$\pi_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
1. 论文速览
难度评级:★★★★☆。需要熟悉 VLA、flow matching action expert、VLM backbone、robot history encoder、world model/subgoal generation、cross-embodiment evaluation 和机器人实验评价。
关键词:Robotic Foundation Model, VLA, Context Conditioning, Subgoal Images, Episode Metadata, Cross-Embodiment Transfer。
| 阅读定位问题 | 答案 |
|---|---|
| 论文要解决什么 | 机器人 foundation model 的组合泛化能力仍弱:模型往往需要 task-specific fine-tuning,难以仅靠 prompt 在新任务、新机器人、新环境中复用已有技能。 |
| 作者的方法抓手 | 把 prompt/context 从单一语言指令扩展为多模态上下文:subtask instructions、subgoal images、episode metadata、video history,以及可 dropout 的组合训练。 |
| 最重要的结果 | seen dexterous tasks 常超过 90% 成功率;zero-shot/unseen 或 unseen robot-task combinations 多在 60-80%;UR5e shirt folding 人类专家 90.9% progress/80.6% success,$\pi_{0.7}$ 为 85.6% progress/80% success。 |
| 阅读时要注意的点 | 本文大量结论来自真实机器人评估图和补充说明,不是单一 benchmark 表格;重点是“steerability + diverse context”如何让模型利用失败、次优数据、非机器人数据和 specialist rollouts。 |
核心贡献清单
- 提出 $\pi_{0.7}$。5B 参数 VLA,包含 4B Gemma3 VLM backbone、MEM-style video history encoder 和 860M flow matching action expert。
- 提出多模态 context conditioning recipe。context 不仅有 task description,还包括 next semantic subtask、subgoal images、episode metadata、control mode 等。
