$\pi_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
1. Quick overview of the paper
Difficulty rating:★★★★☆. Need to be familiar with VLA, flow matching action expert, VLM backbone, robot history encoder, world model/subgoal generation, cross-embodiment evaluation and robot experiment evaluation.
Keywords:Robotic Foundation Model, VLA, Context Conditioning, Subgoal Images, Episode Metadata, Cross-Embodiment Transfer。
| Reading positioning issues | Answer |
|---|---|
| What should the paper solve? | The combinatorial generalization ability of the robot foundation model is still weak: the model often requires task-specific fine-tuning, and it is difficult to reuse existing skills in new tasks, new robots, and new environments just by relying on prompts. |
| The author's approach | Expand prompt/context from single language instructions to multi-modal context: subtask instructions, subgoal images, episode metadata, video history, and combined training with dropout. |
| most important results | Seen dexterous tasks often exceed 90% success rate; zero-shot/unseen or unseen robot-task combinations are mostly 60-80%; UR5e shirt folding human experts 90. 9% progress/80. 6% success, $\pi_{0.7}$ is 85. 6% progress/80% success. |
| Things to note when reading | A large number of conclusions in this article come from real robot evaluation diagrams and supplementary explanations, not a single benchmark table; the focus is on how "steerability + diverse context" allows the model to exploit failures, suboptimal data, non-robot data, and specialist rollouts. |
Core contribution list
- Proposed $\pi_{0.7}$.5B parameter VLA, including 4B Gemma3 VLM backbone, MEM-style video history encoder and 860M flow matching action expert.
- Propose a multimodal context conditioning recipe.Context not only includes task description, but also includes next semantic subtask, subgoal images, episode metadata, control mode, etc.
- Leveraging heterogeneous data.Distinguish demonstrations, failures, suboptimal autonomous rollouts, specialist rollouts and non-robot data through metadata, so that multi-quality data can be used uniformly.
- Display emergent capabilities.Includes complex instruction following, cross-embodiment shirt folding, new appliance coaching, combinatorial generalization, and memory tasks.
2. Motivation
2. 1 What problem should be solved?
The paper starts from the general principle of the foundation model: capabilities come from large-scale and diverse data training. Language models can combine knowledge, follow user formats, and perform reasoning, but physical intelligence in robots is still difficult to achieve similar compositional generalization. Already VLA, while getting larger, often still relies on task-specific data or fine-tuning.
2. 2 Limitations of existing methods
- VLA using only language commands:context Insufficient information to express strategy, data quality, desired behavioral styles, or intermediate goals.
- Only train high-quality demonstrations:Data size is limited, and failures, suboptimal autonomous rollouts, or specialist policy rollouts cannot be exploited.
- task-specific specialists:Can be strong on a single task, but each new task requires additional data or fine-tuning.
- The world model generates targets separately:If it cannot be combined with the VLA prompt system, the generated subgoal cannot be stably converted into a control strategy.
2. 3 The solution ideas of this article
The core insight is: if the context is rich enough, the model can distinguish "what task this trajectory is, what strategy is used, success or failure, whether it should be imitated or avoided", thereby turning heterogeneous data into a trainable resource. $\pi_{0.7}$ uses component dropout to allow the model to see different context combinations during training, and can flexibly use language, subgoal image or metadata to steer behavior during inference.
4. Detailed explanation of method
4. 1 Method overview
$\pi_{0.7}$ is the 5B parameter VLA. The input includes observation history $\mathbf{o}_{t-T:t}$ and context $\mathcal{C}_t$. observation includes multi-camera image $\mathbf{I}_t^i$ and joint status $\mathbf{q}_t$; context can include language command, next semantic subtask, subgoal image, episode metadata, control mode, etc. The output is action chunk $\mathbf{a}_{t:t+H}$. Usually only shorter sub-segments are executed and then re-planned.
