S-VAM: Shortcut Video-Action Model by Self-Distilling Geometric and Semantic Foresight
1. Quick overview of the paper
Difficulty rating: ★★★★☆. Need to understand VLA/VAM, Stable Video Diffusion, diffusion model denoising characteristics, Vision Foundation Model characterization, token condensation/QFormer/Perceiver, and diffusion policy.
Keywords: Video-Action Model, Self-Distillation, Geometric Foresight, Semantic Foresight, Vision Foundation Models, Diffusion Policy.
| Reading positioning issues | answer |
|---|---|
| What should the paper solve? | Existing VAM either relies on slow multi-step video generation or uses noisy one-step diffusion features, making it difficult to simultaneously satisfy real-time control and high-quality future prediction. |
| The author's approach | Use the diffusion model to extract VFM teacher targets from the multi-step video generated by itself, and then train lightweight geometric/semantic decouplers to directly predict these teacher representations from single-step denoising features. |
| most important results | The average sequence length of CALVIN is 4.16, and the average success rate of MetaWorld is 72.8%; the real two-arm Cobot is better than VPP in four tasks, and the effective control frequency is 25 Hz when the action chunk is 8. |
| Things to note when reading | The core is not to simply integrate VFM features into the strategy, but to teacher target multi-step generated videos from the same diffusion trajectory to avoid trajectory mismatch between GT future frames and one-step features. |
Core contribution list
- S-VAM shortcut is proposed.Bypass the inference latency of iterative video generation and obtain future representations that can be used for control with a single denoising forward pass.
- Propose geometric/semantic foresight self-distillation.Using DPAv3 and DINOv2 to extract teacher representations from SVD multi-step generated videos, supervised decouplers learn to recover structured foresight from noisy one-step features.
- Propose Uni-Perceiver action expert conditional aggregation.Compress geometric, semantic and original diffusion features into compact tokens as conditions for diffusion policy.
- Verification in simulation and real robots.Covers CALVIN, MetaWorld and AgileX Cobot real-arm tasks, and provides component ablation and VFM teacher target ablation.
2. Motivation
2.1 What problem should be solved?
The VLA model usually connects the pre-trained VLM to the action head, and then uses the robot action data to fine-tune it. The problem is that VLM mainly comes from static graphics and text pre-training and does not have the spatiotemporal foresight required for physical interaction; if it relies entirely on robot action data to learn dynamic rules, the data cost will be very high.
The VAM route attempts to use the video diffusion model to generate a visual plan, and then let the action expert predict and control based on the visual plan. This can take advantage of dynamic priors in Internet videos and reduce reliance on robot action data.
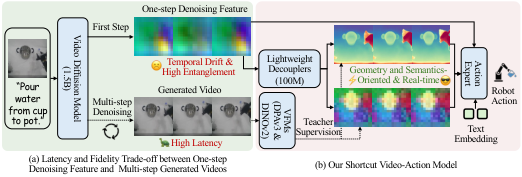
2.2 Limitations of existing methods
- Multi-step video generation: Multi-step denoising can produce higher-fidelity visual images, but the inference delay is high and is not suitable for real-time control.
- One-step feature extraction: Single-step feature diffusion is fast, but the features are noisy and entangled, making it difficult to stably express geometric structures, object semantics, and future interactions.
- Direct action learning: Without explicitly introducing video model dynamic priors, physical dynamics need to be learned from limited robot data.
- Use GT future frames for distillation: The paper ablation points out that GT future frames and one-step diffusion features are not on the same generated trajectory, which will cause trajectory misalignment and the performance will drop from 4.16 to 3.82.
2.3 The solution ideas of this article
This article treats "slow multi-step generation of stable structured representations in videos" as the teacher, and "fast single-step denoising features" as the student input. The geometric branch learns DPAv3 representations, and the semantic branch learns DINOv2 representations. Instead of running the entire multi-step video generation during inference, only one denoising feature extraction and decouplers are needed to obtain geometric and semantic foresight that can be used by action experts.
