1. Quick overview of the paper
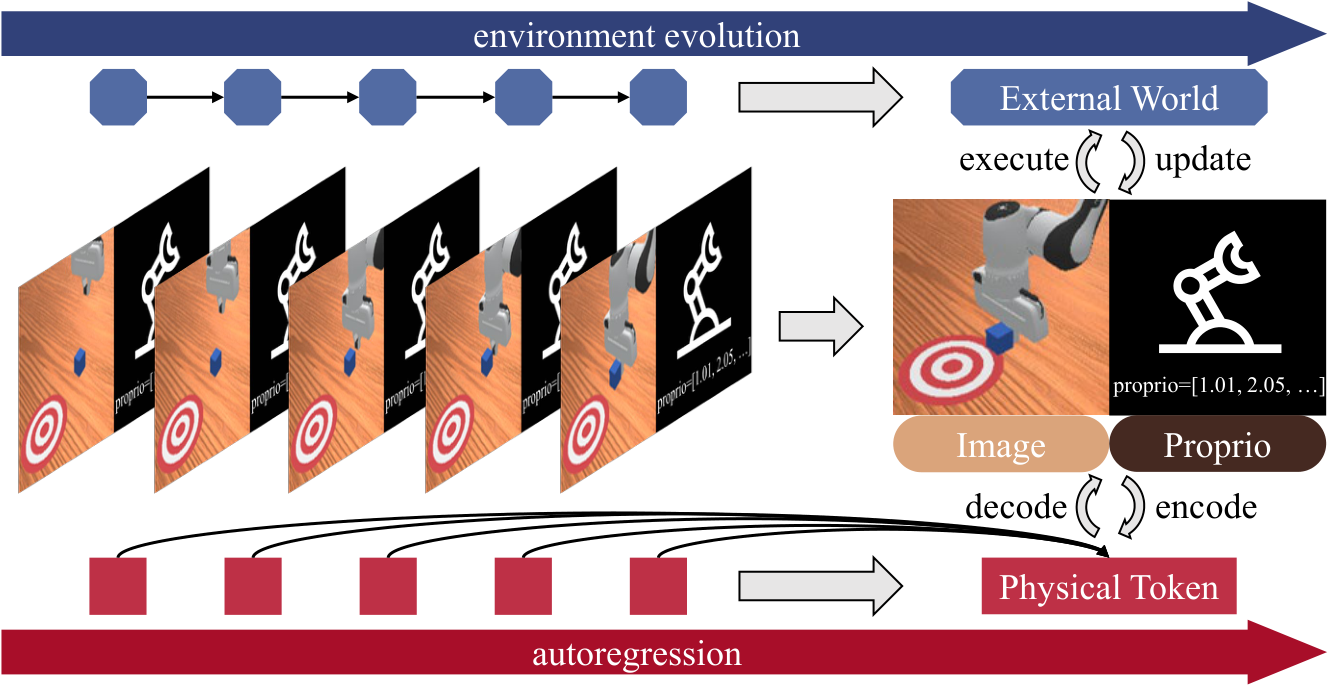
The core idea of PhysGen is: don't just use the pre-trained language model as the "brain" of the robot strategy, but also use the pre-trained autoregressive video generation model as an implicit physics simulator. The model projects visual frames and action blocks into the same continuous physical token space, uses a causal transformer to predict the next set of "visual + action" tokens, and then uses a diffusion de-tokenizer to restore future images and executable actions.