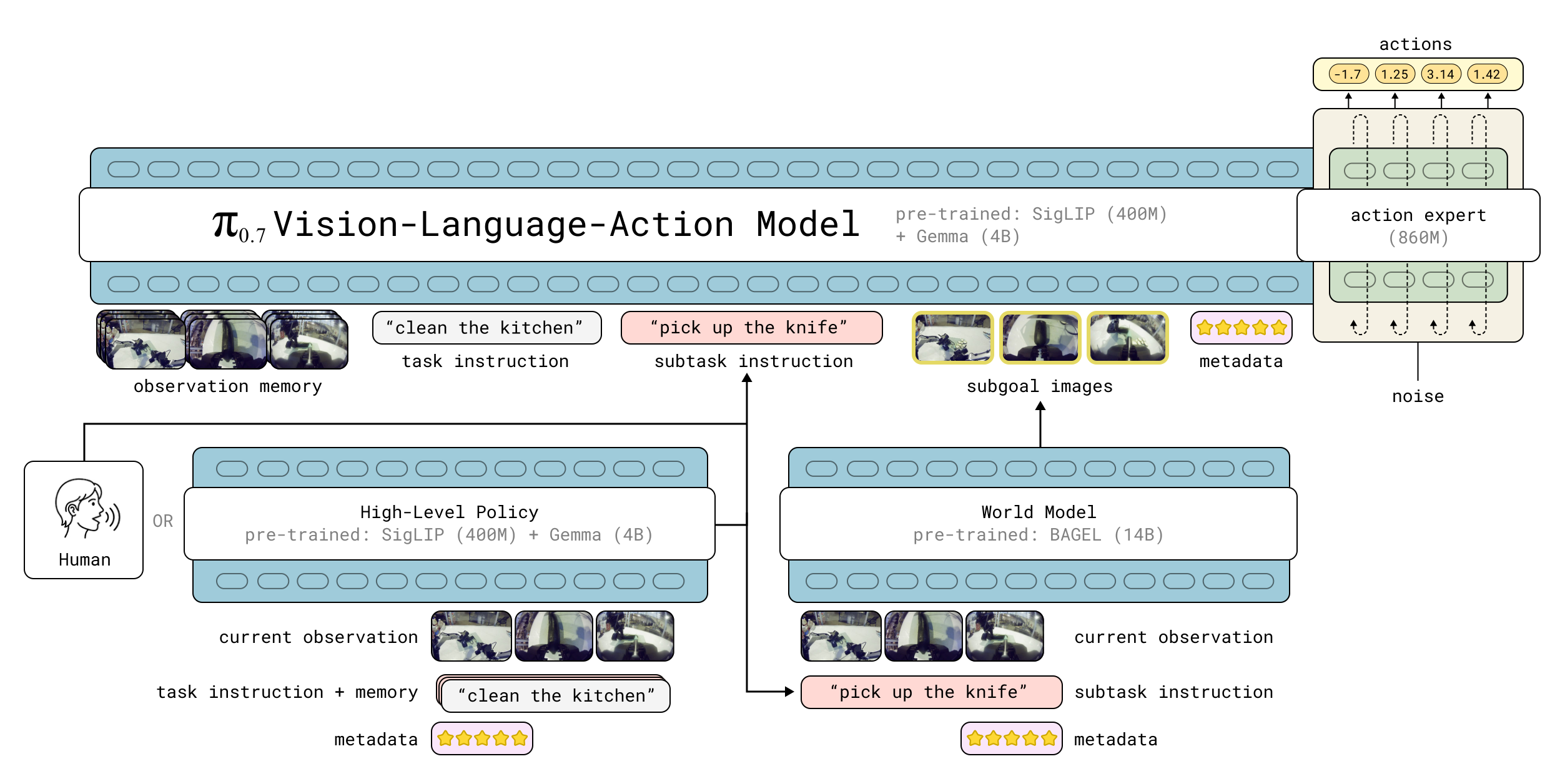
4. 2 Method evolution
| stage | form | Improvement motivation |
|---|---|---|
| $\pi_0$ / prior VLA | Short text task instructions + observation history → action chunk. | It can control multitasking, but context cannot describe strategy and data quality. |
| MEM-style VLA | Add video history encoder to handle long-term observations. | Supports tasks that require memory. |
| $\pi_{0.7}$ | Multimodal context: subtask, metadata, subgoal images, history, control mode. | Allow models to be steered, utilize heterogeneous data, and combine existing skills to solve new tasks. |
4. 3 Core design and mathematical derivation
$\mathcal{D}$ is the training data set; $\mathbf{o}_{t-T:t}$ is historical observation; $\mathcal{C}_t$ is context; $\mathbf{a}_{t:t+H}$ is future action chunk. The paper explains that flow matching action expert actually optimizes the approximate lower bound instead of the closed log-likelihood.