- 利用 heterogeneous data。通过 metadata 区分 demonstrations、failures、suboptimal autonomous rollouts、specialist rollouts 和 non-robot data,使多质量数据可被统一利用。
- 展示 emergent capabilities。包括复杂指令跟随、跨 embodiment shirt folding、new appliance coaching、组合泛化和 memory tasks。
2. 动机
2.1 要解决什么问题
论文从 foundation model 的通用原则出发:能力来自大规模、多样化数据训练。语言模型能组合知识、遵循用户格式、进行推理,但机器人中的 physical intelligence 还难以做到类似的 compositional generalization。已有 VLA 虽然变大,但通常仍依赖任务专用数据或 fine-tuning。
2.2 已有方法的局限
- 只用语言指令的 VLA:context 信息不足,难以表达策略、数据质量、期望行为风格或中间目标。
- 只训练高质量 demonstrations:数据规模受限,也不能利用 failures、suboptimal autonomous rollouts 或 specialist policy rollouts。
- task-specific specialists:可在单任务上强,但每个新任务都需要额外数据或 fine-tuning。
- 世界模型单独生成目标:若不能和 VLA prompt 体系结合,生成的 subgoal 无法稳定转化为控制策略。
2.3 本文的解决思路
核心 insight 是:如果 context 足够丰富,模型就能区分“这条轨迹是什么任务、用什么策略、成功还是失败、应该模仿还是避免”,从而把 heterogeneous data 变成可训练资源。$\pi_{0.7}$ 通过 component dropout 让模型在训练时见到不同 context 组合,推理时可灵活用语言、subgoal image 或 metadata 来 steer 行为。
4. 方法详解
4.1 方法概览
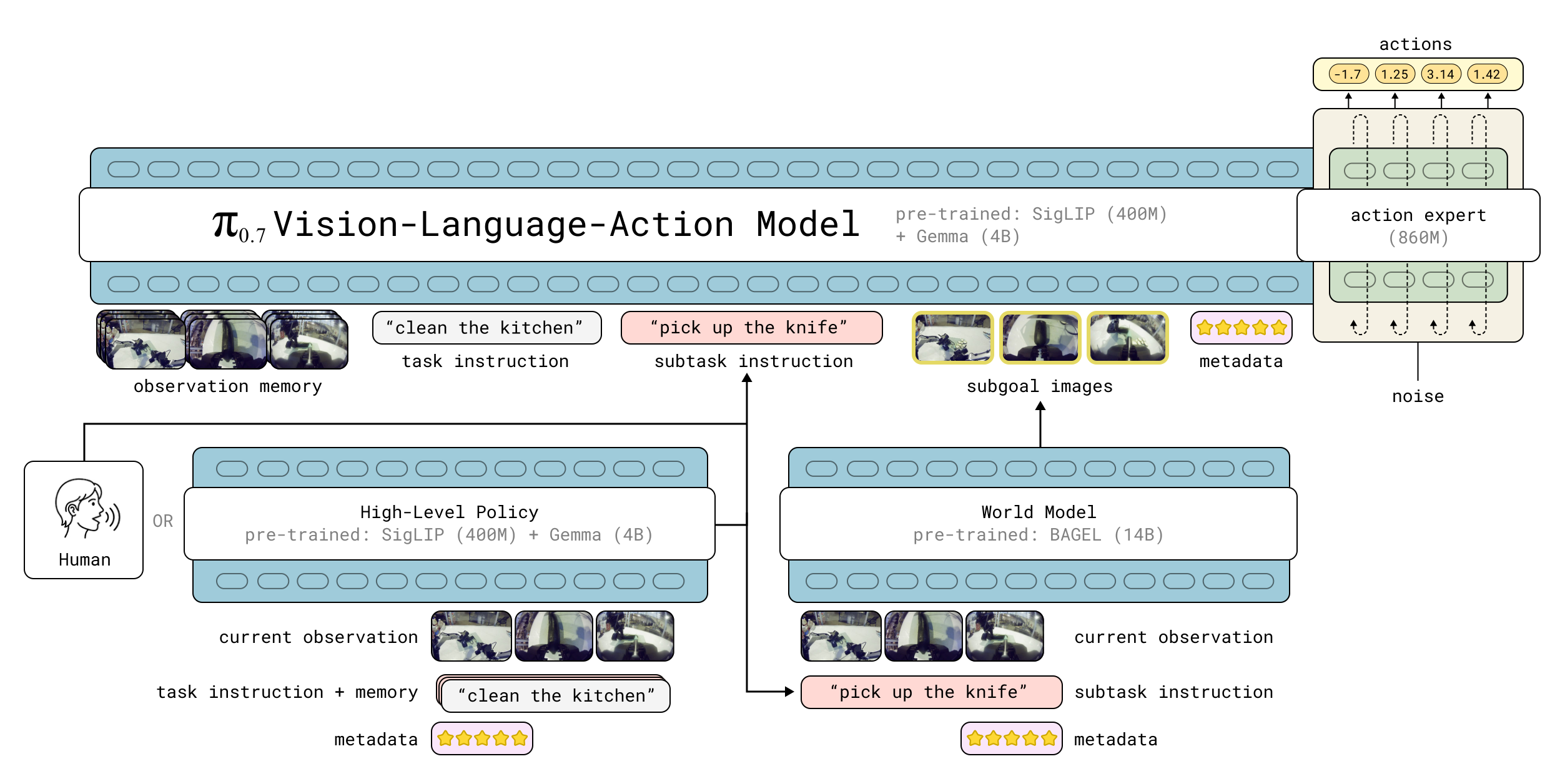