| What should the paper solve? | Robot operation lacks large-scale action teaching data; VLA relies on the symbolic knowledge of LLM/VLM, but operation requires continuous space, time and physical interaction. The author hopes to transfer the physical prior of "how the object will move" from the video generation model and learn control with less robot data. |
|---|---|
| The author's approach | Based on the NOVA autoregressive video generation backbone, PhysGen is proposed: combine video frame tokens and action chunk tokens into physical tokens; use continuous diffusion de-tokenizer to model visual and action distribution; add inverse-kinematics causal mask, Lookahead Multi-Token Prediction, LoRA training and KV-cache inference. |
| most important results | The average success rate of LIBERO is 90.8%, higher than OpenVLA 77%, WorldVLA 82%, and Pi0-Fast 86%; ManiSkill averages 74%, and PushCube reaches 100%; the real Franka Panda four tasks average 75%, which is the same as Pi0, and 75% vs Pi0 70% in transparent object grabbing. |
| Things to note when reading | "The video generation model can be used as a physical simulator" is a strong idea, but the implementation does not directly use the video generation results for planning, but changes the video generation backbone to joint video-action autoregression. The core evidence comes from continuous tokens, video pre-training, AR rollout, and L-MTP ablation. |
2. Motivations and issues
2.1 Why not continue to pile action data?
The paper starts from the scarcity of robot data: large-scale generative pretraining can bring cross-task generalization in NLP and vision, but robot action teaching is expensive, time-consuming, and strongly hardware-dependent. The VLA method connects LLM/VLM to the action head and can transfer language and visual knowledge, but there is a modal gap between text/action: language is a symbolic description, and robot action is a continuous, geometric, and time-sensitive control signal.
The author believes that the video generation model is closer to the knowledge required by the robot: the video model must predict future frames from historical frames, and therefore implicitly learns physical priors such as object permanence, motion trends after contact, and temporal consistency. Autoregressive video generation is particularly like a sequential decision process in control because it predicts the future in a rolling, step-by-step manner.
2.2 Problems with traditional tokenization
Many autoregressive models rely on discrete tokens. Discretization is natural for language, but the nature of latent images and actions is continuous signals, and quantization will bring resolution errors. For robots, small motion quantization errors may accumulate into trajectory drift over long time series. PhysGen therefore advocates continuous tokens: both vision and action are modeled in continuous embedding space, and then diffusion loss is used to learn conditional distribution.
3. Related job positioning
| direction | Representation method | How authors position PhysGen |
|---|---|---|
| Vision-Language-Action Models | RT series, OpenVLA, $\pi_0$, GR00T, etc. | These methods mostly transfer knowledge from LLM/VLM and then connect the action head. PhysGen also uses an autoregressive architecture, but the backbone comes from a video generation model rather than a language model. |
| Video-Action Joint Prediction | WorldVLA, UWM, UniMimic, UVA, etc. | There have been works that jointly predict vision and action, but PhysGen emphasizes step-by-step physical autoregression and uses shared continuous token representations to reduce discretization errors. |
| Non-Quantized Autoregressive Models | MAR, NOVA, etc. | MAR uses a denoising process to model continuous token conditional distributions; NOVA extends it to video generation. PhysGen adds action tokens on this basis to become a unified vision-action autoregression. |
4. Preliminary knowledge
4.1 How Diffusion loss serves as a probabilistic model for continuous tokens
The ordinary diffusion model gradually adds noise to the clean sample $x_0$:
$$q(x_t \mid x_{t-1})=\mathcal{N}(x_t; \sqrt{1-\beta_t}x_{t-1}, \beta_t I).$$
The training goal is to have the network predict the injected noise:
$$L(\theta)=\mathbb{E}_{t, x_0, \epsilon}\left[\left\|\epsilon-\epsilon_\theta(\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon, t)\right\|^2\right].$$
The key inspiration of MAR/NOVA is: given the autoregressive context $z$, you can directly train the denoiser $\epsilon_\theta(x_t|t, z)$ to learn $p(x|z)$ without quantizing the continuous signal into a discrete vocabulary:
$$\mathcal{L}(z, x)=\mathbb{E}_{\epsilon, t}\left[\|\epsilon-\epsilon_\theta(x_t|t, z)\|^2\right].$$
PhysGen applies this idea to de-tokenization of frame tokens and action tokens.