4.3.1 Subtask instructions
In addition to the overall task description $\ell_t$, the model also receives higher-level text $\hat{\ell}_t$ representing the next semantic subtask. For example, instead of just saying "clean the kitchen", you can also tell the model "now pick up the plate and put it in the sink". This allows step-by-step verbal coaching of the model with human or high-level semantic policy during inference.
4.3.2 Subgoal images
Subgoal image tells the model the goal state in a visual form. The paper uses a lightweight world model based on the BAGEL image generation model to generate subgoal images. The supplementary material explains that the world model uses 7B LLM backbone and 7B generation backbone; ViT input is resized to 448x336, and VAE input is resized to 512x384; subgoal is generated every $\Delta=4$ seconds during inference.

4.3.3 Episode metadata
The role of episode metadata is to let the model know the source, quality, strategy or success of this trajectory. In this way, the model can take advantage of lower-quality demonstrations, failures, autonomous data from prior models, and RL/SFT specialist rollouts, instead of relying only on high-quality human demonstrations. Without metadata, it is difficult for the model to distinguish between "high-quality behavior that should be imitated" and "failure/suboptimal behavior that should be avoided. "
4.3.4 Architecture and knowledge insulation
The model backbone is initialized from Gemma3 4B VLM, where the vision encoder is about 400M. Actions are generated by 860M flow matching action expert. The paper follows the knowledge insulation recipe: the VLM backbone is trained with discrete cross-entropy of FAST tokens; the action expert attends to the backbone activation, but the gradient of the action expert is not transmitted back to the VLM backbone, thus stabilizing the training.
4. 4 Implementation points
5. Experiment
5. 1 Experimental setup
| category | set up |
|---|---|
| Robot platform | A variety of robots, including mobile/static/single-arm/bimanual systems. The figure shows the experimental robot collection. |
| Task type | espresso, box building, laundry folding, peanut butter sandwich, turn shirt inside-out, drive through door, zucchini slicing, peeling fruits/vegetables, take out trash, mug swapping, find object, etc. |
| Review topic | out-of-the-box dexterity、instruction following、cross-embodiment transfer、compositional task generalization。 |
| Baselines | prior $\pi_0$ models、task-specific RL/SFT specialists、human teleoperators、ablations without eval data/metadata。 |
| Supplementary Rating | The supplementary materials provide a scoring rubric for each task. For example, espresso needs to complete grinding/powdering/portafilter/extraction/moving cups, and take out trash can score up to 12 points. |
5. 2 Main results
Out-of-the-box dexterity
Thesis report $\pi_{0.7}$ achieves performance close to that of task-specific RL/SFT specialists on tasks such as espresso, box building, laundry, etc. directly out of the box, and exceeds specialists on the throughput of laundry and box building. The authors also report that both "no eval data" and "no metadata" ablations are significantly weaker than the full model on the task, indicating that eval rollouts and metadata are critical to utilizing mixed-quality data.