4. Detailed explanation of method
4.1 Method overview
The pipeline of S-VAM is: input the current observation $I$ and task description $P$; SVD extracts multi-layer up-sampling features in the first step of denoising; geometric decoupler and semantic decoupler decouple these noisy/entangled features into DPAv3-like and DINOv2-like future representations respectively; Uni-Perceiver combines the two types of foresight with the original diffusion feature Aggregated into compact tokens; diffusion policy outputs action sequences based on these tokens and text embedding.
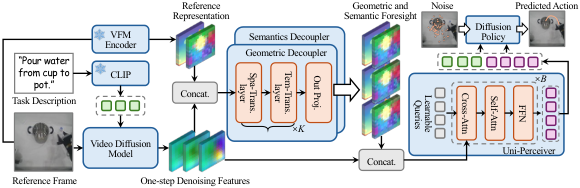
4.2 Method evolution
| stage | form | Improvement motivation |
|---|---|---|
| Direct VLA | Current image/language directly to action. | Missing explicit spatiotemporal foresight, high robot data requirements. |
| VAM with multi-step video generation | The video diffusion model generates future visual plans in multiple steps and then predicts actions. | foresight is high-fidelity, but slow for multi-step denoising inference. |
| One-step VAM | Guiding action with single-step diffusion internal features. | Good real-time performance, but noisy/entangled features. |
| S-VAM | Self-distilling VFM representations of multi-step generated videos into single-step features. | Preserve single-step efficiency while obtaining more stable geometric/semantic future representations. |
4.3 Core design and mathematical derivation
4.3.1 Stable Video Diffusion Basics
$z_s$ is the latent of step $s$, $\epsilon_\theta$ is the noise prediction network, and the conditions are observation frame $I$ and task description $P$. S-VAM does not perform full multi-step sampling at control time, but instead uses first-step denoising features.
4.3.2 VFM teacher target
$\hat{V}$ is SVD multi-step generated video; $\Phi$ is frozen VFM encoder; interpolation is used to align spatial resolution. The paper uses DPAv3 as the geometric teacher and DINOv2 as the semantic teacher.
4.3.3 One-step denoising feature aggregation
$F_l$ is the feature map of the $l$ up-sampling layer, $C_\Sigma=\sum_l C_l$. These characteristics are fast, but inherently noisy and entangled.
4.3.4 Geometric/Semantic decouplers
$\mathcal{S}$ and $\mathcal{T}$ are spatial and temporal transformer layers respectively. Each branch is finally projected back to the corresponding VFM dimension.
The paper emphasizes that the teacher generates videos from the same diffusion trajectory to avoid trajectory misalignment caused by GT future frames.
4.3.5 Uni-Perceiver and diffusion policy
$\mathcal{Q}$ are $N$ learnable latent queries. Cross-attention extracts information from high-dimensional spatiotemporal context, and self-attention models the internal relationships of compact tokens.
$a_j$ is the noisy action of diffusion timestep $j$, $E$ is the task text embedding, and $\epsilon_\phi$ is the action noise prediction network.