$\pi_{0.7}$ 是 5B 参数 VLA。输入包括 observation history $\mathbf{o}_{t-T:t}$ 和 context $\mathcal{C}_t$。observation 包含多相机图像 $\mathbf{I}_t^i$ 与关节状态 $\mathbf{q}_t$;context 可包含 language command、next semantic subtask、subgoal image、episode metadata、control mode 等。输出是 action chunk $\mathbf{a}_{t:t+H}$,通常只执行较短子段再重新规划。
4.2 方法演变脉络
| 阶段 | 形式 | 改进动机 |
|---|---|---|
| $\pi_0$ / prior VLA | 短文本任务指令 + observation history → action chunk。 | 能做多任务控制,但 context 不能描述策略和数据质量。 |
| MEM-style VLA | 加入 video history encoder 处理长期观察。 | 支持需要 memory 的任务。 |
| $\pi_{0.7}$ | 多模态 context:subtask、metadata、subgoal images、history、control mode。 | 让模型能被 steer,能利用 heterogeneous data,并组合已有技能解决新任务。 |
4.3 核心设计与数学推导
$\mathcal{D}$ 是训练数据集;$\mathbf{o}_{t-T:t}$ 是历史观察;$\mathcal{C}_t$ 是 context;$\mathbf{a}_{t:t+H}$ 是未来 action chunk。论文说明 flow matching action expert 实际优化的是近似 lower bound,而不是闭式 log-likelihood。
4.3.1 Subtask instructions
除了 overall task description $\ell_t$,模型还接收 higher-level text $\hat{\ell}_t$ 表示 next semantic subtask。例如不是只说“clean the kitchen”,还可以告诉模型“now pick up the plate and put it in the sink”。推理时这允许 human 或 high-level semantic policy 对模型进行 step-by-step verbal coaching。
4.3.2 Subgoal images
Subgoal image 用视觉形式告诉模型目标状态。论文使用基于 BAGEL image generation model 的 lightweight world model 产生 subgoal images。补充材料说明该 world model 使用 7B LLM backbone 和 7B generation backbone;ViT 输入 resize 到 448x336,VAE 输入 resize 到 512x384;推理时每 $\Delta=4$ 秒再生成一次 subgoal。