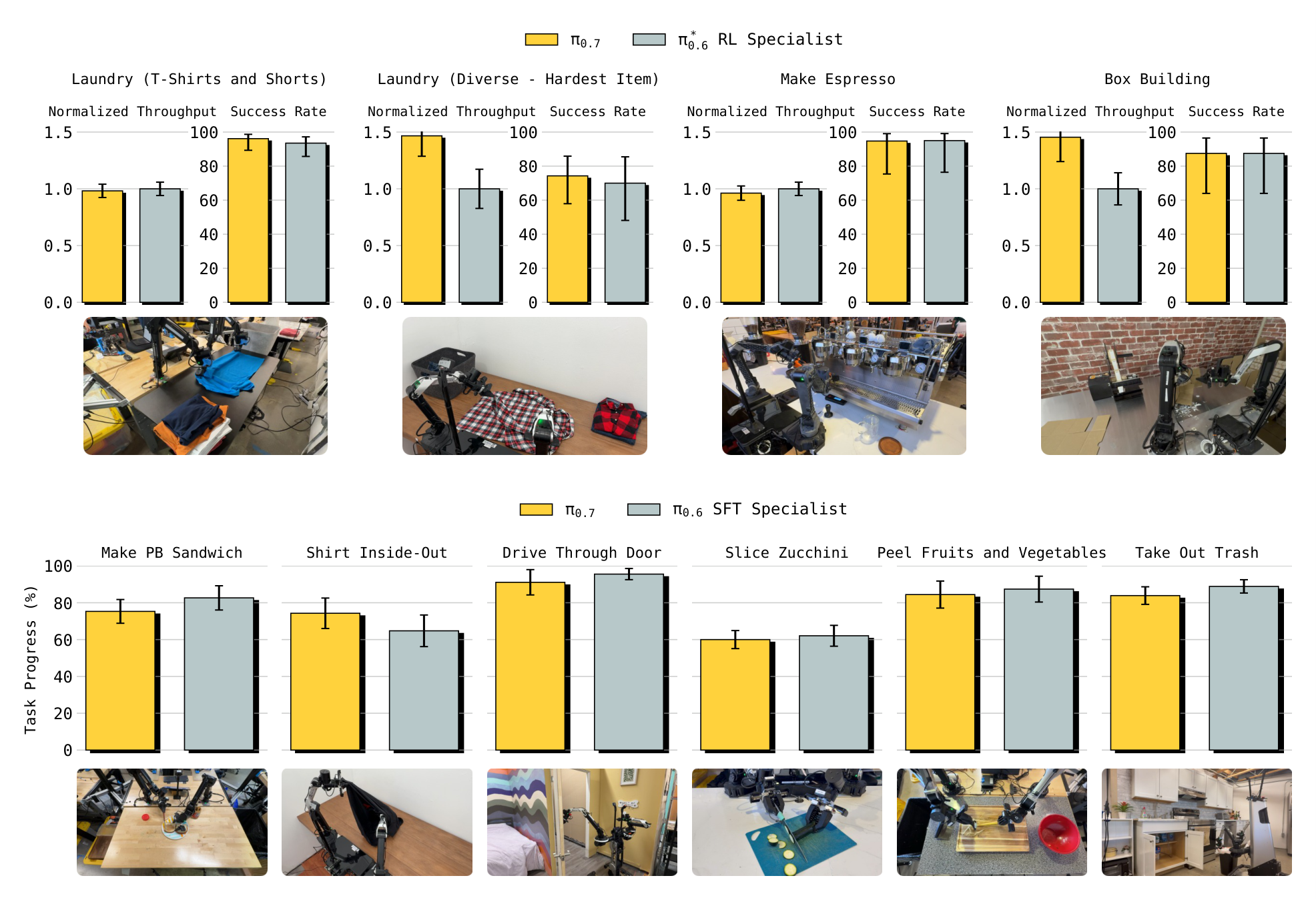
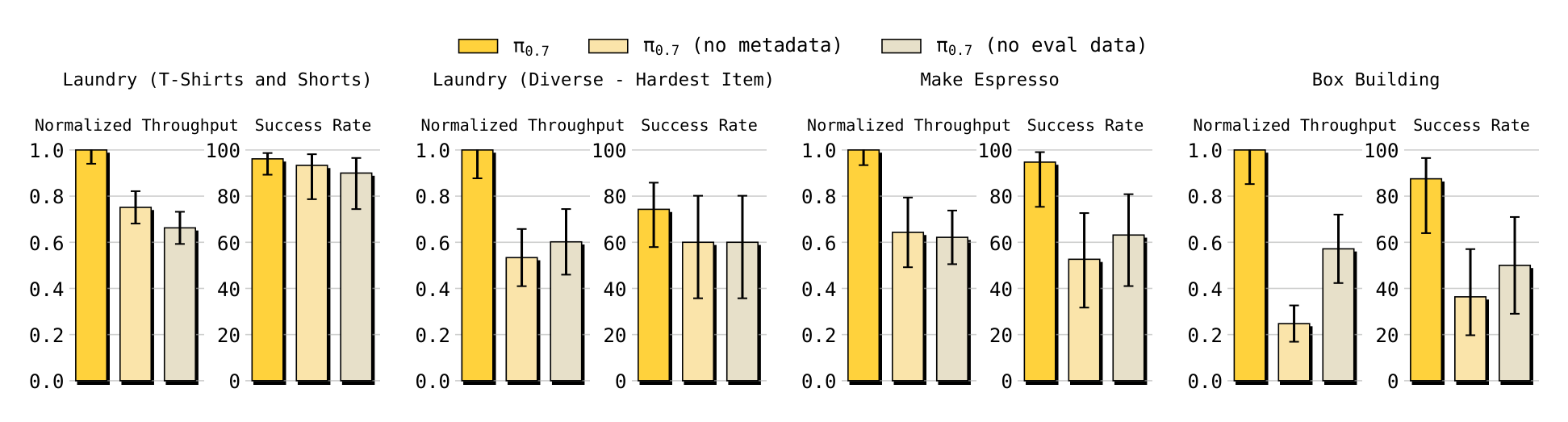
Instruction following
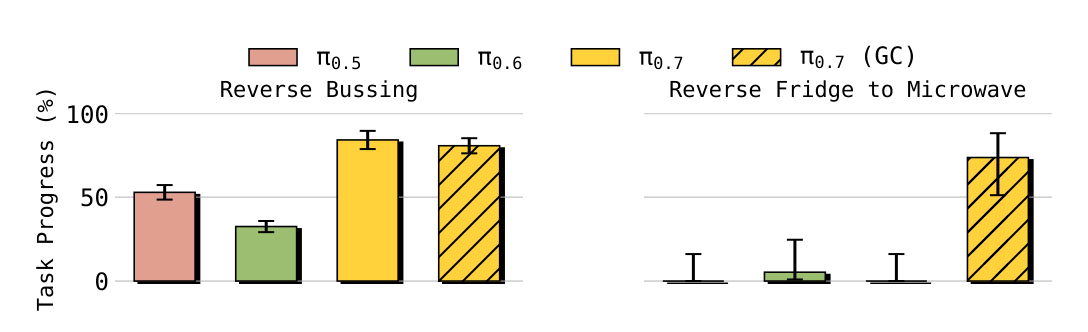
The paper tests open-ended instruction, referral instruction, reverse tasks and tasks that require memory. Reverse Bussing requires placing trash/dishes in a position opposite to the offset of the data set; Reverse Fridge to Microwave requires placing food from the microwave back to the fridge. The results show that $\pi_{0.7}$ is significantly better at overcoming dataset bias than prior models; for Reverse Fridge to Microwave, using the GC version of generated subgoal images is critical to success.