4.2 What NOVA offers
NOVA is a continuous, non-quantized autoregressive video generation model. It is modeled by time:
$$p(l, S_1, \dots, S_N)=\prod_{n=1}^{N}p(S_n|l, S_1, \dots, S_{n-1}), $$
And it is generated autoregressively in the form of token set within the frame. PhysGen retains NOVA's language and visual embedding mechanism, allowing it to inherit the world dynamic knowledge in video pre-training, and then adds action tokens and action diffusion de-tokenizers.
5. Detailed explanation of method
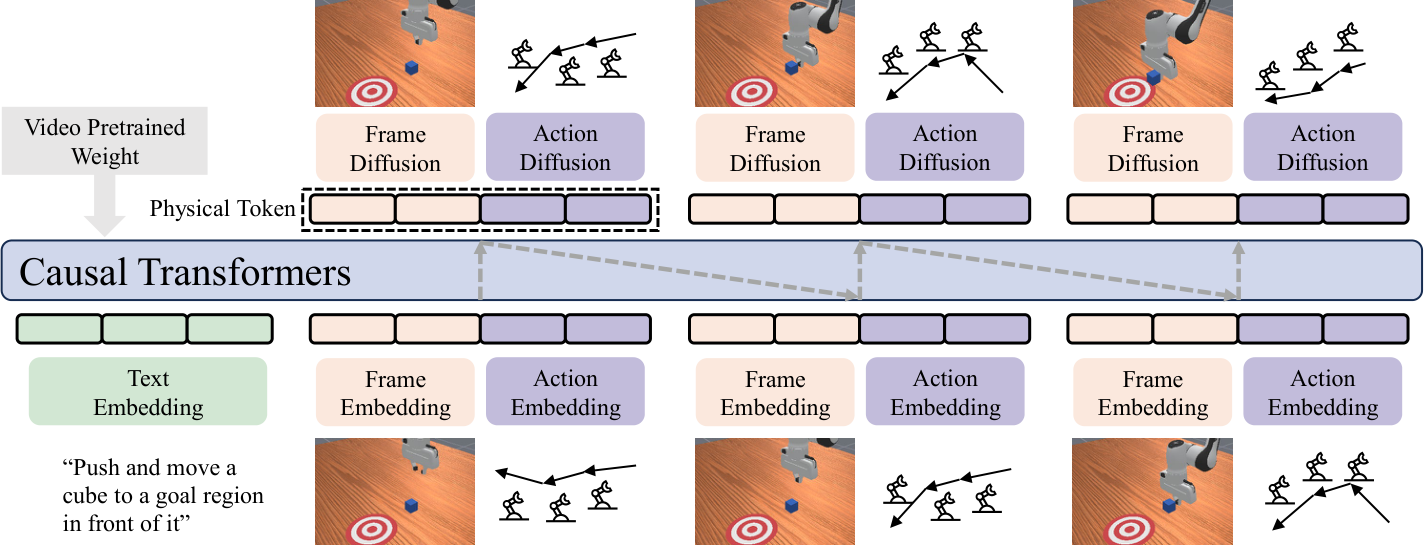
5.1 Input and output: predict next step from historical vision and actions
At step $n$, PhysGen inputs the task instruction $l$, the historical image $\{O_0, \dots, O_{N-1}\}$ and the corresponding action block $\{A_1, \dots, A_{N-1}\}$, and outputs the next frame visual state $O_N$ and the next action block $A_N$. Each action block $A_n$ contains $L$ consecutive actions, $L=8$ in the experiment.
The meaning of this formulation is that the model does not only predict actions, but predicts "how the actions and the environment evolve together." This makes it more like a predictive world interaction model than a pure policy head.
