结论也提出未来要 joint representation learning。
Q4: 1B 参数为什么能比 3B GR00T 更好?
论文的解释不是“参数更多”,而是“训练目标和状态空间更对”。LDA 用 1B 参数同时学习动作和 latent dynamics;GR00T-N1.6 虽为强基线,但主要还是 policy-centric。RoboCasa 里 LDA-1B 55.4,高于 3B GR00T-N1.6 的 47.6。
Q5: 如果我想复现,最难的部分在哪里?
模型结构不是唯一难点。更难的是 EI-30K 风格的数据统一:action frame 对齐、camera frame 解耦、MANO/robot gripper 表示统一、语言重标注、质量标签,以及不同任务 loss 的正确激活。
9. 复现信息
9.1 资源链接
- arXiv: https://arxiv.org/abs/2602.12215
- Project page: https://pku-epic.github.io/LDA
- Code: https://github.com/jiangranlv/latent-dynamics-action
- Data: project page 标注为
Data (Coming Soon)。
9.2 训练设置速记
VLM: Qwen3-VL
Observation encoder: DINOv3-ViT-s
MM-DiT: hidden 1536, layers 16, heads 32
Image: 224x224x3
DINO latent: 14x14x384
Action chunk: 16
Pretraining batch: 32 * 48
Finetuning batch: 12 * 8
Optimizer: AdamW, lr 1e-4, wd 1e-5, betas [0.9, 0.95]
Schedule: cosine, min lr 5e-7
Compute: 48 H800 GPUs, 400k iterations, 4,608 GPU hours9.3 本报告的覆盖检查
本报告已覆盖 Abstract、Introduction、Related Work、Latent Dynamics Action Model、EI-30K、Experiments、Conclusion,以及附录中的模型超参、RoboCasa 逐任务结果、真实机器人任务协议、EI-30K 数据处理 pipeline、action-conditioned attention 和 latent dynamics 可视化。附录内容已按主题整合进方法、数据、实验和讨论章节。
生成日期:2026-05-08。源码、PDF 和解压目录已保留,便于后续补读或核查。