Cross-embodiment transfer
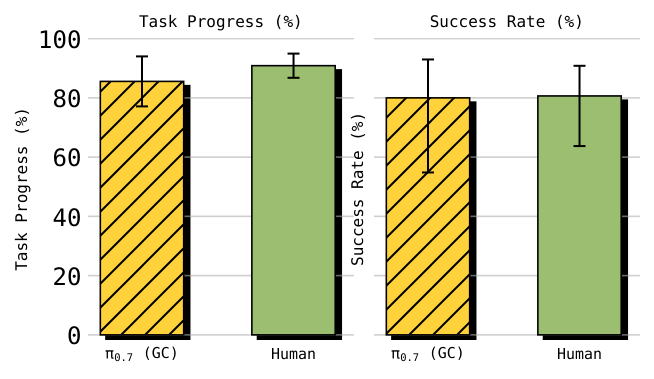
When the target robot does not have training data for the task, $\pi_{0.7}$ displays zero-shot transfer. In the supplementary human control experiment, 10 top experienced operators (average experience of all robot platforms are about 375 hours) performed a total of 30 trials on UR5e shirt folding. Human achieved 90. 9% task progress and 80. 6% success; $\pi_{0.7}$ (GC) achieved 85. 6% progress and 80% success.
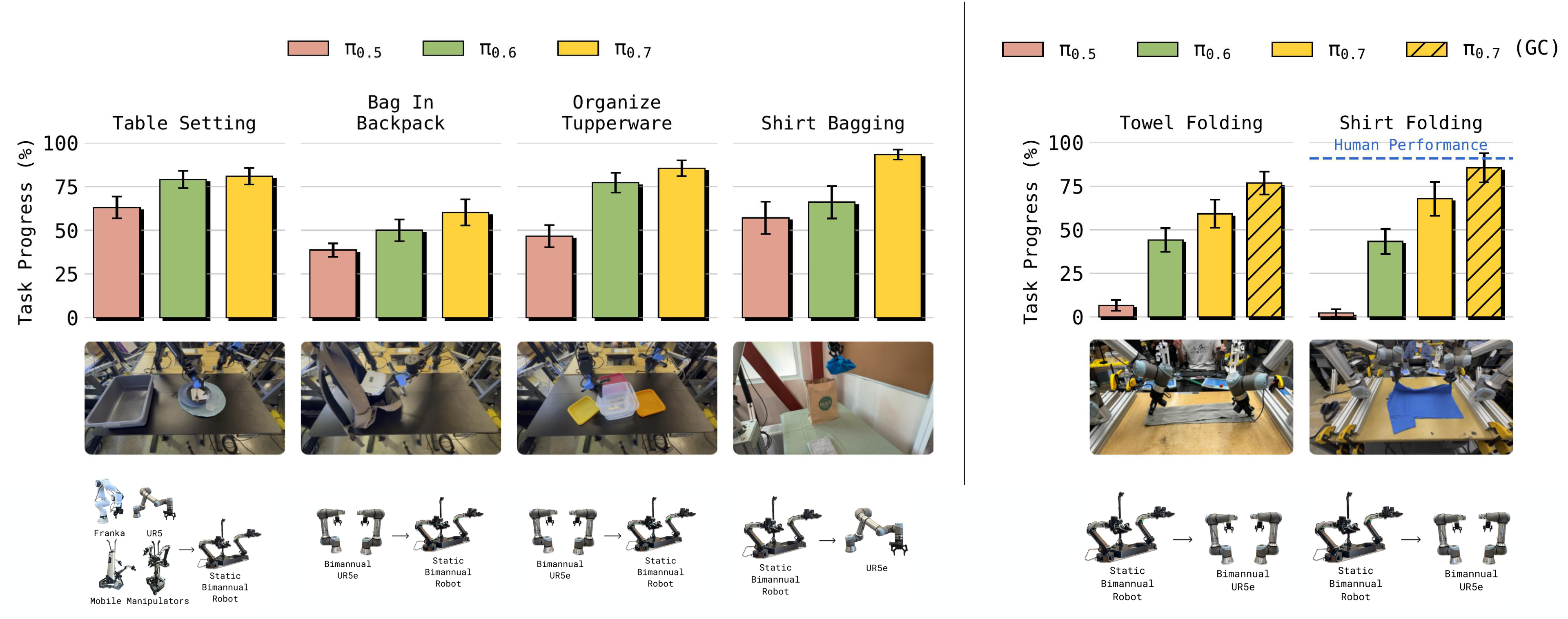
Compositional task generalization and coaching
The paper shows that users can guide the model to complete new long-horizon tasks through verbal coaching, such as putting sweet potatoes into an air fryer. The author takes this as an example of portfolio generalization: instead of collecting action data separately for each new task, existing skill sets are called upon through prompts, subgoals, and step-by-step coaching.