5.2 Tokenizer: Put language, vision, and action into the same space
| modal | encoding method | Whether to freeze | output |
|---|---|---|---|
| language instructions | Phi language model tokenizer/encoder | Freeze | $E_l\in\mathbb{R}^{K_l\times d}$ |
| visual frame | NOVA's original 3D-VAE, flattened into frame tokens | Freeze | $E_{O, n}\in\mathbb{R}^{K_O\times d}$ |
| action block | MLP action tokenizer | training | $E_{A, n}\in\mathbb{R}^{K_A\times d}$, among which $K_A=L$ |
Each physical token is composed of visual tokens and action tokens concatenated along the sequence dimension:
$$P_n=[E_{O, n}; E_{A, n}], \quad P_n\in\mathbb{R}^{(K_O+K_A)\times d}.$$
Since observation precedes action, the author adds a learnable Begin-of-Action token before the action sequence to align the length.
5.3 Physical Autoregression
PhysGen follows LLM's token-by-token autoregression, but token now represents the joint physical state of vision and action:
$$p(E_l, P_0, \dots, P_N)=\prod_{n=0}^{N}p(P_n|E_l, P_0, \dots, P_{n-1}).$$
The conditional distribution is parameterized by a Causal Transformer replicating the NOVA architecture. Transformer output condition vector $Z_n$:
$$Z_n=\mathrm{Transformer}(l, P_0, \dots, P_{n-1}).$$
5.4 De-tokenizer: Continuous diffusion restores vision and action
Given $Z_n$, PhysGen estimates $p(P_n|Z_n)$ using the DiT-based denoising process:
$$\mathcal{L}(P_n, Z_n)=\mathbb{E}_{\epsilon, t}\left[\|\epsilon-\epsilon_\theta(P_{n, t}|t, Z_n)\|^2\right].$$
The reverse sampling form is:
$$P_{n, t-1}=\frac{1}{\sqrt{\alpha_t}}\left(P_{n, t}-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_\theta(P_{n, t}|t, Z_n)\right)+\sigma_t\delta.$$
The de-tokenization of vision and action is done separately: the frame token uses NOVA's reconstruction paradigm; the action token uses lightweight Action-DiT, and the condition vector is injected through cross-attention.
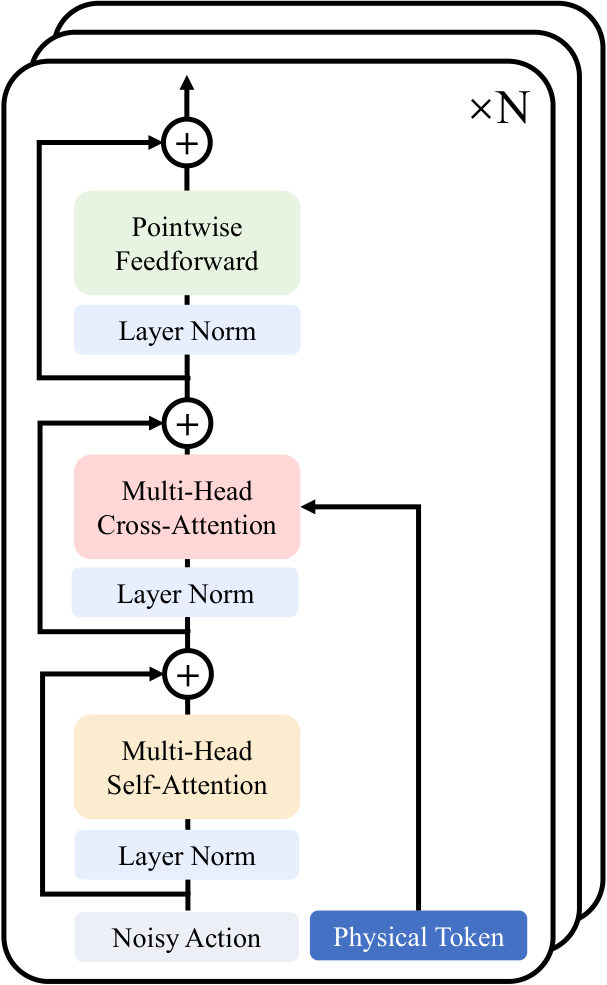
5.5 Causal Mask and Implicit Inverse Kinematics
PhysGen's attention mask is designed for the joint token of "frame + action".