4.3.3 Episode metadata
Episode metadata 的作用是让模型知道这条轨迹的来源、质量、策略或成功情况。这样模型可以利用 lower-quality demonstrations、failures、autonomous data from prior models、RL/SFT specialist rollouts,而不是只能依赖高质量 human demonstrations。没有 metadata 时,模型难以区分“应模仿的高质量行为”和“应避免的失败/次优行为”。
4.3.4 Architecture and knowledge insulation
模型 backbone 初始化自 Gemma3 4B VLM,其中 vision encoder 约 400M。动作由 860M flow matching action expert 产生。论文沿用 knowledge insulation recipe:VLM backbone 用 FAST tokens 的离散 cross-entropy 训练;action expert attend 到 backbone 激活,但 action expert 的梯度不回传到 VLM backbone,从而稳定训练。
4.4 实现要点
5. 实验
5.1 实验设置
| 类别 | 设置 |
|---|---|
| 机器人平台 | 多种机器人,包括 mobile/static/single-arm/bimanual systems。图中展示了实验机器人集合。 |
| 任务类型 | espresso、box building、laundry folding、peanut butter sandwich、turn shirt inside-out、drive through door、zucchini slicing、peeling fruits/vegetables、take out trash、mug swapping、find object 等。 |
| 评价主题 | out-of-the-box dexterity、instruction following、cross-embodiment transfer、compositional task generalization。 |
| Baselines | prior $\pi_0$ models、task-specific RL/SFT specialists、human teleoperators、ablations without eval data/metadata。 |