5. 3 Ablation experiment
| ablate | Verification purpose | Paper conclusion |
|---|---|---|
| No eval data | By removing autonomous evaluation episodes, strong RL/specialist policy rollouts cannot be distilled. | Weaker than the full model on $\pi_*^{0.6}$ release tasks. |
| No metadata | The context does not contain episode metadata and the model cannot differentiate between data quality/policy. | Weaker than the full model on all relevant tasks, indicating that metadata is critical for mixed-quality data. |
| Joint vs EE control | Compare action space in cross-embodiment. | EE control has no obvious advantages, and the main experiment uses joint-space control. |
| GC vs non-GC | Check generated subgoal image conditioning. | The GC is a critical component in tasks such as Reverse Fridge to Microwave and cross-embodiment shirt folding. |
5. 4 Supplementary experiment and scoring details
The supplementary materials give detailed task scoring rubrics, covering laundry, espresso, box building, peanut butter sandwich, inside-out shirt, drive through door, cut zucchini, peel fruits/vegetables, take out trash, swap mugs, find object, etc. Instead of binary successes, many tasks are scored by subgoals, such as taking out trash for up to 12 points, and peanut butter sandwich for up to 9 points.
6. Analysis and Discussion
6. 1 Analysis and explanation of the results given in the paper
- The author believes that the complete model is stronger than no metadata/no eval data because metadata allows the model to distinguish imitable and non-imitable behaviors from mixed-quality data.
- The improvement in Instruction following is interpreted as the model placing more emphasis on instructions and therefore overcoming the common directional bias in the data set.
- The success of Cross-embodiment comes from the model's ability to change strategies based on prompt/context, rather than just reproducing the source robot's movement trajectory.
- The function of Subgoal images is to convert web/non-robot/image-generation knowledge into VLA usable visual targets.
6. 2 Limitations of the author's statement
Discussion clearly states that zero-shot generalization has a lower success rate than in-distribution tasks. Seen tasks tend to exceed 90%, while unseen tasks or unseen task-robot combinations tend to be around 60-80%. The authors also point out that in such a large and diverse data set, it is difficult to rigorously determine which tasks are truly unseen, because the relevant skills may exist in the form of different labels or other task sub-behaviors.
6. 3 Applicable boundaries and future work
- Applicable boundaries:The ability of $\pi_{0.7}$ relies on the coverage of combinable skills in the training data and whether prompt/context can accurately specify the strategy.
- Inference boundaries:Subgoal image generation is still slow, and the paper uses asynchronous generation to alleviate it, rather than completely real-time synchronous generation.
- Future work:The author proposes that model steerability can be used to learn more efficiently on test tasks, such as through more detailed language coaching or autonomous reinforcement learning.
6. 4 Reproducibility audit
| project | state | illustrate |
|---|---|---|
| Source code and PDF | Obtained | arXiv e-print, abs, and PDF are all downloaded successfully. |
| chart | Extracted | 22 PDF figures have been converted to PNG and the report selects key figures for embedding. |
| Model structure | clearer | 5B, 4B VLM, 860M action expert, MEM encoder, BAGEL world model and other information are clear. |
| Training hyperparameters | incomplete | The paper provides training recipes and inference optimization, but does not provide complete batch size, learning rate and other recurrence experiment tables. |
| Dataset | Well described but not directly reproducible | The tasks and scoring details are rich, but the training data size, complete data list and downloadable data are not fully given in the source code. |
| code repository | No explicit GitHub found | The paper provides a project page, but the official GitHub repository is not specified in the source code/abs. |