- Frame part uses chunk-wise full attention: patches in the same frame can pay attention to each other.
- Action part uses temporal causal attention: early actions within the action block cannot see subsequent actions.
- Action tokens can attend one-way to frame tokens: action planning can be conditioned on visual states, which the authors claim facilitates implicit inverse kinematics.
- Maintain temporal causality across chunks to avoid future information leakage.

5.6 Lookahead Multi-Token Prediction
L-MTP combines lookahead action generation and Multi-Token Prediction. In each autoregressive step, the action de-tokenizer generates multiple future tokens in parallel, which is 3 tokens in the paper implementation. All prediction tokens are supervised during training; only the first token is executed during inference, and the remaining tokens are used as lookahead information to condition subsequent predictions.
This is equivalent to allowing the model to retain short-term future plans while executing the current action, mitigating the short-term problem of single token rollout, and improving long-term consistency.
5.7 Training goals and implementation details
The total loss is the average diffusion loss of frames and actions over the sequence:
$$loss=\sum_{n=1}^{N}\mathcal{L}(Z_n, P_n)=\sum_{n=1}^{N}\left(\mathcal{L}_{obs}(Z_n, E_{O, n})+\mathcal{L}_{act}(Z_n, E_{A, n})\right).$$
| Project | settings |
|---|---|
| action block length | $L=8$ |
| Transformer maximum context | 2096 tokens |
| context composition | 256 language tokens + 5 physical token packages |
| Each physical package | 360 visual tokens + 8 action tokens |
| Multi-view input | Splice it into one image and send it to VAE and AR transformer |
| training efficiency | Teacher forcing is fully parallel; Transformer backbone uses LoRA fine-tuning |
| Reasoning efficiency | KV-cache caches intermediate features of each layer |
| Hardware and time | Single NVIDIA A100-SXM4-80GB; maximum training time 60 GPU hours |
| position encoding | RoPE; frame and action token use different frequency settings |
6. Experimentation and reproducibility
6.1 LIBERO simulation experiment
The LIBERO experiment evaluates four suites: Spatial, Object, Goal, and Long. Each suite has about 400 demonstrations for fine-tuning and 500 rollouts for evaluation, and the indicator is success rate. The author emphasizes that "no action pretraining" means that the backbone is not pretrained on large-scale manipulation/action data.
| Method | Params | Spatial | Object | Goal | Long | Avg. |
|---|---|---|---|---|---|---|
| DP, w/o action pretraining | - | 78 | 93 | 68 | 51 | 72 |
| OpenVLA | 7B | 85 | 88 | 79 | 54 | 77 |
| ThinkAct | 7B | 88 | 91 | 87 | 71 | 84 |
| Pi0-Fast | 3B | 96 | 97 | 89 | 60 | 86 |
| MolmoACT | 7B | 87 | 95 | 88 | 77 | 87 |
| UniMimic, w/o action pretraining | ~200M | 71 | 79 | 67 | 29 | 62 |
| WorldVLA, w/o action pretraining | 7B | 88 | 96 | 83 | 60 | 82 |
| PhysGen, w/o action pretraining | 732M | 91.0 | 99.6 | 93.8 | 78.8 | 90.8 |
Key points in the interpretation of the results: PhysGen averages 90.8, which not only exceeds the LLM/VLM-based baseline, but also exceeds the visual generation pre-training baseline WorldVLA by 8.8 points; it is 18.8 points higher than WorldVLA in the Long suite, which supports the author's claim that continuous AR world interaction modeling improves long-term consistency. The only weak entry is Spatial, which is lower than Pi0-Fast's 96, which the authors attribute to the underlying video model's limited spatial awareness.