4.4 Implementation points
5. Experiment
5.1 Experimental setup
| Project | settings |
|---|---|
| CALVIN | ABC → D: Train in the ABC environment, evaluate in the unseen D environment, and examine generalization on consecutive long-horizon tasks. The indicators are the success rate of the $i$th task and Avg. Len. |
| MetaWorld | 50 Sawyer manipulation tasks, counted by Easy/Middle/Hard. The training set has 50 demonstrations per task. |
| real robot | AgileX Robotics Cobot dual-arm platform, Mobile ALOHA design; 7 DoF per arm and parallel gripper; only uses front camera monocular RGB observations. |
| real tasks | Place-to-Pot, Place-to-Pot (Hard, transparent object), Pour-Water, Lift-Pot. Unified multi-task model, about 50 human demonstrations per task, evaluated on 25 trials per task. |
| Baselines | Direct action learning: RT-1, Diffusion Policy, OpenVLA, CLOVER, $\pi_0$, Spatial Forcing; Predictive methods: SuSIE, VPP, GR-1, Uni-VLA, HiF-VLA, etc. |
| code repository | The official code is provided on the project page: https: //github.com/Haodong-Yan/S-VAM-Code. |
5.2 Main results
CALVIN
| Method | 1st | 2nd | 3rd | 4th | 5th | Avg. Len. |
|---|---|---|---|---|---|---|
| Spatial Forcing | 93.6 | 85.8 | 78.4 | 72.0 | 64.6 | 3.94 |
| VPP | 90.9 | 81.5 | 71.3 | 62.0 | 51.8 | 3.58 |
| Uni-VLA | 95.5 | 85.8 | 74.8 | 66.9 | 56.5 | 3.80 |
| HiF-VLA | 93.5 | 87.4 | 81.4 | 75.9 | 69.4 | 4.08 |
| S-VAM | 95.8 | 90.7 | 83.7 | 77.0 | 68.9 | 4.16 |
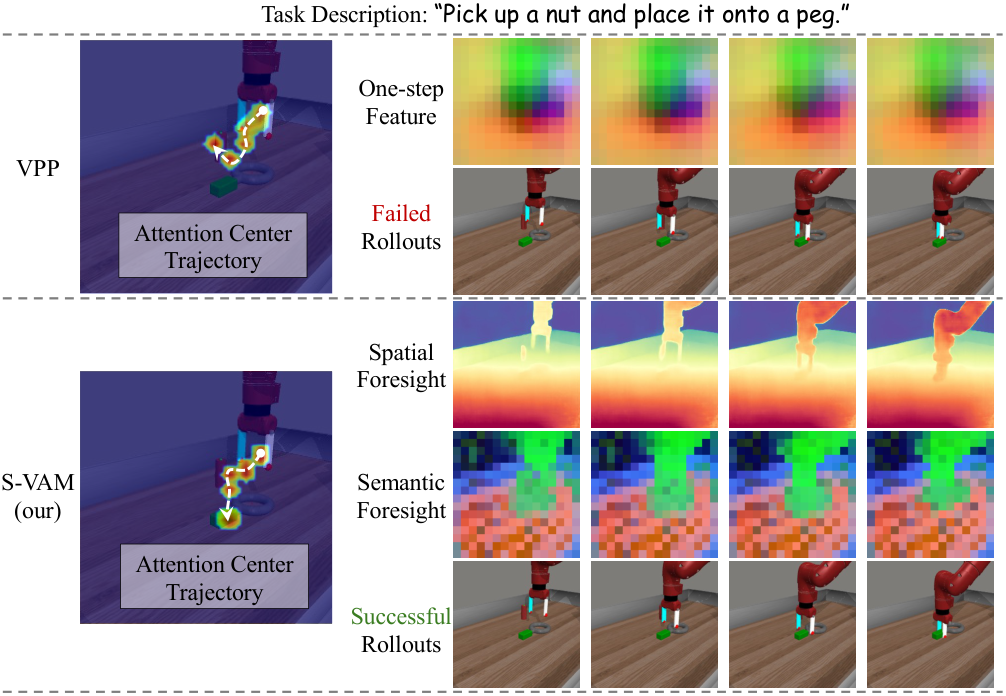
The paper highlights that S-VAM is 0.58 Avg. Len. higher than the direct baseline VPP. In the qualitative graph, VPP's one-step entangled features produce an attention trajectory that deviates from the instructions; S-VAM's decoupled foresight makes the attention trajectory more consistent with the language instructions.