| 补充评分 | 补充材料给出各任务 scoring rubric,例如 espresso 需完成研磨/压粉/装 portafilter/萃取/移动杯子,take out trash 最高 12 分。 |
5.2 主要结果
Out-of-the-box dexterity
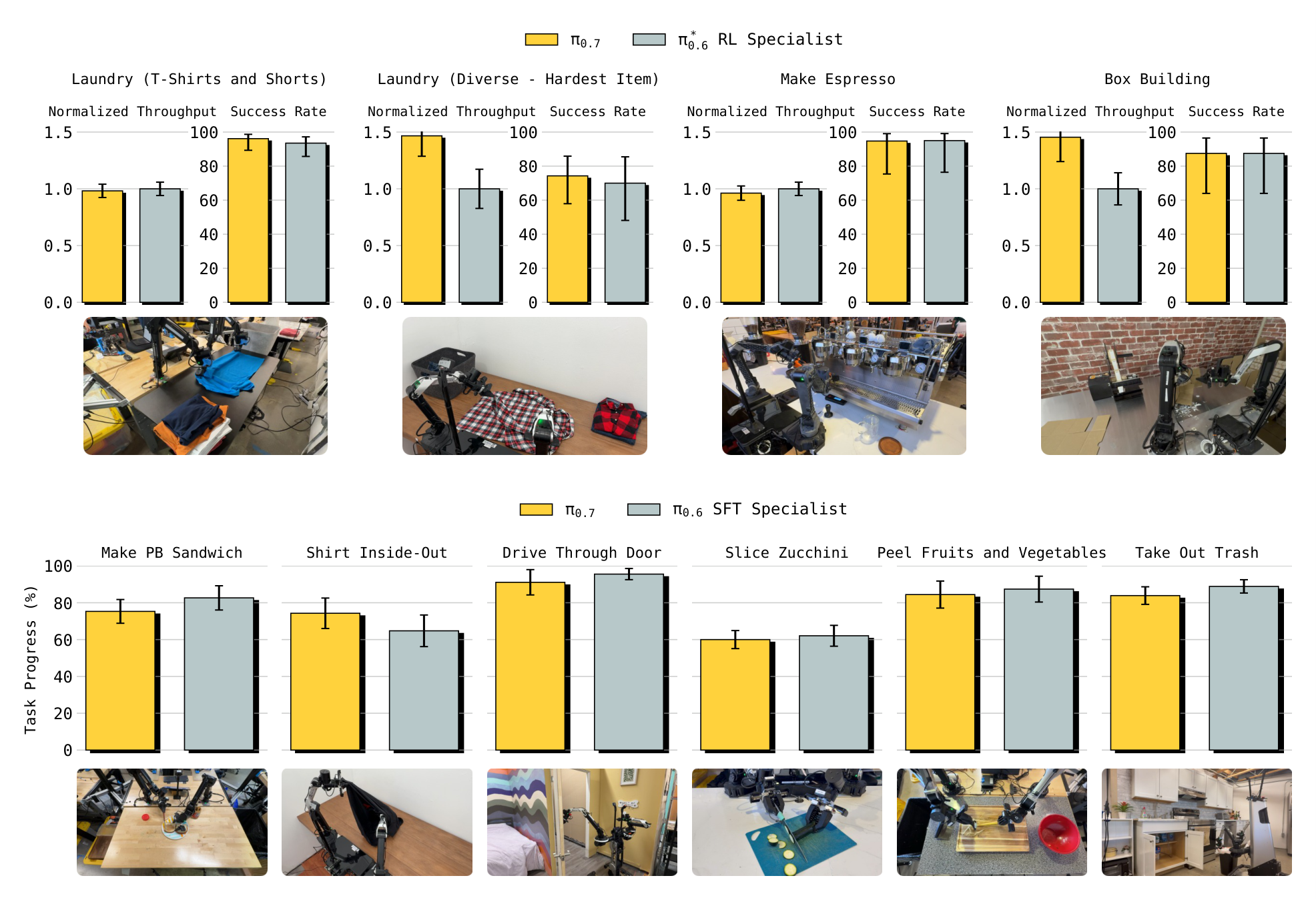
论文报告 $\pi_{0.7}$ 在 espresso、box building、laundry 等任务上直接 out of the box 达到与任务专用 RL/SFT specialists 接近的表现,并在 laundry 与 box building 的 throughput 上超过 specialists。作者还报告“no eval data”和“no metadata”消融在任务上均明显弱于完整模型,说明 eval rollouts 与 metadata 对利用 mixed-quality data 关键。
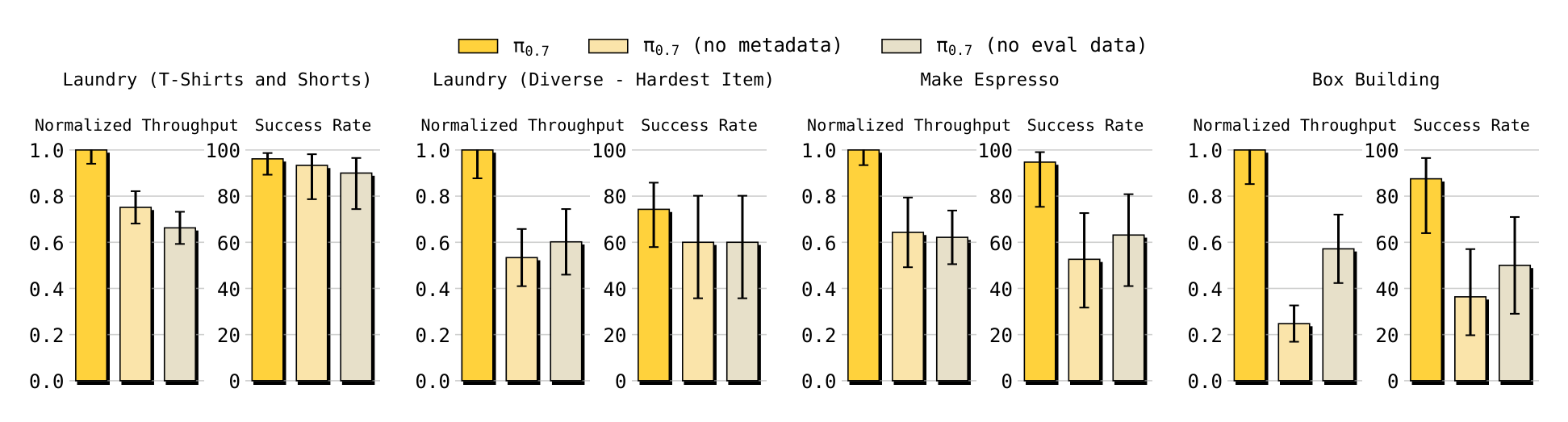
Instruction following
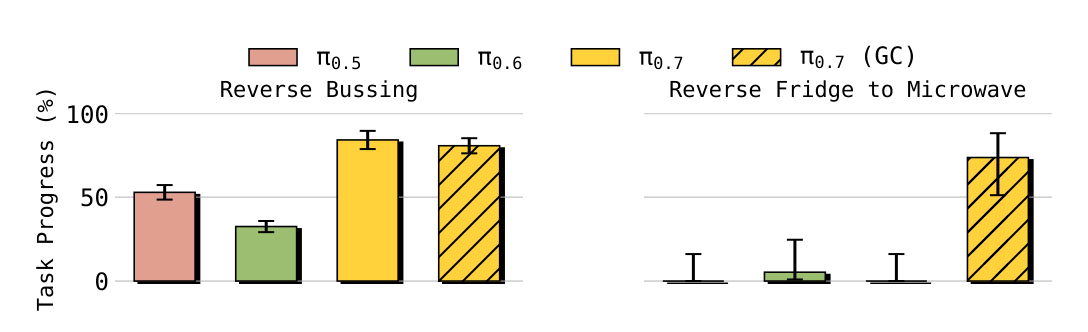
论文测试了 open-ended instruction、referential instruction、reverse tasks 和需要 memory 的任务。Reverse Bussing 要求把 trash/dishes 放到与数据集偏置相反的位置;Reverse Fridge to Microwave 要求把食物从 microwave 放回 fridge。结果显示 $\pi_{0.7}$ 相比 prior models 明显更能克服 dataset bias;对 Reverse Fridge to Microwave,使用 generated subgoal images 的 GC 版本对成功至关重要。

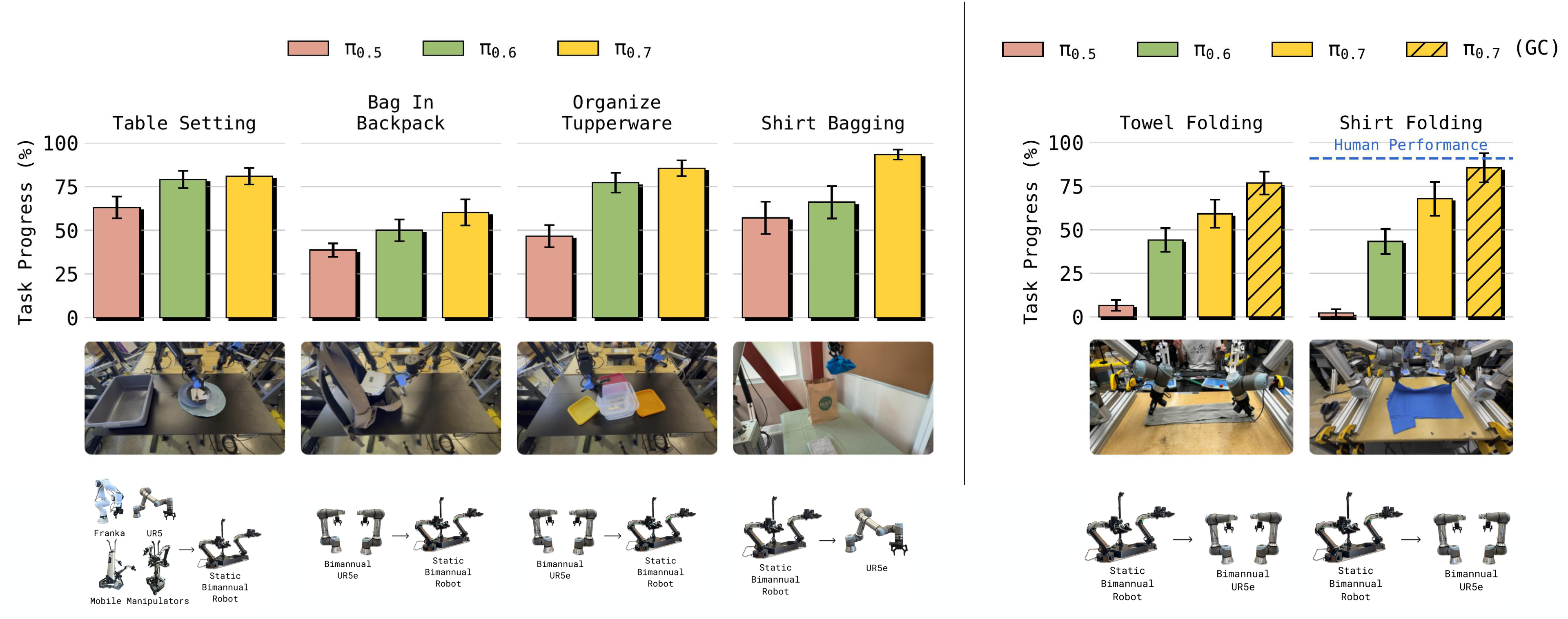
Cross-embodiment transfer
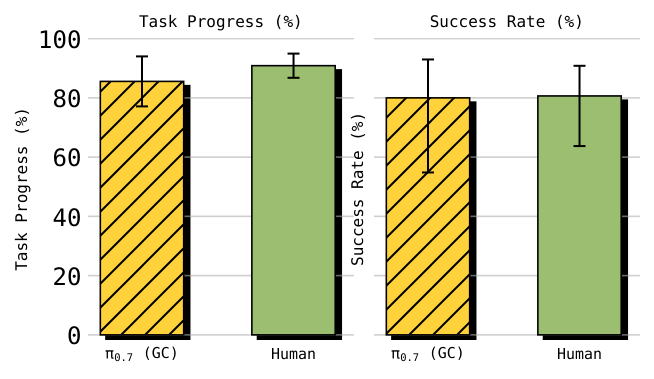
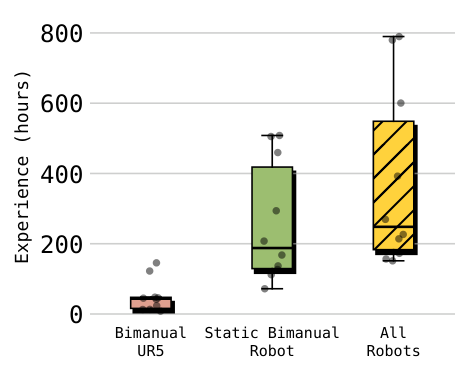
在目标机器人没有该任务训练数据的情况下,$\pi_{0.7}$ 展示 zero-shot transfer。补充的人类对照实验中,10 名顶尖经验操作者(平均所有机器人平台约 375 小时经验)在 UR5e shirt folding 上共 30 trials,human 达到 90.9% task progress 与 80.6% success;$\pi_{0.7}$ (GC) 达到 85.6% progress 与 80% success。