6.2 ManiSkill simulation experiment
ManiSkill selects three tasks: PushCube, PickCube, and StackCube. Each task uses 1000 demonstrations for fine-tuning and 125 rollouts for evaluation.
| Method | PushCube | PickCube | StackCube | Avg. |
|---|---|---|---|---|
| ACT | 76 | 20 | 30 | 42 |
| BC-T | 98 | 4 | 14 | 39 |
| DP | 88 | 40 | 80 | 69 |
| ICRT | 77 | 78 | 30 | 62 |
| RDT | 100 | 77 | 74 | 84 |
| Pi0 | 100 | 60 | 48 | 69 |
| PhysGen | 100 | 73 | 48 | 74 |
PhysGen on ManiSkill is not as high on average as RDT, but better than ICRT and Pi0, especially PushCube by 100%. This suggests that the video prior is helpful, but does not necessarily outperform the action-pretrained policy across all manipulation settings.
6.3 Real robot experiment
The real experiment uses a Franka Panda with two RealSense D415 cameras, one fixed and one on the wrist. The four tasks are Pick Cube, Press Button, Stack Cube, and Pick Transparency. Collect 80-100 teleoperation demonstrations per task and evaluate 20 trials. ACT is trained from scratch, and OpenVLA and Pi0 use official checkpoints for fine-tuning; PhysGen only uses these collected data for fine-tuning, and backbone does not have large-scale action pre-training.

| Method | Pick Cube | Press Button | Stack Cube | Pick Transparency | Avg. |
|---|---|---|---|---|---|
| ACT | 40 | 40 | 30 | 10 | 30 |
| OpenVLA | 30 | 25 | 10 | 0 | 16.3 |
| Pi0 | 85 | 85 | 60 | 70 | 75 |
| PhysGen | 80 | 85 | 60 | 75 | 75 |
6.4 Ablation experiment
Ablation is performed on LIBERO-Object, and the metric is success rate.
| Variant | Pretrain | Token | L-MTP | Backbone | SR | explain |
|---|---|---|---|---|---|---|
| PhysGen-Zero | No | continuous | + | AR | 86.4 | No video pre-training as a control to test NOVA prior |
| PhysGen-Discrete | NOVA | discrete | + | AR | 94.2 | Actions are quantified into discrete words and the value of continuous tokens is tested. |