MetaWorld
| Method | Easy | Middle | Hard | Average |
|---|---|---|---|---|
| Spatial Forcing | 0.737 | 0.436 | 0.451 | 0.609 |
| HiF-VLA | 0.729 | 0.364 | 0.404 | 0.577 |
| VPP | 0.818 | 0.493 | 0.526 | 0.682 |
| S-VAM | 0.793 | 0.607 | 0.684 | 0.728 |
The average success rate of S-VAM is 72.8%, and Hard tasks is 68.4%. The paper states that it significantly exceeds VPP's 52.6% on hard tasks. The authors attribute the advantage to decoupled geometric/semantic foresight providing more stable target localization in complex object interactions and fine geometric constraints.
real robot
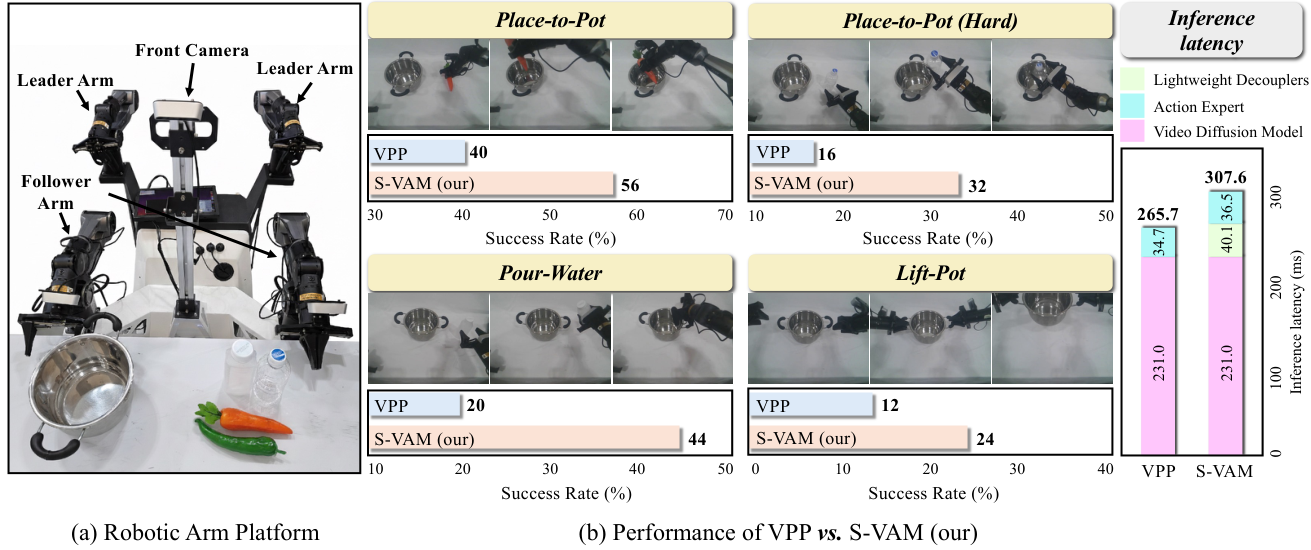
Key details of the real experiment: ~50 demonstrations, 25 trials per task. Place-to-Pot (Hard) involves transparent objects, the VPP success rate is 16%, and S-VAM improves to 32%. The paper explains that the geometric decoupler helps with depth ambiguity on transparent surfaces, and the semantic decoupler helps maintain a consistent representation of transparent objects.