Compositional task generalization and coaching
论文展示用户可通过 verbal coaching 指导模型完成新的 long-horizon tasks,例如把 sweet potato 放入 air fryer。作者将此作为组合泛化的例子:不再为每个新任务单独收集 action data,而是通过 prompt、subgoal 和逐步 coaching 调用已有技能组合。

5.3 消融实验
| 消融 | 验证目的 | 论文结论 |
|---|---|---|
| No eval data | 移除 autonomous evaluation episodes,不能蒸馏强 RL/specialist policy rollouts。 | 在 $\pi_*^{0.6}$ release tasks 上弱于完整模型。 |
| No metadata | context 不包含 episode metadata,模型无法区分数据质量/策略。 | 在所有相关任务上弱于完整模型,说明 metadata 对 mixed-quality data 关键。 |
| Joint vs EE control | cross-embodiment 中比较 action space。 | EE control 没有明显优势,主实验采用 joint-space control。 |
| GC vs non-GC | 检查 generated subgoal image conditioning。 | 在 Reverse Fridge to Microwave 和 cross-embodiment shirt folding 等任务上 GC 是关键组件。 |
5.4 补充实验与评分细节
补充材料详细给出任务 scoring rubric,覆盖 laundry、espresso、box building、peanut butter sandwich、inside-out shirt、drive through door、cut zucchini、peel fruits/vegetables、take out trash、swap mugs、find object 等。很多任务不是二元成功,而是按子目标计分,例如 take out trash 最高 12 分,peanut butter sandwich 最高 9 分。
6. 分析与讨论
6.1 论文已给出的结果分析与解释