| PhysGen-NoAR | NOVA | continuous | - | NoAR | 95.0 | Remove the autoregressive rollout, equivalent to $N=1$ single-step mapping |
| PhysGen-STP | NOVA | continuous | - | AR | 96.8 | Single token prediction, remove Lookahead-MTP |
| PhysGen-Full | NOVA | continuous | + | AR | 99.6 | complete model |
Ablation corresponds to four conclusions: video pre-training brings +13.2; continuous token versus discrete brings +5.4; AR architecture brings +4.6; L-MTP brings +3.4.
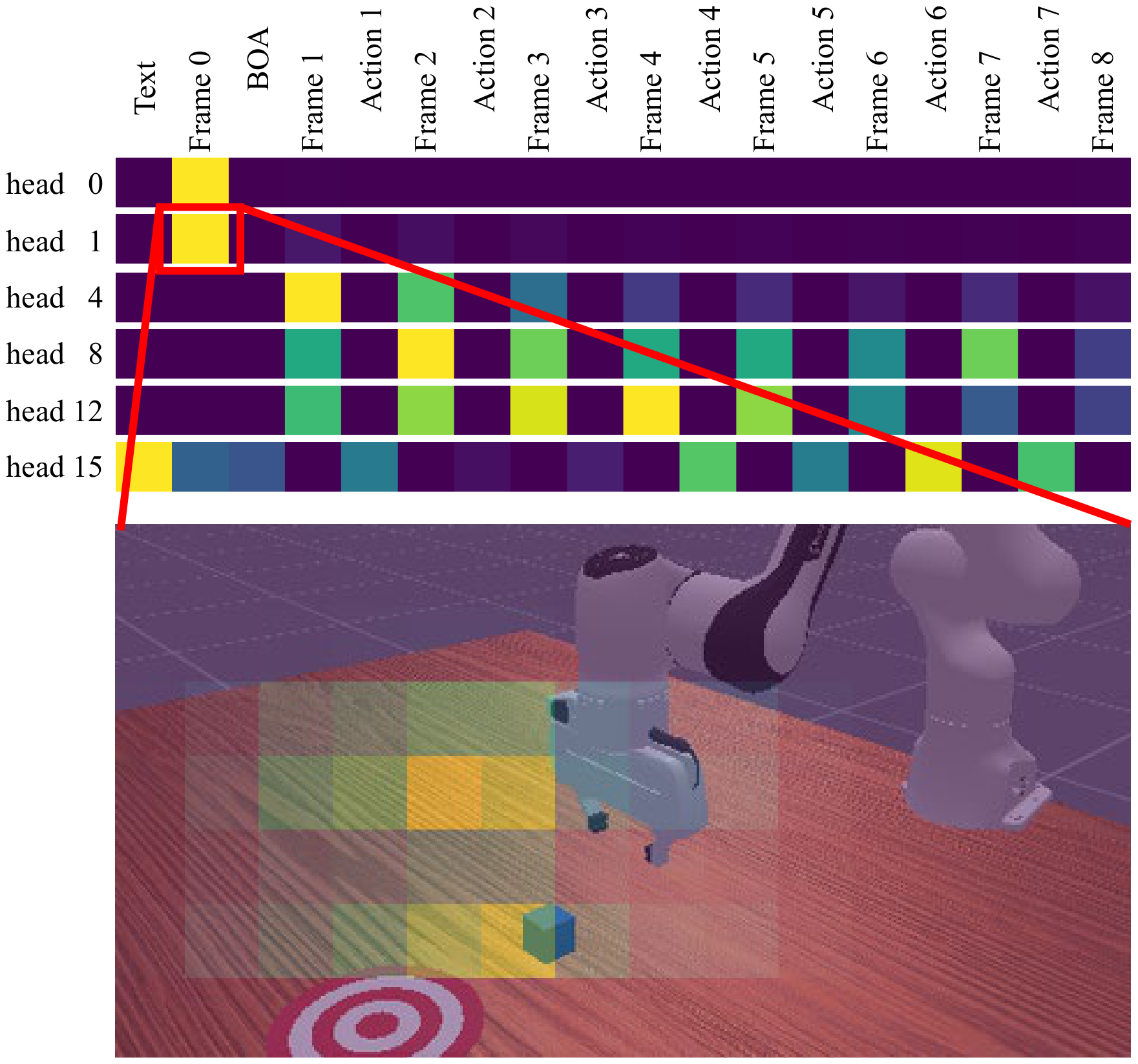
6.5 Qualitative analysis

7. Discussion and limitations
7.1 The most valuable part of this paper
The most valuable thing is that it turns the sentence "there is physical knowledge in the video generation model" into a trainable robot strategy structure. It does not stop at the indirect route of "generating videos and extracting actions from the videos", but directly incorporates actions into the autoregressive video token stream, allowing the model to predict future vision and actions at the same time. This allows video prior, motion control and sequence planning to interact within the same model.
The second value is the continuous token. The continuity of robot movements and visual latent is very important. Discrete tokens are natural in language, but they are prone to accuracy losses in control. PhysGen uses a diffusion de-tokenizer to learn continuous conditional distributions, avoiding hard quantization while maintaining generative modeling capabilities.
7.2 Why the results hold up
- The ablation closed loop is relatively complete: Video pre-training, continuous token, autoregression, and L-MTP have corresponding ablation respectively, and each has a positive return.
- Compare to strong baseline: Comparing OpenVLA, Pi0-Fast, WorldVLA, and MolmoACT on LIBERO; comparing Pi0 in real experiments, it shows that it is not just about weakening the baseline.