5.3 Ablation experiment
| Variant | 1st | 2nd | 3rd | 4th | 5th | Avg. Len. | purpose |
|---|---|---|---|---|---|---|---|
| w/o Geometric Distillation | 94.1 | 87.1 | 79.3 | 73.5 | 66.5 | 4.01 | Verify geometry foresight effect. |
| w/o Semantic Distillation | 94.0 | 87.1 | 80.4 | 73.2 | 64.1 | 3.99 | Validation semantics foresight's role in object identity consistency. |
| w/o Self-Distillation | 94.2 | 85.2 | 75.9 | 67.8 | 59.0 | 3.82 | Replace the model with GT future frames to self-generate the video teacher. |
| w/o Uni-Perceiver | 94.0 | 84.6 | 74.7 | 65.1 | 53.8 | 3.72 | Verify the necessity of compact token condensation. |
| w/o Original Diffusion Feature | 95.3 | 86.6 | 77.6 | 70.9 | 62.5 | 3.93 | Verify that the original diffusion features provide residual global context. |
| S-VAM Full | 95.8 | 90.7 | 83.7 | 77.0 | 68.9 | 4.16 | Complete model. |
5.4 Supplementary experiment: VFM teacher target selection
| Type | Representation | Avg. Len. | Paper explanation |
|---|---|---|---|
| Semantic | CLIP / SigLIP | 3.72 / 3.77 | Global semantics has scene-level information, but lacks dense patch-level affordance for low-level control. |
| Semantic | DINOv2 / DINOv3 | 4.01 / 3.95 | Dense patch-level representation outperforms CLIP/SigLIP. |
| Geometric | DPAv3 / VGGT | 3.99 / 3.74 | DPAv3 adapts to dynamic video streams; VGGT prefers static scene reconstruction. |
| Motion-aware | VideoMAEv2 / V-JEPA2 | 3.90 / 3.74 | The author believes that current video models are still weaker than specialized image models in fine-grained feature fidelity. |
| Synergistic | SigLIP+DPAv3 / DINOv2+VGGT / DINOv2+DPAv3 | 4.06 / 4.04 / 4.16 | DINOv2's dense semantics complements DPAv3's dynamic geometry. |
6. Analysis and Discussion
6.1 Analysis and explanation of the results given in the paper
- In CALVIN, the author attributes the advantage of S-VAM over VPP to the fact that decoupled geometric and semantic foresight can form a more coherent attention trajectory that is consistent with language instructions.
- Among MetaWorld hard tasks, the author believes that complex object interactions and fine geometric constraints require more dynamic geometry and dense semantic foresight.
- In the real transparent object task, the author clearly explains: the geometric decoupler alleviates the depth ambiguity of transparent surfaces, and the semantic decoupler maintains consistent object representation of transparent objects.
- In VFM target ablation, the author explains that DINOv2 is better than CLIP/SigLIP because dense patch-level representation is more suitable for low-level control; DPAv3 is better than VGGT because DPAv3 is oriented to dynamic video streams.
6.2 Limitations of the author's statement
The Conclusion in the source code does not explicitly list limitation or failure cases, nor does it provide an independent appendix. Therefore, this report does not incorporate the subjective limitations of the report writer. Gaps in reproducibility are only listed in §6.4 according to the published information of the paper.
6.3 Applicable boundaries and discussions clearly stated in the paper
- S-VAM's teacher target relies on SVD's own multi-step generated videos; if the video generation backbone cannot produce a stable future for certain types of scenarios, the self-distilled teacher will also be affected. This point is an applicable premise deduced from the method mechanism, and is not an experimental limitation separately listed by the author.
- The real experiment uses only front-camera monocular RGB observations and is verified on 4 dual-arm tasks.
- The real-time control conclusion is based on the settings of action chunk length 8, RTX 3090 inference, and 307.6 ms forward pass.
6.4 Reproducibility audit
| Project | Status | Description |
|---|---|---|
| Source code structure | Obtained | arXiv e-print contains main.tex, secs/, bib, style and PDF figures. |
| chart | Extracted | All PDF figures have been converted to PNG and placed into figures/. |
| code repository | Found | Project page linked to Haodong-Yan/S-VAM-Code. |
| training configuration | partially complete | The paper gives the number of three-stage training steps and GPU configuration, but does not list the complete hyperparameter table such as batch size and learning rate in LaTeX. |
| Data settings | The main message is clear | CALVIN, MetaWorld, real Cobot demos/trials are all explained. |
| Appendix | No independent appendix | No appendix was found in the source code, so there are no additional proofs, failure cases, or full hyperparameter appendices to incorporate. |