- 作者认为完整模型强于 no metadata/no eval data,是因为 metadata 让模型可以从 mixed-quality data 中区分可模仿和不可模仿的行为。
- Instruction following 的提升被解释为模型更重视指令,因此能克服数据集中的常见方向性偏置。
- Cross-embodiment 的成功来自模型能根据 prompt/context 改变策略,而不只是复现源机器人动作轨迹。
- Subgoal images 的作用是把 web/non-robot/image-generation knowledge 转化成 VLA 可利用的视觉目标。
6.2 作者自述的局限性
Discussion 明确指出:zero-shot generalization 的成功率低于 in-distribution tasks。seen tasks 往往超过 90%,而 unseen tasks 或 unseen task-robot combinations 多在 60-80%。作者还指出,在如此大而多样的数据集中,很难严格判定哪些任务真正 unseen,因为相关技能可能以不同标签或其他任务子行为形式存在。
6.3 适用边界与未来工作
- 适用边界:$\pi_{0.7}$ 的能力依赖训练数据中可组合技能的覆盖,以及 prompt/context 能否准确指定策略。
- 推理边界:subgoal image generation 仍较慢,论文用异步生成缓解,而不是完全实时同步生成。
- 未来工作:作者提出可利用模型 steerability 在测试任务上更高效学习,例如通过更详细 language coaching 或 autonomous reinforcement learning。
6.4 可复现性审计
| 项目 | 状态 | 说明 |
|---|---|---|
| 源码与 PDF | 已获取 | arXiv e-print、abs、PDF 均下载成功。 |
| 图表 | 已提取 | 22 个 PDF 图已转换为 PNG,报告选取关键图嵌入。 |
| 模型结构 | 较明确 | 5B、4B VLM、860M action expert、MEM encoder、BAGEL world model 等信息明确。 |
| 训练超参数 | 不完整 | 论文给出训练 recipe 和推理优化,但未提供完整 batch size、learning rate 等复现实验表。 |
| 数据集 | 描述充分但不可直接复现 | 任务和评分细节丰富,但训练数据规模、完整数据清单和可下载数据未在源码中完整给出。 |
| 代码仓库 | 未发现明确 GitHub | 论文提供 project page,但源码/abs 中未明确官方 GitHub 仓库。 |