- The real transparent object task has recognition: Pick Transparency involves visual ambiguity caused by reflection/refraction, which is a good way to test whether video physics priors help control.
7.3 Things to be careful about
"Video model = physics simulator" is still a metaphor: What the video generation model learns is the physical laws in visual statistics, which is not necessarily equivalent to a controllable and verifiable dynamics model. It may predict visually reasonable but controllably wrong states.
Real experiments are smaller: Four Franka tabletop tasks, with 20 trials each, demonstrate feasibility but are not sufficient to illustrate broad real-world generalization.
ManiSkill is not ahead across the board: The average of 74 is lower than RDT's 84, and StackCube is lower than DP/RDT. This shows that video priors without action pre-training are not a silver bullet for all scenarios.
The source code does not contain the actual appendix: The text mentions that the details of the actual task are in the Appendix, but the appendix input in LaTeX is commented out. Therefore, some task definition details cannot be further verified from the source code.
8. Questioning at the group meeting
Q1: What is the biggest difference between PhysGen and WorldVLA/UWM?
They all focus on video-action joint prediction, but PhysGen explicitly uses the NOVA-style continuous non-quantized autoregressive backbone to combine frame tokens and action tokens into physical tokens to gradually predict the co-evolution of the world and the robot; at the same time, it uses diffusion de-tokenizer to model continuous visual/action distribution.
Q2: Why is it not considered a leak if the action token can attend to future visual states?
What the author means is that within the same physical chunk, action planning can read the corresponding visual token representation, thereby forming a visual conditioned inverse kinematics relationship; the temporal causal mask is still maintained across chunks. It should be noted here that "future visual states" are more like structured conditions for combining tokens within chunks, rather than unlimited reading of real future trajectories.
Q3: Why only the first token is executed during L-MTP inference?
Subsequent tokens are used as lookahead information to help the current prediction have a longer planning horizon; only executing the first token can retain the feedback ability of receding-horizon control, and the next step is to re-predict based on real environment feedback.
Q4: How is continuous diffusion de-tokenizer better than MLP regression?
MLP regression gives deterministic point estimates and easily averages multi-modal actions. The diffusion de-tokenizer learns the conditional distribution $p(P_n|Z_n)$, which retains both continuous accuracy and the ability to generate models to express multi-modal output.
Q5: If it happens again, where is the most likely pitfall?
The first is the token organization and mask: language, 5 physical packages, and 360 visual + 8 action tokens per package must be aligned; the second is the diffusion sampling of action de-tokenizer and the multiple sampling of $t$ during training; the third is whether the input distribution of the original NOVA VAE matches after multi-view splicing.
9. reproducibility information
9.1 Link and code status
- arXiv: https: //arxiv.org/abs/2603.00110
- Hugging Face paper page: https: //huggingface.co/papers/2603.00110
- There is no PhysGen official code repository link provided in the source code LaTeX; Web search also did not find the official GitHub that clearly corresponds to `2603.00110`.
9.2 Minimum Reproducible Configuration Shorthand
Backbone: NOVA autoregressive video generation model
Language tokens: frozen Phi language model
Visual tokenizer: frozen 3D-VAE from NOVA
Action tokenizer: MLP, K_A = L = 8
Physical token: concat(frame tokens, action tokens)
Context length: 2096 = 256 language + 5 * (360 visual + 8 action)
De-tokenizer: frame diffusion + Action-DiT action diffusion
Training: teacher forcing, LoRA finetuning, 4 samples of t per image/action
Inference: autoregressive rollout with KV-cache
Hardware: single A100-SXM4-80GB, longest finetuning within 60 GPU hours9.3 Coverage check
This report has covered the core content of Abstract, Introduction, Related Work, Preliminaries, Method, Experiment, and Conclusion. The source code contains `\appendix` but the appendix file input is commented and no actual appendix text was found to be integrated; this is noted in the report.
Generation date: 2026-05-08. The source code package, PDF and decompression Contents are left uncleaned to facilitate subsequent verification.